3.1. Weak ACID properties
For a long time, data consistency has been a sacred cow for architects and developers. All relational databases provided some level of isolation, either through update locks and blocking reads, or through undo logs. With the advent of huge amounts of information and distributed systems, it became clear that it was impossible to ensure a transactional set of operations for them, on the one hand, and to obtain high availability and fast response time, on the other.
Moreover, even updating one record does not guarantee that any other user will instantly see changes in the system, because the change can occur, for example, in the master node, and the replica is asynchronously copied to the slave node, with which another user works. In this case, he will see the result after a certain period of time. This is called eventual consistency and this is what all the largest Internet companies in the world are going to now, including Facebook and Amazon. The latter proudly declare that the maximum interval during which the user can see inconsistent data is no more than a second. An example of such a situation is shown in the figure:
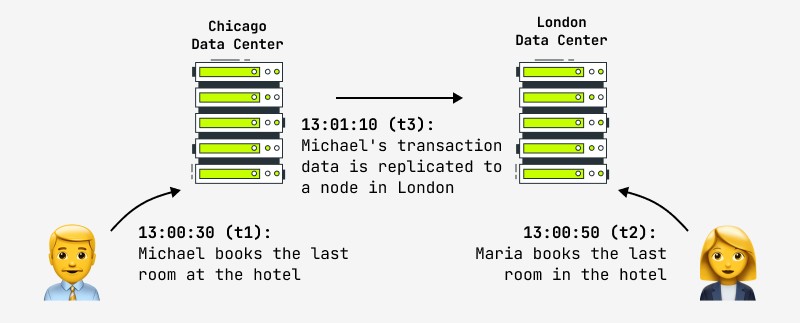
The logical question that arises in such a situation is what to do with systems that classically place high demands on the atomicity-consistency of operations and at the same time need fast distributed clusters - financial, online stores, etc.? Practice shows that these requirements are no longer relevant: here is what one designer of the financial banking system said: “If we really waited for the completion of each transaction in the global network of ATMs (ATMs), transactions would take so long that customers would run away in a rage. What happens if you and your partner withdraw money at the same time and exceed the limit? “You will both get the money, and we will fix it later.”

Another example is the hotel booking shown in the picture. Online stores whose data policy assumes eventual consistency are required to provide measures in case of such situations (automatic conflict resolution, operation rollback, update with other data). In practice, hotels always try to keep a “pool” of free rooms in case of an emergency, and this can be a solution to a controversial situation.
In fact, weak ACID properties do not mean that they do not exist at all. In most cases, an application working with a relational database uses a transaction to change logically related objects (order - order items), which is necessary, since these are different tables. With the correct design of the data model in a NoSQL database (an aggregate is an order along with a list of order items), you can achieve the same level of isolation when changing a single record as in a relational database.
3.2. Distributed systems, no shared resources (share nothing)
Again, this does not apply to database graphs, whose structure, by definition, does not spread well across remote nodes.
This is perhaps the main leitmotif of the development of NoSQL databases. With the avalanche growth of information in the world and the need to process it in a reasonable time, the problem of vertical scalability arose - the growth of the processor speed stopped at 3.5 GHz, the speed of reading from the disk is also growing at a slow pace, plus the price of a powerful server is always more than the total price of several simple servers. In this situation, conventional relational databases, even clustered on an array of disks, are not able to solve the problem of speed, scalability and throughput.
The only way out of the situation is horizontal scaling, when several independent servers are connected by a fast network and each owns / processes only part of the data and / or only part of the read-update requests. In this architecture, to increase storage capacity (capacity, response time, throughput), you only need to add a new server to the cluster - and that's it. Sharding, replication, fault tolerance (the result will be obtained even if one or more servers stop responding), data redistribution in case of adding a node is handled by the NoSQL database itself.
I will briefly present the main properties of distributed NoSQL databases:
Replication - copying data to other nodes when updating. Allows both to achieve greater scalability and increase the availability and safety of data. It is customary to subdivide into two types:
master-slave : and peer-to-peer :
and peer-to-peer :

The first type assumes good scalability for reading (can happen from any node), but non-scalable writing (only to the master node). There are also subtleties with ensuring constant availability (in the event of a master crash, either manually or automatically one of the remaining nodes is assigned to its place). The second type of replication assumes that all nodes are equal and can serve both read and write requests.
Sharding is the division of data by nodes:

Sharding was often used as a “crutch” to relational databases in order to increase speed and throughput: the user application partitioned data across several independent databases and, when the user requested the corresponding data, accessed a specific database. In NoSQL databases, sharding, like replication, is done automatically by the database itself and the user application is separate from these complex mechanisms.
3.3. NoSQL databases are mostly open source and created in the 21st century
It is on the second ground that Sadalaj and Fowler did not classify object databases as NoSQL (although http://nosql-database.org/ includes them in the general list), since they were created back in the 90s and never gained much popularity. .
The NoSQL movement is gaining popularity at a gigantic pace. However, this does not mean that relational databases are becoming vestigial or something archaic. Most likely they will be used and used as before actively, but more and more NoSQL databases will act in symbiosis with them. We are entering an era of polyglot persistence, an era where different data stores are used for different needs. Now there is no monopoly of relational databases as an uncontested source of data. Increasingly, architects choose storage based on the nature of the data itself and how we want to manipulate it, what volumes of information are expected. And so everything just gets more interesting.
Below we will try to understand the operation of a distributed database using the NoSQL Cassandra DBMS as an example ...