Mari kita fikirkan kaedahWorkStealingPool baharu , yang menyediakan ExecutorService untuk kita.

Kolam benang ini istimewa. Tingkah lakunya adalah berdasarkan idea "mencuri" kerja.
Tugasan beratur dan diagihkan di kalangan pemproses. Tetapi jika pemproses sibuk, pemproses percuma lain boleh mencuri tugas daripadanya dan melaksanakannya. Format ini diperkenalkan di Java untuk mengurangkan konflik dalam aplikasi berbilang benang. Ia dibina pada rangka kerja garpu/sambung .
garpu/cantum
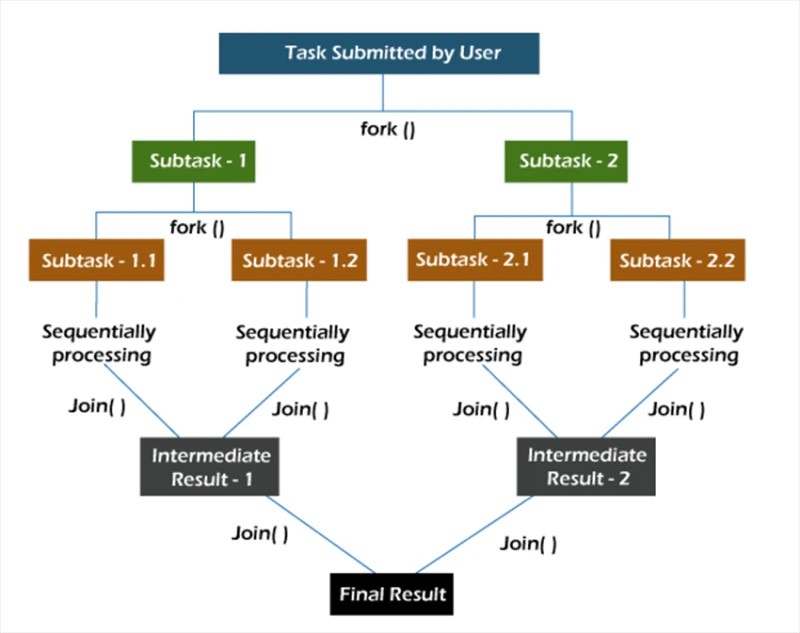
Dalam rangka kerja fork/join , tugasan diuraikan secara rekursif, iaitu, ia dipecahkan kepada subtugas. Kemudian subtugas dilaksanakan secara individu, dan hasil subtugas digabungkan untuk membentuk hasil tugas asal.
Kaedah fork memulakan tugasan secara tidak segerak pada beberapa utas, dan kaedah gabungan membolehkan anda menunggu tugasan ini selesai.
newWorkStealingPool
KaedahWorkStealingPool baharu mempunyai dua pelaksanaan:
public static ExecutorService newWorkStealingPool(int parallelism) {
return new ForkJoinPool
(parallelism,
ForkJoinPool.defaultForkJoinWorkerThreadFactory,
null, true);
}
public static ExecutorService newWorkStealingPool() {
return new ForkJoinPool
(Runtime.getRuntime().availableProcessors(),
ForkJoinPool.defaultForkJoinWorkerThreadFactory,
null, true);
}
Dari awal, kami perhatikan bahawa di bawah tudung kami tidak memanggil pembina ThreadPoolExecutor . Di sini kami bekerjasama dengan entiti ForkJoinPool . Seperti ThreadPoolExecutor , ia adalah pelaksanaan AbstractExecutorService .
Kami ada 2 kaedah untuk dipilih. Pada yang pertama, kita sendiri menunjukkan tahap paralelisme yang ingin kita lihat. Jika kami tidak menentukan nilai ini, maka keselarian kumpulan kami akan sama dengan bilangan teras pemproses yang tersedia untuk mesin maya Java.

Ia masih untuk memikirkan cara ia berfungsi dalam amalan:
Collection<Callable<Void>> tasks = new ArrayList<>();
ExecutorService executorService = Executors.newWorkStealingPool(10);
for (int i = 0; i < 10; i++) {
int taskNumber = i;
Callable<Void> callable = () -> {
System.out.println("Processed user request #" + taskNumber + " on thread " + Thread.currentThread().getName());
return null;
};
tasks.add(callable);
}
executorService.invokeAll(tasks);
Kami mencipta 10 tugasan yang memaparkan status penyelesaiannya sendiri. Selepas itu, kami melancarkan semua tugas menggunakan kaedah invokeAll .
Keputusan apabila melaksanakan 10 tugasan pada 10 utas dalam kumpulan:
Permintaan pengguna diproses #4 pada utas ForkJoinPool-1-worker-5
Permintaan pengguna diproses #7 pada utas ForkJoinPool-1-worker-8 Permintaan
pengguna diproses #1 pada ForkJoinPool- 1-worker-2 thread
Permintaan pengguna diproses #2 pada ForkJoinPool-1-worker-3 thread
Permintaan pengguna diproses #3 pada ForkJoinPool-1-worker-4 thread
Permintaan pengguna diproses #6 pada ForkJoinPool-1-worker-7 thread
Pengguna diproses permintaan #0 pada utas ForkJoinPool-1-worker-1
Permintaan pengguna diproses #5 pada utas ForkJoinPool-1-worker-6
Permintaan pengguna diproses #8 pada utas ForkJoinPool-1-worker-9
Kami melihat bahawa selepas baris gilir dibentuk, benang mengambil tugas untuk dilaksanakan. Anda juga boleh menyemak cara 20 tugasan akan diedarkan dalam kumpulan 10 utas.
Permintaan pengguna diproses #7 pada utas ForkJoinPool-1-worker-8
Permintaan pengguna diproses #2 pada utas ForkJoinPool-1-worker-3 Permintaan
pengguna diproses #4 pada ForkJoinPool- 1-worker-5 thread
Permintaan pengguna diproses #1 pada ForkJoinPool-1-worker-2 thread
Permintaan pengguna diproses #5 pada ForkJoinPool-1-worker-6 thread
Permintaan pengguna diproses #8 pada ForkJoinPool-1-worker-9 thread
Pengguna diproses permintaan #9 pada utas ForkJoinPool-1-worker-10
Permintaan pengguna diproses #0 pada utas ForkJoinPool-1-worker-1
Permintaan pengguna diproses #6 pada utas ForkJoinPool-1-worker-7
Permintaan pengguna diproses #10 pada ForkJoinPool-1- benang pekerja-9
Permintaan pengguna diproses #12 pada utas ForkJoinPool-1-worker-1
Permintaan pengguna diproses #13 pada utas ForkJoinPool-1-worker-8
Permintaan pengguna diproses #11 pada utas ForkJoinPool-1-worker-6
Permintaan pengguna diproses #15 pada ForkJoinPool- 1-worker-8 thread
Permintaan pengguna diproses #14 pada ForkJoinPool-1-worker-1 thread
Permintaan pengguna diproses #17 pada ForkJoinPool-1-worker-6 thread
Permintaan pengguna diproses #16 pada ForkJoinPool-1-worker-7 thread
Pengguna diproses permintaan #19 pada utas ForkJoinPool-1-worker-6
Permintaan pengguna diproses #18 pada utas ForkJoinPool-1-worker-1
Daripada output, kita dapat melihat bahawa beberapa utas berjaya menyelesaikan beberapa tugasan ( ForkJoinPool-1-worker-6 menyelesaikan 4 tugasan), manakala beberapa menyelesaikan hanya satu ( ForkJoinPool-1-worker-2 ). Jika kelewatan 1 saat ditambahkan pada pelaksanaan kaedah panggilan , gambar berubah.
Callable<Void> callable = () -> {
System.out.println("Processed user request #" + taskNumber + " on thread " + Thread.currentThread().getName());
TimeUnit.SECONDS.sleep(1);
return null;
};
Demi percubaan, mari jalankan kod yang sama pada mesin lain. Output yang terhasil:
Permintaan pengguna diproses #7 pada utas ForkJoinPool-1-worker-31
Permintaan pengguna diproses #4 pada utas ForkJoinPool-1-worker-27 Permintaan
pengguna diproses #5 pada ForkJoinPool- 1-worker-13 thread
Permintaan pengguna diproses #0 pada ForkJoinPool-1-worker-19 thread
Permintaan pengguna diproses #8 pada ForkJoinPool-1-worker-3 thread
Permintaan pengguna diproses #9 pada ForkJoinPool-1-worker-21 thread
Pengguna diproses permintaan #6 pada utas ForkJoinPool-1-worker-17
Permintaan pengguna diproses #3 pada utas ForkJoinPool-1-worker-9
Permintaan pengguna diproses #1 pada utas ForkJoinPool-1-worker-5
Permintaan pengguna diproses #12 pada ForkJoinPool-1- benang pekerja-23
Permintaan pengguna diproses #15 pada utas ForkJoinPool-1-worker-19
Permintaan pengguna diproses #14 pada utas ForkJoinPool-1-worker-27
Permintaan pengguna diproses #11 pada utas ForkJoinPool-1-worker-3 Permintaan
pengguna diproses #13 pada ForkJoinPool- 1-worker-13 thread
Permintaan pengguna diproses #10 pada ForkJoinPool-1-worker-31 thread
Permintaan pengguna diproses #18 pada ForkJoinPool-1-worker-5 thread
Permintaan pengguna diproses #16 pada ForkJoinPool-1-worker-9 thread
Pengguna diproses permintaan #17 pada utas ForkJoinPool-1-worker-21
Permintaan pengguna diproses #19 pada utas ForkJoinPool-1-worker-17
Dalam output ini, adalah ketara bahawa kami "meminta" benang dalam kolam. Lebih-lebih lagi, nama benang pekerja tidak berubah dari satu hingga sepuluh, sebaliknya kadang-kadang lebih tinggi daripada sepuluh. Melihat kepada nama-nama yang unik, kita melihat bahawa terdapat sepuluh pekerja (3, 5, 9, 13, 17, 19, 21, 23, 27 dan 31). Di sini agak munasabah untuk bertanya mengapa ini berlaku? Apabila anda tidak memahami perkara yang sedang berlaku, gunakan penyahpepijat.
Inilah yang akan kita lakukan. Mari kita buangexecutorServicemembantah ForkJoinPool :
final ForkJoinPool forkJoinPool = (ForkJoinPool) executorService;
Kami akan menggunakan tindakan Evaluate Expression untuk memeriksa objek ini selepas memanggil kaedah invokeAll . Untuk melakukan ini, selepas kaedah invokeAll , tambahkan sebarang pernyataan, seperti sout kosong, dan tetapkan titik putus padanya.

Kita dapat melihat bahawa kolam itu mempunyai 10 utas, tetapi saiz susunan benang pekerja ialah 32. Pelik, tetapi tidak mengapa. Mari kita terus menggali. Apabila membuat kolam, mari cuba tetapkan tahap selari kepada lebih daripada 32, katakan 40.
ExecutorService executorService = Executors.newWorkStealingPool(40);
Dalam penyahpepijat, mari kita lihat padaobjek forkJoinPool sekali lagi.

Kini saiz tatasusunan benang pekerja ialah 128. Kita boleh mengandaikan bahawa ini adalah salah satu pengoptimuman dalaman JVM. Mari cuba cari dalam kod JDK (openjdk-14):

Sama seperti yang kami syak: saiz tatasusunan benang pekerja dikira dengan melakukan manipulasi bitwise pada nilai selari. Kita tidak perlu cuba memikirkan apa sebenarnya yang berlaku di sini. Cukup sekadar mengetahui bahawa pengoptimuman sedemikian wujud.
Satu lagi aspek menarik dalam contoh kami ialah penggunaan kaedah invokeAll . Perlu diingat bahawa kaedah invokeAll boleh mengembalikan hasil, atau lebih tepatnya senarai hasil (dalam kes kami, List <Future<Void>>) , di mana kami boleh mencari hasil setiap tugas.
var results = executorService.invokeAll(tasks);
for (Future<Void> result : results) {
// Process the task's result
}
Jenis perkhidmatan dan kumpulan benang khas ini boleh digunakan dalam tugasan dengan tahap keselarasan yang boleh diramal, atau sekurang-kurangnya tersirat.
GO TO FULL VERSION