3.1. Faibles propriétés ACID
Pendant longtemps, la cohérence des données a été une vache sacrée pour les architectes et les développeurs. Toutes les bases de données relationnelles offraient un certain niveau d'isolement, soit par le biais de verrous de mise à jour et de blocages de lecture, soit par le biais de journaux d'annulation. Avec l'avènement d'énormes quantités d'informations et de systèmes distribués, il est devenu évident qu'il était impossible de leur assurer un ensemble transactionnel d'opérations, d'une part, et d'obtenir une haute disponibilité et un temps de réponse rapide, d'autre part.
De plus, même la mise à jour d'un enregistrement ne garantit pas qu'un autre utilisateur verra instantanément les changements dans le système, car le changement peut se produire, par exemple, dans le nœud maître, et la réplique est copiée de manière asynchrone sur le nœud esclave, avec lequel un autre utilisateur travaux. Dans ce cas, il verra le résultat après un certain laps de temps. C'est ce qu'on appelle la cohérence éventuelle et c'est ce que font maintenant toutes les plus grandes sociétés Internet du monde, y compris Facebook et Amazon. Ces derniers déclarent fièrement que l'intervalle maximum pendant lequel l'utilisateur peut voir des données incohérentes n'est pas supérieur à une seconde. Un exemple d'une telle situation est illustré dans la figure:
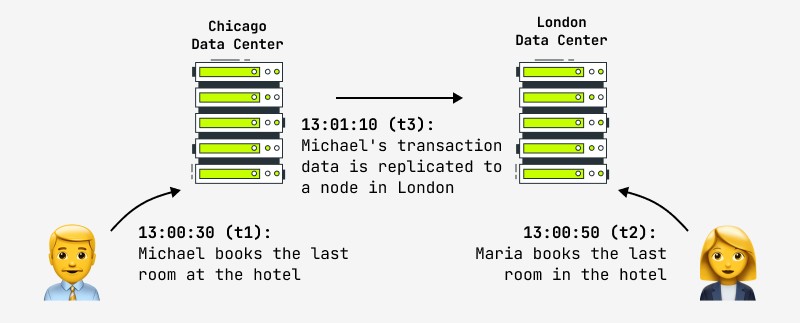
La question logique qui se pose dans une telle situation est de savoir quoi faire avec des systèmes qui imposent classiquement des exigences élevées sur l'atomicité-cohérence des opérations et en même temps ont besoin de clusters distribués rapides - financiers, magasins en ligne, etc. ? La pratique montre que ces exigences ne sont plus d'actualité : voici ce qu'a dit un concepteur du système bancaire financier : « Si nous attendions vraiment la réalisation de chaque transaction dans le réseau mondial des guichets automatiques (GAB), les transactions prendraient tellement de temps que les clients s'enfuirait de rage. Que se passe-t-il si vous et votre partenaire retirez de l'argent en même temps et dépassez la limite ? "Vous recevrez tous les deux l'argent, et nous réglerons le problème plus tard."

Un autre exemple est la réservation d'hôtel montrée dans l'image. Les magasins en ligne dont la politique de données suppose une éventuelle cohérence sont tenus de fournir des mesures en cas de telles situations (résolution automatique des conflits, opération de restauration, mise à jour avec d'autres données). En pratique, les hôtels essaient toujours de garder un « pool » de chambres libres en cas d'urgence, et cela peut être une solution à une situation controversée.
En fait, des propriétés ACID faibles ne signifient pas qu'elles n'existent pas du tout. Dans la plupart des cas, une application travaillant avec une base de données relationnelle utilise une transaction pour modifier des objets logiquement liés (commande - articles de commande), ce qui est nécessaire, car il s'agit de tables différentes. Avec la conception correcte du modèle de données dans une base de données NoSQL (un agrégat est une commande avec une liste d'éléments de commande), vous pouvez atteindre le même niveau d'isolement lors de la modification d'un seul enregistrement que dans une base de données relationnelle.
3.2. Systèmes distribués, pas de ressources partagées (ne rien partager)
Encore une fois, cela ne s'applique pas aux graphes de base de données, dont la structure, par définition, ne se propage pas bien sur les nœuds distants.
C'est peut-être le principal leitmotiv du développement des bases de données NoSQL. Avec l'avalanche d'informations dans le monde et la nécessité de les traiter dans un délai raisonnable, le problème de l'évolutivité verticale s'est posé - la croissance de la vitesse du processeur s'est arrêtée à 3,5 GHz, la vitesse de lecture du disque augmente également à un rythme lent, de plus le prix d'un serveur puissant est toujours supérieur au prix total de plusieurs serveurs simples. Dans cette situation, les bases de données relationnelles conventionnelles, même regroupées sur une matrice de disques, ne sont pas en mesure de résoudre le problème de vitesse, d'évolutivité et de débit.
La seule issue à la situation est la mise à l'échelle horizontale, lorsque plusieurs serveurs indépendants sont connectés par un réseau rapide et que chacun ne possède/traite qu'une partie des données et/ou qu'une partie des requêtes de lecture-mise à jour. Dans cette architecture, pour augmenter la capacité de stockage (capacité, temps de réponse, débit), il suffit d'ajouter un nouveau serveur au cluster - et c'est tout. Sharding, réplication, tolérance aux pannes (le résultat sera obtenu même si un ou plusieurs serveurs cessent de répondre), la redistribution des données en cas d'ajout de nœud est gérée par la base de données NoSQL elle-même.
Je vais présenter brièvement les principales propriétés des bases de données NoSQL distribuées :
Réplication - copie des données vers d'autres nœuds lors de la mise à jour. Permet à la fois d'atteindre une plus grande évolutivité et d'augmenter la disponibilité et la sécurité des données. Il est d'usage de subdiviser en deux types:
maître-esclave : et poste à poste :
et poste à poste : 
Le premier type suppose une bonne évolutivité pour la lecture (peut se produire à partir de n'importe quel nœud), mais une écriture non évolutive (uniquement vers le nœud maître). Il existe également des subtilités pour assurer une disponibilité constante (en cas de panne principale, manuellement ou automatiquement, l'un des nœuds restants est affecté à sa place). Le deuxième type de réplication suppose que tous les nœuds sont égaux et peuvent servir à la fois les requêtes de lecture et d'écriture.
Le sharding est la division des données par nœuds :

Le sharding était souvent utilisé comme « béquille » pour les bases de données relationnelles afin d'augmenter la vitesse et le débit : l'application utilisateur partitionnait les données sur plusieurs bases de données indépendantes et, lorsque l'utilisateur demandait les données correspondantes, accédait à une base de données spécifique. Dans les bases de données NoSQL, le sharding, comme la réplication, est effectué automatiquement par la base de données elle-même et l'application utilisateur est séparée de ces mécanismes complexes.
3.3. Les bases de données NoSQL sont pour la plupart open source et créées au 21ème siècle
C'est sur le deuxième terrain que Sadalaj et Fowler n'ont pas classé les bases de données d'objets comme NoSQL (bien que http://nosql-database.org/ les inclut dans la liste générale), puisqu'elles ont été créées dans les années 90 et n'ont jamais gagné beaucoup de popularité . .
Le mouvement NoSQL gagne en popularité à un rythme gigantesque. Cependant, cela ne signifie pas que les bases de données relationnelles deviennent des vestiges ou quelque chose d'archaïque. Très probablement, ils seront utilisés et utilisés activement comme avant, mais de plus en plus de bases de données NoSQL agiront en symbiose avec eux. Nous entrons dans une ère de persistance polyglotte, une ère où différents magasins de données sont utilisés pour différents besoins. Désormais, il n'y a plus de monopole sur les bases de données relationnelles en tant que source incontestée de données. De plus en plus, les architectes choisissent le stockage en fonction de la nature des données elles-mêmes et de la manière dont nous voulons les manipuler, des volumes d'informations attendus. Et donc tout devient plus intéressant.
Ci-dessous nous allons essayer de comprendre le fonctionnement d'une base de données distribuée en utilisant le SGBD NoSQL Cassandra comme exemple...