Scopriamo il metodo newWorkStealingPool , che prepara un ExecutorService per noi.

Questo pool di thread è speciale. Il suo comportamento si basa sull'idea di "rubare" il lavoro.
Le attività vengono messe in coda e distribuite tra i processori. Ma se un processore è occupato, un altro processore libero può rubargli un compito ed eseguirlo. Questo formato è stato introdotto in Java per ridurre i conflitti nelle applicazioni multi-thread. È costruito sul framework fork/join .
biforcare/congiungere
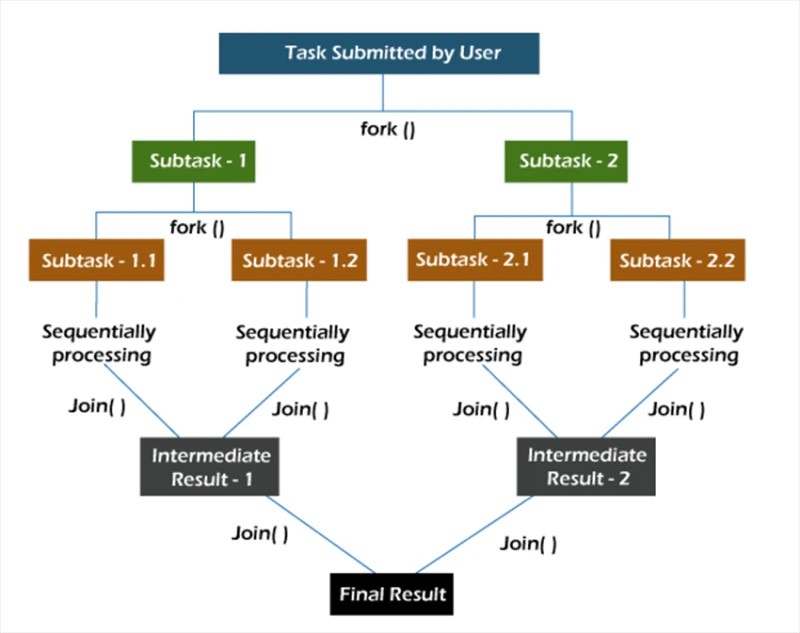
Nel framework fork/join , le attività vengono scomposte in modo ricorsivo, ovvero vengono suddivise in attività secondarie. Quindi le attività secondarie vengono eseguite singolarmente ei risultati delle attività secondarie vengono combinati per formare il risultato dell'attività originale.
Il metodo fork avvia un'attività in modo asincrono su un thread e il metodo join consente di attendere il completamento di questa attività.
newWorkStealingPool
Il metodo newWorkStealingPool ha due implementazioni:
public static ExecutorService newWorkStealingPool(int parallelism) {
return new ForkJoinPool
(parallelism,
ForkJoinPool.defaultForkJoinWorkerThreadFactory,
null, true);
}
public static ExecutorService newWorkStealingPool() {
return new ForkJoinPool
(Runtime.getRuntime().availableProcessors(),
ForkJoinPool.defaultForkJoinWorkerThreadFactory,
null, true);
}
Fin dall'inizio, notiamo che sotto il cofano non chiamiamo il costruttore ThreadPoolExecutor . Qui stiamo lavorando con l' entità ForkJoinPool . Come ThreadPoolExecutor , è un'implementazione di AbstractExecutorService .
Abbiamo 2 metodi tra cui scegliere. Nella prima, noi stessi indichiamo quale livello di parallelismo vogliamo vedere. Se non specifichiamo questo valore, il parallelismo del nostro pool sarà uguale al numero di core del processore disponibili per la macchina virtuale Java.

Resta da capire come funziona in pratica:
Collection<Callable<Void>> tasks = new ArrayList<>();
ExecutorService executorService = Executors.newWorkStealingPool(10);
for (int i = 0; i < 10; i++) {
int taskNumber = i;
Callable<Void> callable = () -> {
System.out.println("Processed user request #" + taskNumber + " on thread " + Thread.currentThread().getName());
return null;
};
tasks.add(callable);
}
executorService.invokeAll(tasks);
Creiamo 10 attività che mostrano il proprio stato di completamento. Successivamente, lanciamo tutte le attività utilizzando il metodo invokeAll .
Risultati durante l'esecuzione di 10 attività su 10 thread nel pool:
Richiesta utente elaborata n. 4 sul thread ForkJoinPool-1-worker-5
Richiesta utente elaborata n. 7 sul thread ForkJoinPool-1-worker-8
Richiesta utente elaborata n. Thread 1-worker-2
Richiesta utente elaborata n. 2 su thread ForkJoinPool-1-worker-3
Richiesta utente elaborata n. 3 su thread ForkJoinPool-1-worker-4
Richiesta utente elaborata n. 6 su thread ForkJoinPool-1-worker-7
Utente elaborato richiesta n. 0 sul thread ForkJoinPool-1-worker-1
Richiesta utente elaborata n. 5 sul thread ForkJoinPool-1-worker-6
Richiesta utente elaborata n. 8 sul thread ForkJoinPool-1-worker-9
Vediamo che dopo che la coda è stata formata, i thread accettano le attività per l'esecuzione. Puoi anche verificare come verranno distribuite 20 attività in un pool di 10 thread.
Richiesta utente elaborata n. 7 sul thread ForkJoinPool-1-worker-8
Richiesta utente elaborata n. 2 sul thread ForkJoinPool-1-worker-3
Richiesta utente elaborata n. Thread 1-worker-5
Richiesta utente elaborata n. 1 su thread ForkJoinPool-1-worker-2
Richiesta utente elaborata n. 5 su thread ForkJoinPool-1-worker-6
Richiesta utente elaborata n. 8 su thread ForkJoinPool-1-worker-9
Utente elaborato richiesta n. 9 sul thread ForkJoinPool-1-worker-10
Richiesta utente elaborata n. 0 sul thread ForkJoinPool-1
-worker-1 Richiesta utente elaborata n. 6 sul thread ForkJoinPool-1-worker-7
Richiesta utente elaborata n. filo lavoratore-9
Richiesta utente elaborata n. 12 sul thread ForkJoinPool-1-worker-1
Richiesta utente elaborata n. 13 sul thread
ForkJoinPool-1-worker-8 Richiesta utente elaborata n. 11 sul thread ForkJoinPool-1-worker-6
Richiesta utente elaborata n. Thread 1-worker-8
Richiesta utente elaborata n. 14 su thread ForkJoinPool-1-worker-1
Richiesta utente elaborata n. 17 su thread ForkJoinPool-1-worker-6
Richiesta utente elaborata n. 16 su thread ForkJoinPool-1-worker-7
Utente elaborato richiesta n. 19 sul thread ForkJoinPool-1-worker-6
Richiesta utente elaborata n. 18 sul thread ForkJoinPool-1-worker-1
Dall'output, possiamo vedere che alcuni thread riescono a completare diverse attività ( ForkJoinPool-1-worker-6 ha completato 4 attività), mentre alcuni ne completano solo una ( ForkJoinPool-1-worker-2 ). Se viene aggiunto un ritardo di 1 secondo all'implementazione del metodo call , l'immagine cambia.
Callable<Void> callable = () -> {
System.out.println("Processed user request #" + taskNumber + " on thread " + Thread.currentThread().getName());
TimeUnit.SECONDS.sleep(1);
return null;
};
Per motivi di esperimento, eseguiamo lo stesso codice su un'altra macchina. L'output risultante:
Richiesta utente elaborata n. 7 sul thread ForkJoinPool-1-worker-31
Richiesta utente elaborata n. 4 sul thread ForkJoinPool-1-worker-27 Richiesta
utente elaborata n. Thread 1-worker-13
Richiesta utente elaborata n. 0 su thread ForkJoinPool-1-worker-19
Richiesta utente elaborata n. 8 su thread ForkJoinPool-1-worker-3
Richiesta utente elaborata n. 9 su thread ForkJoinPool-1-worker-21
Utente elaborato richiesta n. 6 sul thread ForkJoinPool-1-worker-17
Richiesta utente elaborata n. 3 sul thread ForkJoinPool-1
-worker-9 Richiesta utente elaborata n. 1 sul thread ForkJoinPool-1-worker-5 Richiesta
utente elaborata n. 12 su ForkJoinPool-1- filo lavoratore-23
Richiesta utente elaborata n. 15 sul thread ForkJoinPool-1-worker-19
Richiesta utente elaborata n. 14 sul thread
ForkJoinPool-1-worker-27 Richiesta utente elaborata n. 11 sul thread ForkJoinPool-1-worker-3
Richiesta utente elaborata n. Thread 1-worker-13
Richiesta utente elaborata n. 10 su thread ForkJoinPool-1-worker-31
Richiesta utente elaborata n. 18 su thread ForkJoinPool-1-worker-5
Richiesta utente elaborata n. 16 su thread ForkJoinPool-1-worker-9
Utente elaborato richiesta n. 17 sul thread ForkJoinPool-1-worker-21
Richiesta utente elaborata n. 19 sul thread ForkJoinPool-1-worker-17
In questo output, è da notare che abbiamo "chiesto" i thread nel pool. Inoltre, i nomi dei thread di lavoro non vanno da uno a dieci, ma talvolta sono superiori a dieci. Osservando i nomi univoci, vediamo che in realtà ci sono dieci lavoratori (3, 5, 9, 13, 17, 19, 21, 23, 27 e 31). Qui è abbastanza ragionevole chiedersi perché è successo? Ogni volta che non capisci cosa sta succedendo, usa il debugger.
Questo è quello che faremo. Lanciamo ilexecutorServiceoggetto a un ForkJoinPool :
final ForkJoinPool forkJoinPool = (ForkJoinPool) executorService;
Useremo l'azione Evaluate Expression per esaminare questo oggetto dopo aver chiamato il metodo invokeAll . Per fare ciò, dopo il metodo invokeAll , aggiungi qualsiasi istruzione, ad esempio un sout vuoto, e imposta un punto di interruzione su di esso.

Possiamo vedere che il pool ha 10 thread, ma la dimensione dell'array di thread di lavoro è 32. Strano, ma va bene. Continuiamo a scavare. Quando creiamo un pool, proviamo a impostare il livello di parallelismo su più di 32, diciamo 40.
ExecutorService executorService = Executors.newWorkStealingPool(40);
Nel debugger, diamo un'occhiata al fileforkJoinPool nuovamente l'oggetto.

Ora la dimensione dell'array di thread di lavoro è 128. Possiamo presumere che questa sia una delle ottimizzazioni interne della JVM. Proviamo a trovarlo nel codice del JDK (openjdk-14):

Proprio come sospettavamo: la dimensione dell'array di thread di lavoro viene calcolata eseguendo manipolazioni bit per bit sul valore di parallelismo. Non abbiamo bisogno di cercare di capire cosa sta succedendo esattamente qui. È sufficiente sapere semplicemente che esiste una tale ottimizzazione.
Un altro aspetto interessante del nostro esempio è l'uso del metodo invokeAll . Vale la pena notare che il metodo invokeAll può restituire un risultato, o meglio un elenco di risultati (nel nostro caso, un List<Future<Void>>) , dove possiamo trovare il risultato di ciascuna delle attività.
var results = executorService.invokeAll(tasks);
for (Future<Void> result : results) {
// Process the task's result
}
Questo tipo speciale di servizio e pool di thread può essere utilizzato in attività con un livello di concorrenza prevedibile o almeno implicito.
GO TO FULL VERSION