ExecutorServiceを準備するnewWorkStealingPoolメソッドを理解してみましょう。

このスレッド プールは特別です。その行動は仕事を「盗む」という考えに基づいています。
タスクはキューに入れられ、プロセッサー間で分散されます。ただし、プロセッサがビジー状態の場合、空いている別のプロセッサがそのプロセッサからタスクを盗んで実行することができます。この形式は、マルチスレッド アプリケーションでの競合を減らすために Java に導入されました。これは、フォーク/結合フレームワークに基づいて構築されています。
フォーク/ジョイン
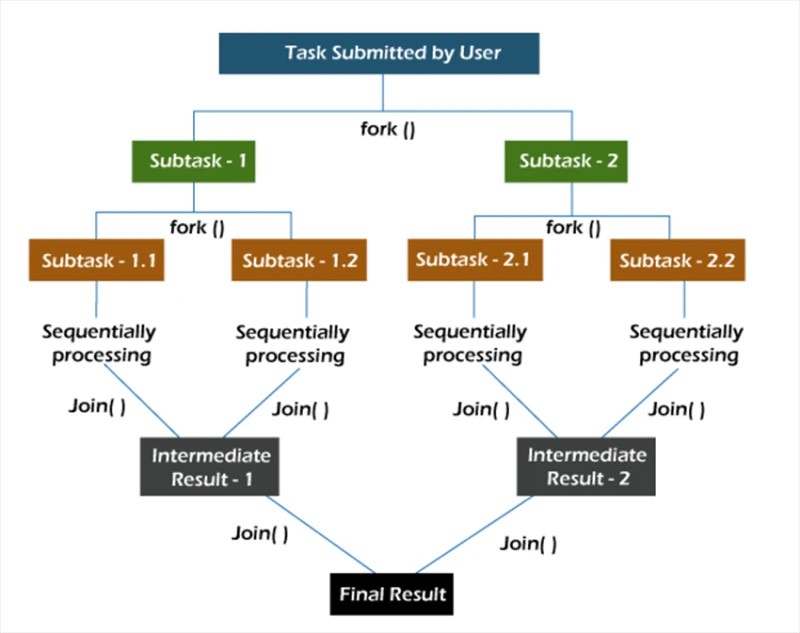
フォーク/ジョインフレームワークでは、タスクは再帰的に分解されます。つまり、タスクはサブタスクに分割されます。次に、サブタスクが個別に実行され、サブタスクの結果が結合されて元のタスクの結果が形成されます。
forkメソッドは、あるスレッド上でタスクを非同期に開始し、joinメソッドを使用すると、このタスクが終了するまで待機できます。
新しい仕事盗むプール
newWorkStealingPoolメソッドには 2 つの実装があります。
public static ExecutorService newWorkStealingPool(int parallelism) {
return new ForkJoinPool
(parallelism,
ForkJoinPool.defaultForkJoinWorkerThreadFactory,
null, true);
}
public static ExecutorService newWorkStealingPool() {
return new ForkJoinPool
(Runtime.getRuntime().availableProcessors(),
ForkJoinPool.defaultForkJoinWorkerThreadFactory,
null, true);
}
最初から、内部ではThreadPoolExecutorコンストラクターを呼び出していないことに注意してください。ここでは、 ForkJoinPoolエンティティを操作します。ThreadPoolExecutorと同様に、これはAbstractExecutorServiceの実装です。
2つの方法からお選びいただけます。最初に、私たち自身がどのレベルの並列性を確認したいかを示します。この値を指定しない場合、プールの並列処理は Java 仮想マシンで使用できるプロセッサ コアの数と等しくなります。

実際にどのように機能するかを理解するのはまだ先のことです。
Collection<Callable<Void>> tasks = new ArrayList<>();
ExecutorService executorService = Executors.newWorkStealingPool(10);
for (int i = 0; i < 10; i++) {
int taskNumber = i;
Callable<Void> callable = () -> {
System.out.println("Processed user request #" + taskNumber + " on thread " + Thread.currentThread().getName());
return null;
};
tasks.add(callable);
}
executorService.invokeAll(tasks);
独自の完了ステータスを表示する 10 個のタスクを作成します。その後、invokeAllメソッドを使用してすべてのタスクを起動します。
プール内の 10 個のスレッドで 10 個のタスクを実行した場合の結果:
ForkJoinPool-1-worker-5 スレッド
でユーザー リクエスト #4 を処理 ForkJoinPool-1-worker-8 スレッドでユーザー リクエスト #7 を
処理 ForkJoinPool- でユーザー リクエスト #1 を処理1-worker-2 スレッド
ForkJoinPool-1-worker-3 スレッドでユーザー リクエスト #2 を処理
ForkJoinPool-1-worker-4 スレッドでユーザー リクエスト #3 を処理 ForkJoinPool-1-worker-7 スレッドで ユーザー リクエスト
#6 を処理
ForkJoinPool-1-worker-1 スレッドの
リクエスト #0 ForkJoinPool-1-worker-6 スレッドのユーザー リクエスト #5 を処理
ForkJoinPool-1-worker-9 スレッドのユーザー リクエスト #8 を処理
キューが形成された後、スレッドが実行用のタスクを受け取ることがわかります。10 個のスレッドのプールに 20 個のタスクがどのように分散されるかを確認することもできます。
ForkJoinPool-1-worker-8 スレッド
でユーザー リクエスト #7 を処理 ForkJoinPool-1-worker-3 スレッドでユーザー リクエスト #2 を
処理 ForkJoinPool- でユーザー リクエスト #4 を処理1-worker-5 スレッド
ForkJoinPool-1-worker-2 スレッドでユーザー
リクエスト #1 を処理 ForkJoinPool-1-worker-6 スレッドでユーザー リクエスト #5 を処理 ForkJoinPool-1-worker-9 スレッドで ユーザー リクエスト
#8 を処理
ForkJoinPool-1-worker-10 スレッドのリクエスト #9
ForkJoinPool-1-worker-1 スレッドのユーザー リクエスト #0 を処理
ForkJoinPool-1-worker-7 スレッドのユーザー リクエスト #6 を
処理 ForkJoinPool-1- のユーザー リクエスト #10ワーカー9スレッド
ForkJoinPool-1-worker-1 スレッドでユーザー リクエスト #12 を処理
ForkJoinPool-1-worker-8 スレッドでユーザー リクエスト
#13 を処理 ForkJoinPool-1-worker-6 スレッドでユーザー リクエスト #11 を
処理 ForkJoinPool- でユーザー リクエスト #15 を処理1-worker-8 スレッド
ForkJoinPool-1-worker-1 スレッドでユーザー リクエスト #14 を処理
ForkJoinPool-1-worker-6 スレッドでユーザー リクエスト #17 を処理 ForkJoinPool-1-worker-7 スレッドで ユーザー
リクエスト #16 を処理
ForkJoinPool-1-worker-6 スレッドのリクエスト #19
ForkJoinPool-1-worker-1 スレッドのユーザー リクエスト #18 を処理しました
出力から、いくつかのスレッドは複数のタスクを完了することができますが ( ForkJoinPool-1-worker-6 は4 つのタスクを完了しました)、いくつかのスレッドは 1 つしか完了しません ( ForkJoinPool-1-worker-2 )ことがわかります。callメソッドの実装に 1 秒の遅延が追加されると、状況が変わります。
Callable<Void> callable = () -> {
System.out.println("Processed user request #" + taskNumber + " on thread " + Thread.currentThread().getName());
TimeUnit.SECONDS.sleep(1);
return null;
};
実験のために、同じコードを別のマシンで実行してみましょう。結果の出力は次のとおりです。
ForkJoinPool-1-worker-31 スレッドでユーザー リクエスト #7 を
処理 ForkJoinPool-1-worker-27 スレッドでユーザー リクエスト #4 を
処理 ForkJoinPool- でユーザー リクエスト #5 を処理1-worker-13 スレッド
ForkJoinPool-1-worker-19 スレッドでユーザー リクエスト #0 を処理
ForkJoinPool-1-worker-3 スレッドでユーザー リクエスト #8 を処理
ForkJoinPool-1-worker-21 スレッドで
ユーザー リクエスト #9 を処理ForkJoinPool-1-worker-17 スレッドのリクエスト #6
ForkJoinPool-1-worker-9 スレッドのユーザー リクエスト #3 を処理
ForkJoinPool-1-worker-5 スレッドのユーザー リクエスト #1 を
処理 ForkJoinPool-1- のユーザー リクエスト #12ワーカー-23 スレッド
ForkJoinPool-1-worker-19 スレッドでユーザー リクエスト #15 を処理
ForkJoinPool-1-worker-27 スレッドでユーザー リクエスト
#14 を処理 ForkJoinPool-1-worker-3 スレッドでユーザー リクエスト #11 を
処理 ForkJoinPool- でユーザー リクエスト #13 を処理1-worker-13 スレッド
ForkJoinPool-1-worker-31 スレッドでユーザー リクエスト #10 を処理
ForkJoinPool-1-worker-5 スレッドでユーザー リクエスト #18 を処理 ForkJoinPool-1-worker-9 スレッドで ユーザー リクエスト
#16 を処理
ForkJoinPool-1-worker-21 スレッドのリクエスト #17
ForkJoinPool-1-worker-17 スレッドのユーザー リクエスト #19 を処理しました
この出力では、プール内のスレッドを「要求」したことが注目に値します。さらに、ワーカー スレッドの名前は 1 から 10 までではなく、10 を超える場合もあります。一意の名前を見ると、実際には 10 人のワーカー (3、5、9、13、17、19、21、23、27、および 31) が存在することがわかります。ここで、なぜこれが起こったのかを尋ねるのは非常に合理的です。何が起こっているのか理解できない場合は、デバッガーを使用してください。
これが私たちがやることです。をキャストしましょうexecutorサービスオブジェクトをForkJoinPoolに変換します。
final ForkJoinPool forkJoinPool = (ForkJoinPool) executorService;
invokeAllメソッドを呼び出した後、Evaluate Expression アクションを使用してこのオブジェクトを調べます。これを行うには、invokeAllメソッドの後に空の sout などのステートメントを追加し、それにブレークポイントを設定します。

プールには 10 個のスレッドがありますが、ワーカー スレッドの配列のサイズは 32 であることがわかります。奇妙ですが、大丈夫です。掘り続けましょう。プールを作成するときは、並列処理レベルを 32 以上、たとえば 40 に設定してみましょう。
ExecutorService executorService = Executors.newWorkStealingPool(40);
デバッガで見てみましょう。forkJoinPool オブジェクトを再度作成します。

現在、ワーカー スレッドの配列のサイズは 128 です。これは JVM の内部最適化の 1 つであると想定できます。JDK (openjdk-14) のコード内でそれを見つけてみましょう。

予想どおり、ワーカー スレッドの配列のサイズは、並列処理値に対してビット単位の操作を実行することによって計算されます。ここで何が起こっているのかを正確に理解しようとする必要はありません。このような最適化が存在することを知るだけで十分です。
この例のもう 1 つの興味深い点は、 invokeAllメソッドの使用です。invokeAllメソッドは結果、つまり結果のリスト (この場合は List <Future<Void>>)を返すことができ、そこで各タスクの結果を見つけることができることに注目してください。
var results = executorService.invokeAll(tasks);
for (Future<Void> result : results) {
// Process the task's result
}
この特別な種類のサービスとスレッド プールは、予測可能な、または少なくとも暗黙的なレベルの同時実行性を備えたタスクで使用できます。
GO TO FULL VERSION