3.1. Proprietà ACIDE deboli
Per molto tempo, la coerenza dei dati è stata una vacca sacra per architetti e sviluppatori. Tutti i database relazionali fornivano un certo livello di isolamento, tramite blocchi di aggiornamento e letture di blocco o tramite registri di annullamento. Con l'avvento di enormi quantità di informazioni e sistemi distribuiti, è diventato chiaro che era impossibile garantire loro un insieme transazionale di operazioni, da un lato, e ottenere un'elevata disponibilità e tempi di risposta rapidi, dall'altro.
Inoltre, anche l'aggiornamento di un record non garantisce che qualsiasi altro utente vedrà immediatamente i cambiamenti nel sistema, poiché il cambiamento può verificarsi, ad esempio, nel nodo master e la replica viene copiata in modo asincrono nel nodo slave, con cui un altro utente lavori. In questo caso, vedrà il risultato dopo un certo periodo di tempo. Questa si chiama coerenza finale ed è ciò che stanno facendo ora tutte le più grandi società Internet del mondo, inclusi Facebook e Amazon. Questi ultimi dichiarano con orgoglio che l'intervallo massimo durante il quale l'utente può vedere dati incoerenti non è superiore a un secondo. Un esempio di tale situazione è mostrato nella figura:
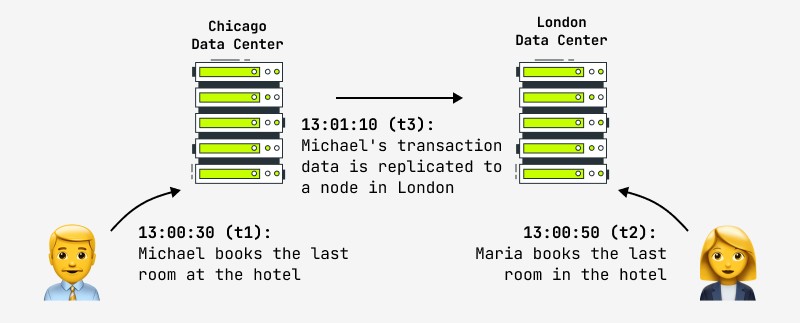
La domanda logica che sorge in una situazione del genere è cosa fare con i sistemi che pongono classicamente requisiti elevati sull'atomicità-coerenza delle operazioni e allo stesso tempo necessitano di cluster distribuiti rapidamente: finanziari, negozi online, ecc.? La pratica dimostra che questi requisiti non sono più rilevanti: ecco cosa ha detto un progettista del sistema bancario finanziario: "Se davvero aspettassimo il completamento di ogni transazione nella rete globale di ATM (ATM), le transazioni richiederebbero così tanto tempo che i clienti scapperebbe infuriato. Cosa succede se tu e il tuo partner prelevate denaro contemporaneamente e superate il limite? "Entrambi riceverete i soldi e lo ripareremo più tardi."

Un altro esempio è la prenotazione alberghiera mostrata nella foto. I negozi online la cui politica sui dati presuppone un'eventuale coerenza sono tenuti a fornire misure in caso di tali situazioni (risoluzione automatica dei conflitti, rollback delle operazioni, aggiornamento con altri dati). In pratica, gli hotel cercano sempre di mantenere un "pool" di camere libere in caso di emergenza, e questa può essere una soluzione a una situazione controversa.
In effetti, le proprietà ACID deboli non significano che non esistano affatto. Nella maggior parte dei casi, un'applicazione che lavora con un database relazionale utilizza una transazione per modificare oggetti logicamente correlati (ordine - elementi dell'ordine), il che è necessario, poiché si tratta di tabelle diverse. Con la progettazione corretta del modello di dati in un database NoSQL (un aggregato è un ordine insieme a un elenco di elementi dell'ordine), è possibile ottenere lo stesso livello di isolamento quando si modifica un singolo record come in un database relazionale.
3.2. Sistemi distribuiti, nessuna risorsa condivisa (non condividere nulla)
Ancora una volta, questo non si applica ai grafici del database, la cui struttura, per definizione, non si diffonde bene tra i nodi remoti.
Questo è forse il leitmotiv principale dello sviluppo dei database NoSQL. Con la crescita a valanga delle informazioni nel mondo e la necessità di elaborarle in un tempo ragionevole, è sorto il problema della scalabilità verticale: la crescita della velocità del processore si è fermata a 3,5 GHz, anche la velocità di lettura dal disco sta crescendo a un ritmo lento, inoltre il prezzo di un server potente è sempre superiore al prezzo totale di diversi server semplici. In questa situazione, i database relazionali convenzionali, anche raggruppati su un array di dischi, non sono in grado di risolvere il problema della velocità, della scalabilità e del throughput.
L'unica via d'uscita dalla situazione è il ridimensionamento orizzontale, quando più server indipendenti sono collegati da una rete veloce e ognuno possiede/elabora solo una parte dei dati e/o solo una parte delle richieste di lettura-aggiornamento. In questa architettura, per aumentare la capacità di archiviazione (capacità, tempo di risposta, throughput), è sufficiente aggiungere un nuovo server al cluster, e il gioco è fatto. Lo sharding, la replica, la tolleranza ai guasti (il risultato si otterrà anche se uno o più server smettono di rispondere), la ridistribuzione dei dati in caso di aggiunta di un nodo è gestita dal database NoSQL stesso.
Presenterò brevemente le principali proprietà dei database NoSQL distribuiti:
Replica: copia dei dati su altri nodi durante l'aggiornamento. Consente sia di ottenere una maggiore scalabilità sia di aumentare la disponibilità e la sicurezza dei dati. È consuetudine suddividere in due tipi:
master-slave : e peer-to-peer :
e peer-to-peer : 
Il primo tipo presuppone una buona scalabilità per la lettura (può avvenire da qualsiasi nodo), ma una scrittura non scalabile (solo per il nodo master). Ci sono anche sottigliezze nel garantire una disponibilità costante (in caso di arresto anomalo del master, manualmente o automaticamente uno dei nodi rimanenti viene assegnato al suo posto). Il secondo tipo di replica presuppone che tutti i nodi siano uguali e possano soddisfare sia le richieste di lettura che quelle di scrittura.
Lo sharding è la divisione dei dati per nodi:

Lo sharding veniva spesso utilizzato come "stampella" per i database relazionali al fine di aumentare la velocità e il throughput: l'applicazione utente partizionava i dati su diversi database indipendenti e, quando l'utente richiedeva i dati corrispondenti, accedeva a un database specifico. Nei database NoSQL, lo sharding, come la replica, viene eseguito automaticamente dal database stesso e l'applicazione utente è separata da questi complessi meccanismi.
3.3. I database NoSQL sono per lo più open source e creati nel 21° secolo
È in secondo luogo che Sadalaj e Fowler non hanno classificato i database di oggetti come NoSQL (sebbene http://nosql-database.org/ li includa nell'elenco generale), poiché sono stati creati negli anni '90 e non hanno mai guadagnato molta popolarità . .
Il movimento NoSQL sta guadagnando popolarità a un ritmo gigantesco. Tuttavia, ciò non significa che i database relazionali stiano diventando rudimentali o qualcosa di arcaico. Molto probabilmente verranno utilizzati e utilizzati attivamente come prima, ma sempre più database NoSQL agiranno in simbiosi con essi. Stiamo entrando in un'era di persistenza poliglotta, un'era in cui diversi archivi di dati vengono utilizzati per esigenze diverse. Ora non esiste il monopolio dei database relazionali come fonte incontestata di dati. Sempre più spesso gli architetti scelgono l'archiviazione in base alla natura dei dati stessi e al modo in cui vogliamo manipolarli, ai volumi di informazioni previsti. E così tutto diventa più interessante.
Di seguito cercheremo di comprendere il funzionamento di un database distribuito utilizzando come esempio il DBMS NoSQL Cassandra...