3.1. Zwakke ACID-eigenschappen
Dataconsistentie is lange tijd een heilige koe geweest voor architecten en ontwikkelaars. Alle relationele databases zorgden voor een zekere mate van isolatie, hetzij door updatevergrendelingen en het blokkeren van leesbewerkingen, hetzij door logboeken ongedaan te maken. Met de komst van enorme hoeveelheden informatie en gedistribueerde systemen, werd het duidelijk dat het onmogelijk was om enerzijds een transactiepakket voor hen te garanderen en anderzijds een hoge beschikbaarheid en snelle responstijd te verkrijgen.
Bovendien garandeert zelfs het bijwerken van één record niet dat een andere gebruiker direct wijzigingen in het systeem zal zien, omdat de wijziging bijvoorbeeld kan optreden in het masterknooppunt en de replica asynchroon wordt gekopieerd naar het slaafknooppunt, waarmee een andere gebruiker werken. In dit geval zal hij het resultaat na een bepaalde tijd zien. Dit wordt uiteindelijke consistentie genoemd en dit is waar alle grootste internetbedrijven ter wereld nu naar toe gaan, inclusief Facebook en Amazon. Deze laatste verklaren trots dat het maximale interval waarin de gebruiker inconsistente gegevens kan zien, niet meer dan een seconde is. Een voorbeeld van een dergelijke situatie wordt getoond in de figuur:
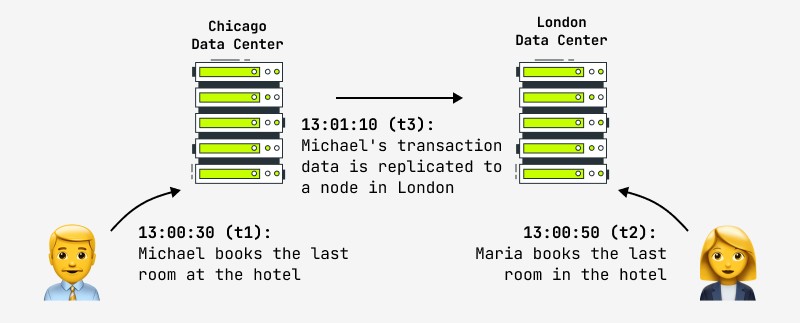
De logische vraag die in zo'n situatie opkomt, is wat te doen met systemen die klassiek hoge eisen stellen aan de atomiciteit-consistentie van operaties en tegelijkertijd snel gedistribueerde clusters nodig hebben - financiële, online winkels, etc.? De praktijk leert dat deze vereisten niet langer relevant zijn: hier is wat een ontwerper van het financiële banksysteem zei: "Als we echt zouden wachten op de voltooiing van elke transactie in het wereldwijde netwerk van ATM's (ATM's), zouden transacties zo lang duren dat klanten zou woedend weglopen. Wat gebeurt er als u en uw partner tegelijkertijd geld opnemen en de limiet overschrijden? "Jullie krijgen allebei het geld, en we zullen het later repareren."

Een ander voorbeeld is de hotelboeking op de foto. Onlinewinkels waarvan het gegevensbeleid uitgaat van uiteindelijke consistentie, zijn verplicht maatregelen te treffen in dergelijke situaties (automatische conflictoplossing, terugdraaien van bewerkingen, bijwerken met andere gegevens). In de praktijk proberen hotels altijd een "pool" van vrije kamers te houden in geval van nood, en dit kan een oplossing zijn voor een controversiële situatie.
In feite betekenen zwakke ACID-eigenschappen niet dat ze helemaal niet bestaan. In de meeste gevallen gebruikt een applicatie die werkt met een relationele database een transactie om logisch gerelateerde objecten (order - orderitems) te wijzigen, wat nodig is, aangezien dit verschillende tabellen zijn. Met het juiste ontwerp van het gegevensmodel in een NoSQL-database (een aggregatie is een bestelling samen met een lijst met bestellingsitems), kunt u bij het wijzigen van een enkel record hetzelfde niveau van isolatie bereiken als in een relationele database.
3.2. Gedistribueerde systemen, geen gedeelde bronnen (deel niets)
Nogmaals, dit is niet van toepassing op databasegrafieken, waarvan de structuur per definitie niet goed verspreid is over afgelegen knooppunten.
Dit is misschien wel het belangrijkste leidmotief van de ontwikkeling van NoSQL-databases. Met de lawinegroei van informatie in de wereld en de noodzaak om deze binnen een redelijke tijd te verwerken, ontstond het probleem van verticale schaalbaarheid - de groei van de processorsnelheid stopte bij 3,5 GHz, de leessnelheid van de schijf groeit ook met een traag tempo, plus de prijs van een krachtige server is altijd meer dan de totale prijs van meerdere eenvoudige servers. In deze situatie kunnen conventionele relationele databases, zelfs geclusterd op een reeks schijven, het probleem van snelheid, schaalbaarheid en doorvoer niet oplossen.
De enige uitweg uit de situatie is horizontale schaalvergroting, wanneer verschillende onafhankelijke servers zijn verbonden door een snel netwerk en elk slechts een deel van de gegevens en/of slechts een deel van de lees-updateverzoeken bezit / verwerkt. In deze architectuur hoeft u, om de opslagcapaciteit (capaciteit, responstijd, doorvoer) te vergroten, alleen een nieuwe server aan het cluster toe te voegen - en dat is alles. Sharding, replicatie, fouttolerantie (het resultaat wordt verkregen, zelfs als een of meer servers niet meer reageren), herdistributie van gegevens in het geval van het toevoegen van een knooppunt wordt afgehandeld door de NoSQL-database zelf.
Ik zal kort de belangrijkste eigenschappen van gedistribueerde NoSQL-databases presenteren:
Replicatie - kopiëren van gegevens naar andere knooppunten bij het updaten. Maakt het mogelijk om zowel een grotere schaalbaarheid te bereiken als de beschikbaarheid en veiligheid van gegevens te vergroten. Het is gebruikelijk om onder te verdelen in twee typen:
meester-slaaf : en peer-to-peer :
en peer-to-peer : 
Het eerste type gaat uit van goede schaalbaarheid voor lezen (kan gebeuren vanaf elk knooppunt), maar niet-schaalbaar schrijven (alleen naar het hoofdknooppunt). Er zijn ook subtiliteiten om te zorgen voor constante beschikbaarheid (in het geval van een mastercrash wordt handmatig of automatisch een van de resterende knooppunten aan zijn plaats toegewezen). Het tweede type replicatie gaat ervan uit dat alle knooppunten gelijk zijn en zowel lees- als schrijfverzoeken kunnen verwerken.
Sharding is de verdeling van gegevens door knooppunten:

Sharding werd vaak gebruikt als een "steunpunt" voor relationele databases om de snelheid en doorvoer te verhogen: de gebruikerstoepassing verdeelde gegevens over verschillende onafhankelijke databases en, wanneer de gebruiker om de overeenkomstige gegevens vroeg, toegang tot een specifieke database. In NoSQL-databases wordt sharding, net als replicatie, automatisch uitgevoerd door de database zelf en staat de gebruikerstoepassing los van deze complexe mechanismen.
3.3. NoSQL-databases zijn meestal open source en gemaakt in de 21e eeuw
Het is op de tweede grond dat Sadalaj en Fowler objectdatabases niet classificeerden als NoSQL (hoewel http://nosql-database.org/ ze in de algemene lijst opneemt), aangezien ze in de jaren 90 zijn gemaakt en nooit veel populariteit hebben gewonnen . .
De NoSQL-beweging wint in een gigantisch tempo aan populariteit. Dit betekent echter niet dat relationele databases rudimentair of iets archaïsch worden. Hoogstwaarschijnlijk zullen ze actief worden gebruikt en gebruikt zoals voorheen, maar steeds meer NoSQL-databases zullen ermee in symbiose werken. We betreden een tijdperk van polyglotpersistentie, een tijdperk waarin verschillende datastores worden gebruikt voor verschillende behoeften. Nu is er geen monopolie op relationele databases als onbetwiste gegevensbron. Steeds vaker kiezen architecten voor opslag op basis van de aard van de gegevens zelf en hoe we deze willen manipuleren, welke hoeveelheden informatie er worden verwacht. En zo wordt alles alleen maar interessanter.
Hieronder zullen we proberen de werking van een gedistribueerde database te begrijpen met behulp van de NoSQL Cassandra DBMS als voorbeeld ...