5.1 Разпределение на данни
Нека разгледаме How данните се разпределят в зависимост от ключа между възлите на клъстера. Cassandra ви позволява да зададете стратегия за разпространение на данни. Първата такава стратегия разпределя данни в зависимост от стойността на ключа md5 - случаен разделител. Вторият взема предвид битовото представяне на самия ключ - порядковия маркиране (byte-ordered partitioner).
Първата стратегия в по-голямата си част дава повече предимства, тъй като не е нужно да се притеснявате за равномерното разпределение на данните между сървърите и подобни проблеми. Втората стратегия се използва в редки случаи, например, ако са необходими интервални заявки (сканиране на диапазон). Важно е да се отбележи, че изборът на тази стратегия се прави преди създаването на клъстера и всъщност не може да бъде променен без пълно презареждане на данните.
Cassandra използва техника, известна като последователно хеширане, за да разпространява данни. Този подход ви позволява да разпределяте данни между възли и да се уверите, че когато се добавя и премахва нов възел, количеството прехвърлени данни е малко. За да направите това, на всеки възел се присвоява етикет (токен), който разделя набора от всички стойности на md5 ключ на части. Тъй като RandomPartitioner се използва в повечето случаи, нека го разгледаме.
Както казах, RandomPartitioner изчислява 128-битов md5 за всеки ключ. За да се определи в кои възли ще се съхраняват данните, той просто преминава през всички етикети на възлите от най-малкия до най-големия и когато стойността на етикета стане по-голяма от стойността на ключа md5, тогава този възел, заедно с брой следващи възли (по реда на етикетите) е избран за съхранение. Общият брой избрани възли трябва да бъде equals на коефициента на репликация. Нивото на репликация е зададено за всяко пространство на ключове и ви позволява да регулирате излишъка на данните (редундантиране на данни).


Преди възел да може да бъде добавен към клъстера, той трябва да получи етикет. Процентът на ключовете, които покриват празнината между този етикет и следващия, определя колко данни ще се съхраняват на възела. Целият набор от етикети за клъстер се нарича пръстен.
Ето илюстрация, използваща вградената помощна програма nodetool за показване на клъстерен пръстен от 6 възела с равномерно разположени етикети.

5.2 Съгласуваност на данните при писане
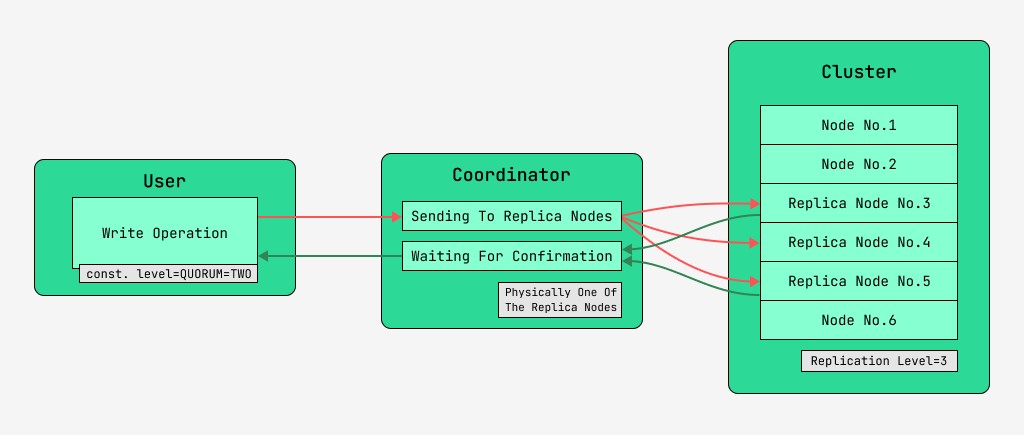
Клъстерните възли на Cassandra са еквивалентни и клиентите могат да се свързват към всеки от тях, Howто за писане, така и за четене. Заявките преминават през етапа на координация, по време на който, след като установи с помощта на ключа и маркирането на кои възли трябва да бъдат разположени данните, сървърът изпраща заявки до тези възли. Ще наречем възела, който извършва координация координатор , а възлите, които са избрани да запазят записа с дадения ключ, възлите на репликата . Физически един от възлите на репликата може да бъде координатор - зависи само от ключа, маркирането и етикетите.
За всяка заявка, Howто за четене, така и за запис, е възможно да се зададе ниво на съгласуваност на данните.
За запис това ниво ще повлияе на броя възли на реплики, които ще чакат потвърждение за успешно завършване на операцията (записани данни), преди да върнат контрола на потребителя. За протокол има следните нива на последователност:
- ONE - координаторът изпраща заявки до всички реплики на възли, но след като изчака потвърждение от първия възел, връща контрола на потребителя;
- TWO - същото, но координаторът чака потвърждение от първите два възела, преди да върне управлението;
- THREE - подобно, но координаторът чака потвърждение от първите три възела, преди да върне контрола;
- КВОРУМ - кворумът е събран: координаторът чака потвърждение на записа от повече от половината възли на реплика, а именно кръг (N / 2) + 1, където N е нивото на репликация;
- LOCAL_QUORUM - Координаторът чака потвърждение от повече от половината възли на реплика в същия център за данни, където се намира координаторът (потенциално различно за всяка заявка). Позволява ви да се отървете от закъсненията, свързани с изпращането на данни към други центрове за данни. Въпросите за работа с много центрове за данни се разглеждат в тази статия мимоходом;
- EACH_QUORUM – Координаторът чака потвърждение от повече от половината реплики възли във всеки център за данни, независимо;
- ВСИЧКИ - координаторът чака потвърждение от всички реплики на възли;
- ANY - прави възможно записването на данни, дори ако всички реплики възли не отговарят. Координаторът изчаква or първия отговор от един от възлите на репликата, or данните да бъдат съхранени с помощта на намекнато предаване на координатора.
5.3 Съгласуваност на данните при четене
За четения нивото на съгласуваност ще повлияе на броя възли на реплика, от които ще се чете. За четене има следните нива на последователност:
- ONE - координаторът изпраща заявки до най-близкия възел на реплика. Останалите реплики също се четат за поправка на четене с вероятността, посочена в конфигурацията на cassandra;
- TWO е същото, но координаторът изпраща заявки до двата най-близки възела. Избира се стойността с най-голямо времево клеймо;
- ТРИ - подобно на предишния вариант, но с три възела;
- КВОРУМ - събира се кворум, т.е. координаторът изпраща заявки до повече от половината възли на реплика, а именно кръг (N / 2) + 1, където N е нивото на репликация;
- LOCAL_QUORUM - събира се кворум в центъра за данни, в който се извършва координацията, и се връщат данните с най-новия времеви печат;
- EACH_QUORUM - Координаторът връща данни след събиране на кворума във всеки от центровете за данни;
- ВСИЧКИ - Координаторът връща данни след четене от всички реплики на възли.

По този начин е възможно да се регулират времезакъсненията на операциите за четене и запис и да се регулира последователността (tune consistency), Howто и наличността (наличността) на всеки тип операция. Всъщност наличността е пряко свързана с нивото на съгласуваност на четенията и записите, тъй като определя колко възли на реплики могат да паднат и все пак да бъдат потвърдени.
Ако броят на възлите, от които идва потвърждението за запис, плюс броя на възлите, от които се извършва четенето, е по-голям от нивото на репликация, тогава имаме гаранция, че новата стойност винаги ще бъде прочетена след записа и това се нарича силна консистенция (силна консистенция). При липса на силна последователност, има възможност операцията за четене да върне остарели данни.
Във всеки случай стойността в крайна сметка ще се разпространи между репликите, но само след като чакането за координация приключи. Това разпространение се нарича евентуална консистенция. Ако не всички реплики на възли са налични по време на записа, тогава рано or късно ще влязат в действие инструменти за възстановяване като коригиращи четения и поправка на възли против ентропия. Повече за това по-късно.
По този начин, с ниво на последователност при четене и запис на QUORUM, винаги ще се поддържа силна последователност и това ще бъде баланс между латентността при четене и запис. При ВСИЧКИ записи и ЕДНО четене ще има силна последователност и четенията ще бъдат по-бързи и по-достъпни, т.е. броят на неуспешните възли, при които четенето все още ще бъде завършено, може да бъде по-голям, отколкото при QUORUM.
За операции по запис ще са необходими всички работни възли на реплики. Когато пишете ЕДНО, четете ВСИЧКИ, също ще има строга последователност и операциите за запис ще бъдат по-бързи и наличността за запис ще бъде голяма, защото ще бъде достатъчно да потвърдите само, че операцията за запис е извършена на поне един от сървърите, докато четенето е по-бавно и изисква всички реплики възли. Ако дадено приложение няма изискване за стриктна последователност, тогава е възможно да се ускорят Howто операциите за четене, така и запис, Howто и да се подобри достъпността чрез задаване на по-ниски нива на последователност.