3.1. Propriedades ACID fracas
Por muito tempo, a consistência de dados foi uma vaca sagrada para arquitetos e desenvolvedores. Todos os bancos de dados relacionais fornecem algum nível de isolamento, seja por meio de bloqueios de atualização e leituras de bloqueio ou por meio de logs de desfazer. Com o advento de enormes quantidades de informações e sistemas distribuídos, ficou claro que era impossível garantir um conjunto transacional de operações para eles, por um lado, e obter alta disponibilidade e tempo de resposta rápido, por outro.
Além disso, mesmo atualizar um registro não garante que qualquer outro usuário veja instantaneamente as alterações no sistema, porque a alteração pode ocorrer, por exemplo, no nó mestre, e a réplica é copiada de forma assíncrona para o nó escravo, com o qual outro usuário funciona. Nesse caso, ele verá o resultado após um determinado período de tempo. Isso é chamado de consistência eventual e é para isso que todas as maiores empresas de Internet do mundo estão indo agora, incluindo Facebook e Amazon. Estes declaram orgulhosamente que o intervalo máximo durante o qual o usuário pode ver dados inconsistentes não passa de um segundo. Um exemplo dessa situação é mostrado na figura:
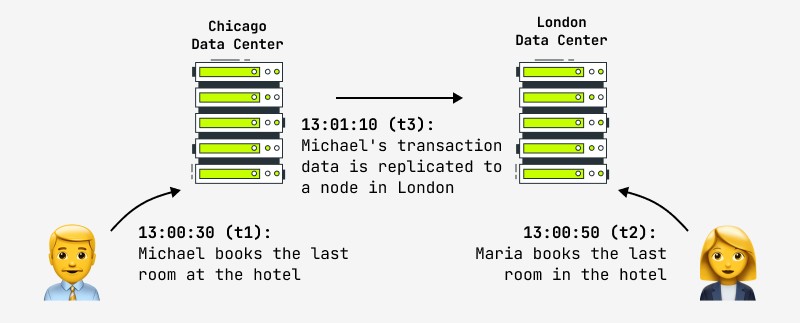
A questão lógica que surge em tal situação é o que fazer com sistemas que classicamente colocam altas demandas na consistência de atomicidade das operações e ao mesmo tempo precisam de clusters distribuídos rapidamente - financeiro, lojas online, etc.? A prática mostra que esses requisitos não são mais relevantes: eis o que disse um projetista do sistema bancário financeiro: “Se realmente esperássemos a conclusão de cada transação na rede global de caixas eletrônicos (ATMs), as transações demorariam tanto que os clientes fugiria furioso. O que acontece se você e seu parceiro sacarem dinheiro ao mesmo tempo e ultrapassarem o limite? “Vocês dois receberão o dinheiro e nós o consertaremos mais tarde.”

Outro exemplo é a reserva de hotel mostrada na foto. As lojas online cuja política de dados assuma consistência eventual são obrigadas a providenciar medidas no caso de tais situações (resolução automática de conflitos, reversão da operação, atualização com outros dados). Na prática, os hotéis sempre procuram manter um “pool” de quartos livres para o caso de uma emergência, e isso pode ser uma solução para uma situação polêmica.
Na verdade, propriedades ACID fracas não significam que elas não existam. Na maioria dos casos, um aplicativo que trabalha com um banco de dados relacional usa uma transação para alterar objetos logicamente relacionados (pedido - itens do pedido), o que é necessário, pois são tabelas diferentes. Com o design correto do modelo de dados em um banco de dados NoSQL (um agregado é um pedido junto com uma lista de itens do pedido), você pode obter o mesmo nível de isolamento ao alterar um único registro como em um banco de dados relacional.
3.2. Sistemas distribuídos, sem recursos compartilhados (não compartilham nada)
Novamente, isso não se aplica a grafos de banco de dados, cuja estrutura, por definição, não se espalha bem pelos nós remotos.
Este é talvez o principal leitmotiv do desenvolvimento de bancos de dados NoSQL. Com o crescimento avalanche de informações no mundo e a necessidade de processá-las em um tempo razoável, surgiu o problema da escalabilidade vertical - o crescimento da velocidade do processador parou em 3,5 GHz, a velocidade de leitura do disco também está crescendo a uma velocidade ritmo lento, mais o preço de um servidor poderoso é sempre mais do que o preço total de vários servidores simples. Nesta situação, bancos de dados relacionais convencionais, mesmo agrupados em um array de discos, não são capazes de resolver o problema de velocidade, escalabilidade e throughput.
A única saída é o dimensionamento horizontal, quando vários servidores independentes são conectados por uma rede rápida e cada um possui/processa apenas parte dos dados e/ou apenas parte das solicitações de atualização de leitura. Nessa arquitetura, para aumentar a capacidade de armazenamento (capacidade, tempo de resposta, throughput), basta adicionar um novo servidor ao cluster - e pronto. Sharding, replicação, tolerância a falhas (o resultado será obtido mesmo que um ou mais servidores parem de responder), redistribuição de dados em caso de adição de um nó é feito pelo próprio banco de dados NoSQL.
Vou apresentar brevemente as principais propriedades dos bancos de dados NoSQL distribuídos:
Replicação - copiar dados para outros nós durante a atualização. Permite alcançar maior escalabilidade e aumentar a disponibilidade e segurança dos dados. Costuma-se subdividir em dois tipos:
mestre-escravo : e ponto a ponto :
e ponto a ponto : 
O primeiro tipo assume boa escalabilidade para leitura (pode acontecer de qualquer nó), mas escrita não escalável (somente para o nó mestre). Também existem sutilezas em garantir a disponibilidade constante (no caso de uma falha do mestre, manual ou automaticamente, um dos nós restantes é atribuído ao seu lugar). O segundo tipo de replicação assume que todos os nós são iguais e podem atender a solicitações de leitura e gravação.
Sharding é a divisão de dados por nós:

O sharding costumava ser usado como uma “muleta” para os bancos de dados relacionais, a fim de aumentar a velocidade e o throughput: o aplicativo do usuário particionava os dados em vários bancos de dados independentes e, quando o usuário solicitava os dados correspondentes, acessava um banco de dados específico. Em bancos de dados NoSQL, o sharding, como a replicação, é feito automaticamente pelo próprio banco de dados e o aplicativo do usuário é separado desses mecanismos complexos.
3.3. Os bancos de dados NoSQL são em sua maioria de código aberto e criados no século XXI
É no segundo fundamento que Sadalaj e Fowler não classificaram os bancos de dados de objetos como NoSQL (embora http://nosql-database.org/ os inclua na lista geral), uma vez que foram criados nos anos 90 e nunca ganharam muita popularidade .
O movimento NoSQL está ganhando popularidade em um ritmo gigantesco. No entanto, isso não significa que os bancos de dados relacionais estejam se tornando vestigiais ou algo arcaico. Muito provavelmente eles serão usados e usados como antes ativamente, mas cada vez mais bancos de dados NoSQL atuarão em simbiose com eles. Estamos entrando em uma era de persistência poliglota, uma era em que diferentes armazenamentos de dados são usados para diferentes necessidades. Agora não há monopólio de bancos de dados relacionais como uma fonte incontestável de dados. Cada vez mais, os arquitetos escolhem o armazenamento com base na natureza dos próprios dados e como queremos manipulá-los, quais volumes de informações são esperados. E assim tudo fica mais interessante.
Abaixo tentaremos entender o funcionamento de um banco de dados distribuído utilizando como exemplo o SGBD NoSQL Cassandra...