3.1. 弱酸性
長期以來,數據一致性一直是架構師和開發人員的聖牛。所有關係數據庫都提供了某種程度的隔離,要么通過更新鎖和阻塞讀取,要么通過撤消日誌。隨著海量信息和分佈式系統的出現,很明顯,一方面要為它們確保一組事務性操作,另一方面要獲得高可用性和快速響應時間是不可能的。
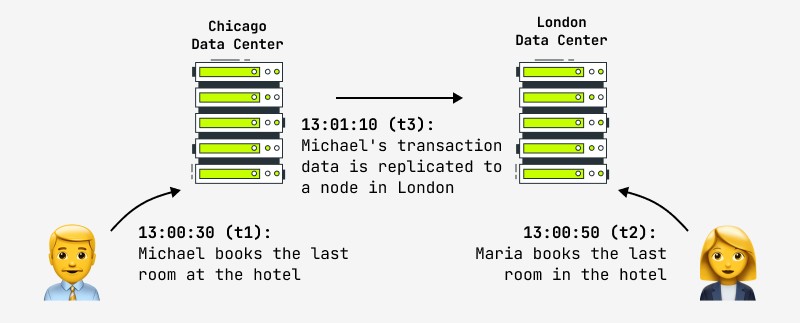
此外,即使更新一條記錄也不能保證任何其他用戶會立即看到系統中的更改,因為更改可能發生在例如主節點中,並且副本被異步複製到從節點,另一個用戶可以使用該從節點作品。在這種情況下,他將在一定時間後看到結果。這就是所謂的最終一致性,這就是世界上所有最大的互聯網公司現在都在做的事情,包括 Facebook 和亞馬遜。後者自豪地宣稱,用戶可以看到不一致數據的最大間隔不超過一秒。這種情況的一個例子如圖所示:
在這種情況下出現的邏輯問題是,如何處理通常對操作的原子性一致性提出高要求同時需要快速分佈式集群的系統——金融、在線商店等?實踐表明,這些要求不再適用:金融銀行系統的一位設計者說:“如果我們真的等待全球自動取款機 (ATM) 網絡中的每筆交易完成,交易將花費很長時間,以至於客戶會一怒之下逃跑。如果您和您的伴侶同時取款並超過限額會怎樣?“你們都會得到錢,我們稍後會解決它。”

另一個例子是圖中所示的酒店預訂。數據策略假定最終一致性的在線商店需要提供針對此類情況的措施(自動衝突解決、操作回滾、與其他數據更新)。在實踐中,酒店總是試圖保留一個空閑房間“池”以備不時之需,這可能是解決爭議情況的一種方法。
事實上,弱的ACID特性並不意味著它們根本不存在。在大多數情況下,使用關係數據庫的應用程序使用事務來更改邏輯上相關的對象(訂單 - 訂單項目),這是必要的,因為這些是不同的表。通過在 NoSQL 數據庫中正確設計數據模型(聚合是一個訂單和一個訂單項列表),您可以在更改單個記錄時實現與在關係數據庫中相同的隔離級別。
3.2. 分佈式系統,沒有共享資源(share nothing)
同樣,這不適用於數據庫圖,根據定義,其結構不能很好地跨遠程節點傳播。
這也許是 NoSQL 數據庫開發的主要主題。隨著世界上信息的雪崩式增長以及在合理時間內處理信息的需要,垂直可擴展性的問題出現了——處理器速度的增長停止在 3.5 GHz,從磁盤讀取的速度也在以 3.5 GHz 的速度增長速度慢,再加上一台功能強大的服務器的價格總是比幾台簡單的服務器總價還高。在這種情況下,傳統的關係數據庫,即使是集群在磁盤陣列上,也無法解決速度、可擴展性和吞吐量的問題。
解決這種情況的唯一方法是水平擴展,當多個獨立服務器通過快速網絡連接並且每個服務器僅擁有/處理部分數據和/或僅部分讀取更新請求時。在這個架構中,要增加存儲容量(容量、響應時間、吞吐量),你只需要向集群添加一個新的服務器——僅此而已。分片、複製、容錯(即使一台或多台服務器停止響應也會得到結果)、添加節點時的數據重新分配由NoSQL數據庫自己處理。
我將簡要介紹分佈式 NoSQL 數據庫的主要特性:
複製——更新時將數據複製到其他節點。允許既實現更大的可擴展性又增加數據的可用性和安全性。習慣上分為兩種:
主從: 和點對點:
和點對點: 
第一種類型假定讀取具有良好的可擴展性(可以從任何節點發生),但不可擴展的寫入(僅對主節點)。在確保持續可用性方面也有一些微妙之處(在主節點崩潰的情況下,手動或自動將剩餘節點之一分配到它的位置)。第二種類型的複制假設所有節點都是平等的,並且可以服務於讀取和寫入請求。
分片是按節點劃分數據:

分片通常用作關係數據庫的“拐杖”以提高速度和吞吐量:用戶應用程序將數據分區到幾個獨立的數據庫中,當用戶請求相應的數據時,訪問特定的數據庫。在 NoSQL 數據庫中,分片與復制一樣,是由數據庫本身自動完成的,用戶應用程序與這些複雜的機制是分開的。
3.3. NoSQL 數據庫大多是開源的,創建於 21 世紀
基於第二個理由,Sadalaj 和 Fowler 沒有將對像數據庫歸類為 NoSQL(儘管 http://nosql-database.org/ 將它們包含在一般列表中),因為它們是在 90 年代創建的並且從未獲得太多流行. .
NoSQL 運動正以驚人的速度流行起來。然而,這並不意味著關係數據庫正在變得過時或過時。它們很可能會像以前一樣被積極使用和使用,但越來越多的 NoSQL 數據庫將與它們共生。我們正在進入一個多語言持久化時代,一個不同數據存儲用於不同需求的時代。現在沒有關係數據庫作為無可爭議的數據源的壟斷。越來越多的架構師根據數據本身的性質、我們希望如何操作它以及預期的信息量來選擇存儲。所以一切都變得更有趣了。
下面我們將嘗試以 NoSQL Cassandra DBMS 為例來了解分佈式數據庫的操作......