3.1. Schwache Säureeigenschaften
Datenkonsistenz war lange Zeit eine heilige Kuh für Architekten und Entwickler. Alle relationalen Datenbanken boten ein gewisses Maß an Isolation, entweder durch Aktualisierungssperren und blockierende Lesevorgänge oder durch Rückgängig-Protokolle. Mit dem Aufkommen riesiger Informationsmengen und verteilter Systeme wurde klar, dass es unmöglich war, einerseits einen Transaktionssatz für sie sicherzustellen und andererseits eine hohe Verfügbarkeit und schnelle Reaktionszeit zu erreichen.
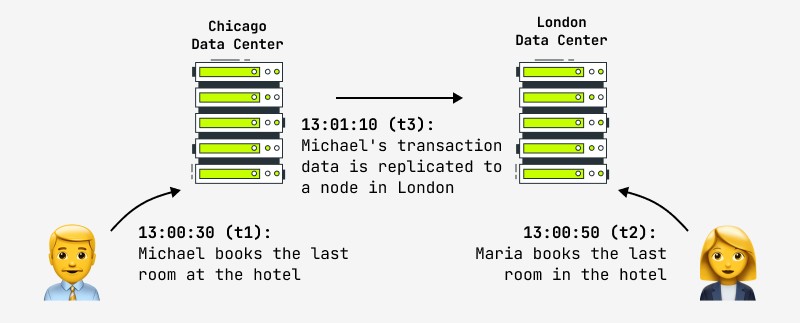
Darüber hinaus garantiert selbst die Aktualisierung eines Datensatzes nicht, dass jeder andere Benutzer Änderungen im System sofort sieht, da die Änderung beispielsweise im Master-Knoten auftreten kann und das Replikat asynchron auf den Slave-Knoten kopiert wird, mit dem ein anderer Benutzer zusammenarbeitet funktioniert. In diesem Fall wird er das Ergebnis nach einer gewissen Zeit sehen. Dies nennt man „Eventual Consistency“ und das ist es, was jetzt alle größten Internetunternehmen der Welt anstreben, einschließlich Facebook und Amazon. Letztere geben stolz an, dass das maximale Intervall, in dem der Benutzer inkonsistente Daten sehen kann, nicht mehr als eine Sekunde beträgt. Ein Beispiel für eine solche Situation ist in der Abbildung dargestellt:
Die logische Frage, die sich in einer solchen Situation stellt, ist, was mit Systemen zu tun ist, die klassischerweise hohe Anforderungen an die Atomizitätskonsistenz von Abläufen stellen und gleichzeitig schnelle verteilte Cluster benötigen – Finanzen, Online-Shops usw.? Die Praxis zeigt, dass diese Anforderungen nicht mehr relevant sind: Hier ist, was ein Entwickler des Finanzbankensystems sagte: „Wenn wir wirklich auf den Abschluss jeder Transaktion im globalen Netzwerk von Geldautomaten (ATMs) warten würden, würden Transaktionen so lange dauern, dass Kunden.“ würde vor Wut davonlaufen. Was passiert, wenn Sie und Ihr Partner gleichzeitig Geld abheben und das Limit überschreiten? „Sie bekommen beide das Geld, und wir werden es später reparieren.“

Ein weiteres Beispiel ist die im Bild gezeigte Hotelbuchung. Online-Shops, deren Datenpolitik eine letztendliche Konsistenz voraussetzt, müssen in solchen Situationen Maßnahmen ergreifen (automatische Konfliktlösung, Vorgangs-Rollback, Aktualisierung mit anderen Daten). In der Praxis versuchen Hotels immer, für den Notfall einen „Pool“ an freien Zimmern vorzuhalten, was eine Lösung für eine kontroverse Situation sein kann.
Tatsächlich bedeuten schwache ACID-Eigenschaften nicht, dass sie überhaupt nicht existieren. In den meisten Fällen verwendet eine Anwendung, die mit einer relationalen Datenbank arbeitet, eine Transaktion, um logisch zusammengehörige Objekte (Auftrag – Auftragspositionen) zu ändern, was notwendig ist, da es sich um unterschiedliche Tabellen handelt. Mit dem richtigen Design des Datenmodells in einer NoSQL-Datenbank (ein Aggregat ist eine Bestellung zusammen mit einer Liste von Bestellpositionen) können Sie beim Ändern eines einzelnen Datensatzes das gleiche Maß an Isolation erreichen wie in einer relationalen Datenbank.
3.2. Verteilte Systeme, keine gemeinsamen Ressourcen (nichts teilen)
Dies gilt wiederum nicht für Datenbankdiagramme, deren Struktur sich per Definition nicht gut über entfernte Knoten verteilt.
Dies ist vielleicht das Hauptleitmotiv der Entwicklung von NoSQL-Datenbanken. Mit dem rasanten Wachstum der Informationen auf der Welt und der Notwendigkeit, sie in angemessener Zeit zu verarbeiten, entstand das Problem der vertikalen Skalierbarkeit – das Wachstum der Prozessorgeschwindigkeit stoppte bei 3,5 GHz, die Geschwindigkeit des Lesens von der Festplatte wächst ebenfalls um 3,5 GHz langsames Tempo, außerdem ist der Preis eines leistungsstarken Servers immer höher als der Gesamtpreis mehrerer einfacher Server. In dieser Situation sind herkömmliche relationale Datenbanken, selbst wenn sie auf einem Array von Festplatten geclustert sind, nicht in der Lage, das Problem der Geschwindigkeit, Skalierbarkeit und des Durchsatzes zu lösen.
Der einzige Ausweg aus der Situation ist die horizontale Skalierung, wenn mehrere unabhängige Server über ein schnelles Netzwerk verbunden sind und jeder nur einen Teil der Daten und/oder nur einen Teil der Lese-Update-Anfragen besitzt/verarbeitet. In dieser Architektur müssen Sie zur Erhöhung der Speicherkapazität (Kapazität, Antwortzeit, Durchsatz) lediglich einen neuen Server zum Cluster hinzufügen – und das war's. Sharding, Replikation, Fehlertoleranz (das Ergebnis wird auch dann erhalten, wenn ein oder mehrere Server nicht mehr reagieren), Datenumverteilung beim Hinzufügen eines Knotens wird von der NoSQL-Datenbank selbst übernommen.
Ich werde kurz die Haupteigenschaften verteilter NoSQL-Datenbanken vorstellen:
Replikation – Kopieren von Daten auf andere Knoten beim Aktualisieren. Ermöglicht sowohl eine größere Skalierbarkeit als auch eine Erhöhung der Verfügbarkeit und Sicherheit von Daten. Es ist üblich, in zwei Typen zu unterteilen:
Master-Slave : und Peer-to-Peer :
und Peer-to-Peer : 
Der erste Typ setzt eine gute Skalierbarkeit beim Lesen voraus (kann von jedem Knoten aus erfolgen), aber nicht skalierbares Schreiben (nur zum Masterknoten). Auch bei der Sicherstellung der ständigen Verfügbarkeit gibt es Feinheiten (im Falle eines Master-Absturzes wird entweder manuell oder automatisch einer der verbleibenden Knoten seinem Platz zugewiesen). Bei der zweiten Art der Replikation wird davon ausgegangen, dass alle Knoten gleich sind und sowohl Lese- als auch Schreibanforderungen bedienen können.
Sharding ist die Aufteilung von Daten nach Knoten:

Sharding wurde oft als „Krücke“ für relationale Datenbanken verwendet, um Geschwindigkeit und Durchsatz zu erhöhen: Die Benutzeranwendung partitionierte Daten auf mehrere unabhängige Datenbanken und griff auf eine bestimmte Datenbank zu, wenn der Benutzer die entsprechenden Daten anforderte. In NoSQL-Datenbanken erfolgt das Sharding ebenso wie die Replikation automatisch durch die Datenbank selbst und die Benutzeranwendung ist von diesen komplexen Mechanismen getrennt.
3.3. NoSQL-Datenbanken sind größtenteils Open Source und wurden im 21. Jahrhundert erstellt
Aus dem zweiten Grund haben Sadalaj und Fowler Objektdatenbanken nicht als NoSQL klassifiziert (obwohl http://nosql-database.org/ sie in die allgemeine Liste aufnimmt), da sie bereits in den 90er Jahren erstellt wurden und nie große Popularität erlangten . .
Die NoSQL-Bewegung erfreut sich rasanter Beliebtheit. Dies bedeutet jedoch nicht, dass relationale Datenbanken veraltet oder veraltet sind. Höchstwahrscheinlich werden sie nach wie vor aktiv genutzt und genutzt, aber immer mehr NoSQL-Datenbanken werden mit ihnen in Symbiose agieren. Wir betreten eine Ära der polyglotten Persistenz, eine Ära, in der unterschiedliche Datenspeicher für unterschiedliche Anforderungen verwendet werden. Nun gibt es kein Monopol auf relationale Datenbanken als unbestrittene Datenquelle. Architekten entscheiden sich zunehmend für die Speicherung basierend auf der Art der Daten selbst und darauf, wie wir sie bearbeiten möchten und welche Informationsmengen erwartet werden. Und so wird alles noch interessanter.
Im Folgenden werden wir versuchen, die Funktionsweise einer verteilten Datenbank am Beispiel des NoSQL Cassandra DBMS zu verstehen ...