3.1. Svage SYRE egenskaber
I lang tid har datakonsistens været en hellig ko for arkitekter og udviklere. Alle relationelle databaser gav en vis grad af isolation, enten gennem opdateringslåse og blokeringslæsninger eller gennem fortryd-logfiler. Med fremkomsten af enorme mængder information og distribuerede systemer blev det klart, at det var umuligt at sikre et transaktionssæt af operationer for dem på den ene side og at opnå høj tilgængelighed og hurtig responstid på den anden side.
Desuden garanterer selv opdatering af én post ikke, at enhver anden bruger øjeblikkeligt vil se ændringer i systemet, fordi ændringen kan forekomme, for eksempel i masterknuden, og replikaen kopieres asynkront til slaveknuden, med hvilken en anden bruger arbejder. I dette tilfælde vil han se resultatet efter en vis periode. Dette kaldes eventuel konsistens, og det er, hvad alle de største internetvirksomheder i verden går til nu, inklusive Facebook og Amazon. Sidstnævnte erklærer stolt, at det maksimale interval, hvor brugeren kan se inkonsistente data, ikke er mere end et sekund. Et eksempel på en sådan situation er vist i figuren:
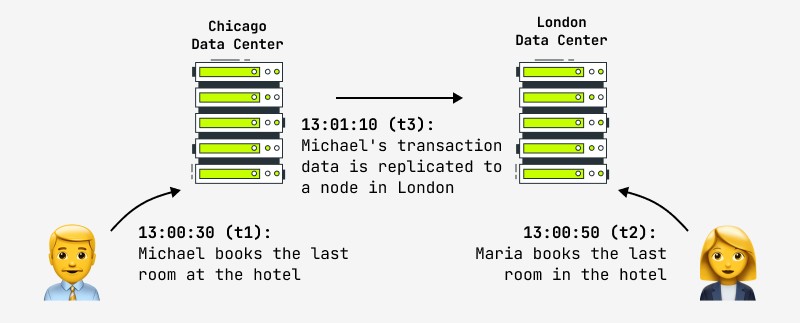
Det logiske spørgsmål, der opstår i en sådan situation, er, hvad man skal gøre med systemer, der klassisk stiller høje krav til driftens atomicitet-konsistens og samtidig har brug for hurtigt distribuerede klynger - finansielle, netbutikker osv.? Praksis viser, at disse krav ikke længere er relevante: her er, hvad en designer af det finansielle banksystem sagde: "Hvis vi virkelig ventede på afslutningen af hver transaktion i det globale netværk af pengeautomater (ATM'er), ville transaktioner tage så lang tid, at kunderne ville stikke af i raseri. Hvad sker der, hvis du og din partner hæver penge på samme tid og overskrider grænsen? "I får begge pengene, og vi ordner det senere."

Et andet eksempel er hotelbookingen vist på billedet. Onlinebutikker, hvis datapolitik forudsætter eventuel konsistens, er forpligtet til at levere foranstaltninger i tilfælde af sådanne situationer (automatisk konfliktløsning, tilbagerulning af drift, opdatering med andre data). I praksis forsøger hoteller altid at have en "pulje" af ledige værelser i tilfælde af en nødsituation, og det kan være en løsning på en kontroversiel situation.
Faktisk betyder svage ACID-egenskaber ikke, at de slet ikke eksisterer. I de fleste tilfælde bruger en applikation, der arbejder med en relationsdatabase, en transaktion til at ændre logisk relaterede objekter (ordre - ordre poster), hvilket er nødvendigt, da disse er forskellige tabeller. Med det korrekte design af datamodellen i en NoSQL-database (et aggregat er en ordre sammen med en liste over ordreposter), kan du opnå samme niveau af isolation ved ændring af en enkelt post som i en relationsdatabase.
3.2. Distribuerede systemer, ingen delte ressourcer (del intet)
Igen, dette gælder ikke for databasegrafer, hvis struktur pr. definition ikke spredes godt på tværs af fjerntliggende noder.
Dette er måske hovedledemotivet i udviklingen af NoSQL-databaser. Med lavinevæksten af information i verden og behovet for at behandle den inden for rimelig tid, opstod problemet med vertikal skalerbarhed - væksten i processorhastigheden stoppede ved 3,5 GHz, hastigheden for læsning fra disken vokser også med en langsomt tempo, plus prisen på en kraftfuld server er altid mere end den samlede pris for flere simple servere. I denne situation er konventionelle relationelle databaser, selv grupperet på en række diske, ikke i stand til at løse problemet med hastighed, skalerbarhed og gennemløb.
Den eneste vej ud af situationen er horisontal skalering, når flere uafhængige servere er forbundet med et hurtigt netværk og hver ejer/behandler kun en del af dataene og/eller kun en del af anmodningerne om læseopdatering. I denne arkitektur behøver du kun at tilføje en ny server til klyngen for at øge lagerkapaciteten (kapacitet, responstid, gennemløb) - og det er det. Sharding, replikering, fejltolerance (resultatet opnås, selvom en eller flere servere holder op med at reagere), dataomfordeling i tilfælde af tilføjelse af en node håndteres af selve NoSQL-databasen.
Jeg vil kort præsentere hovedegenskaberne for distribuerede NoSQL-databaser:
Replikering - kopiering af data til andre noder ved opdatering. Giver både mulighed for at opnå større skalerbarhed og øge tilgængeligheden og sikkerheden af data. Det er sædvanligt at opdele i to typer:
master-slave : og peer-to-peer :
og peer-to-peer : 
Den første type forudsætter god skalerbarhed til læsning (kan ske fra enhver node), men ikke-skalerbar skrivning (kun til masterknudepunktet). Der er også finesser med at sikre konstant tilgængelighed (i tilfælde af et masternedbrud, enten manuelt eller automatisk tildeles en af de resterende noder dens plads). Den anden type replikering antager, at alle noder er ens og kan betjene både læse- og skriveanmodninger.
Sharding er opdelingen af data efter noder:

Sharding blev ofte brugt som en "krykke" til relationelle databaser for at øge hastigheden og gennemløbet: Brugerapplikationen opdelte data på tværs af flere uafhængige databaser og, når brugeren anmodede om de tilsvarende data, fik adgang til en specifik database. I NoSQL-databaser udføres sharding, ligesom replikering, automatisk af databasen selv, og brugerapplikationen er adskilt fra disse komplekse mekanismer.
3.3. NoSQL-databaser er for det meste open source og skabt i det 21. århundrede
Det er på den anden grund, at Sadalaj og Fowler ikke klassificerede objektdatabaser som NoSQL (selvom http://nosql-database.org/ inkluderer dem på den generelle liste), da de blev oprettet tilbage i 90'erne og aldrig opnåede særlig stor popularitet ...
NoSQL-bevægelsen vinder popularitet i et gigantisk tempo. Dette betyder dog ikke, at relationelle databaser bliver rudimentielle eller noget arkaisk. Højst sandsynligt vil de blive brugt og brugt som hidtil aktivt, men flere og flere NoSQL-databaser vil fungere i symbiose med dem. Vi går ind i en æra med polyglot persistens, en æra hvor forskellige datalagre bruges til forskellige behov. Nu er der intet monopol på relationelle databaser som en ubestridt kilde til data. Arkitekter vælger i stigende grad opbevaring baseret på arten af selve dataene, og hvordan vi ønsker at manipulere dem, hvilke mængder information der forventes. Og så bliver alt bare mere interessant.
Nedenfor vil vi forsøge at forstå driften af en distribueret database ved hjælp af NoSQL Cassandra DBMS som et eksempel ...