5.1 데이터 배포
클러스터 노드들 사이에서 키에 따라 데이터가 어떻게 분배되는지 생각해 봅시다. Cassandra를 사용하면 데이터 배포 전략을 설정할 수 있습니다. 첫 번째 전략은 md5 키 값(임의 파티셔너)에 따라 데이터를 배포합니다. 두 번째는 키 자체의 비트 표현인 서수 마크업(바이트 순서 파티셔너)을 고려합니다.
대부분의 경우 첫 번째 전략이 더 많은 이점을 제공합니다. 서버 간 데이터의 균일한 분포 및 이러한 문제에 대해 걱정할 필요가 없기 때문입니다. 두 번째 전략은 예를 들어 간격 쿼리(범위 스캔)가 필요한 경우와 같이 드문 경우에 사용됩니다. 이 전략의 선택은 클러스터 생성 전에 이루어지며 실제로 데이터를 완전히 다시 로드하지 않고는 변경할 수 없다는 점에 유의해야 합니다.
Cassandra는 일관된 해싱이라는 기술을 사용하여 데이터를 배포합니다. 이 접근 방식을 사용하면 노드 간에 데이터를 분산하고 새 노드가 추가 및 제거될 때 전송되는 데이터 양이 적도록 할 수 있습니다. 이를 위해 각 노드에는 모든 md5 키 값 세트를 부분으로 분할하는 레이블(토큰)이 할당됩니다. 대부분의 경우 RandomPartitioner를 사용하므로 고려해보자.
내가 말했듯이 RandomPartitioner는 각 키에 대해 128비트 md5를 계산합니다. 어떤 노드에 데이터를 저장할지 결정하기 위해 가장 작은 것부터 가장 큰 것까지 노드의 모든 레이블을 살펴보고 레이블의 값이 md5 키의 값보다 커지면 이 노드와 후속 노드 수(레이블 순서대로)가 저장을 위해 선택됩니다. 선택한 노드의 총 수는 복제 계수와 같아야 합니다. 복제 수준은 각 키스페이스에 대해 설정되며 데이터의 중복성(데이터 중복성)을 조정할 수 있습니다.


클러스터에 노드를 추가하려면 먼저 레이블을 지정해야 합니다. 이 레이블과 다음 레이블 사이의 간격을 커버하는 키의 백분율은 노드에 저장되는 데이터의 양을 결정합니다. 클러스터의 전체 레이블 집합을 링이라고 합니다.
다음은 내장된 nodetool 유틸리티를 사용하여 균일한 간격의 레이블이 있는 6개 노드의 클러스터 링을 표시하는 그림입니다.

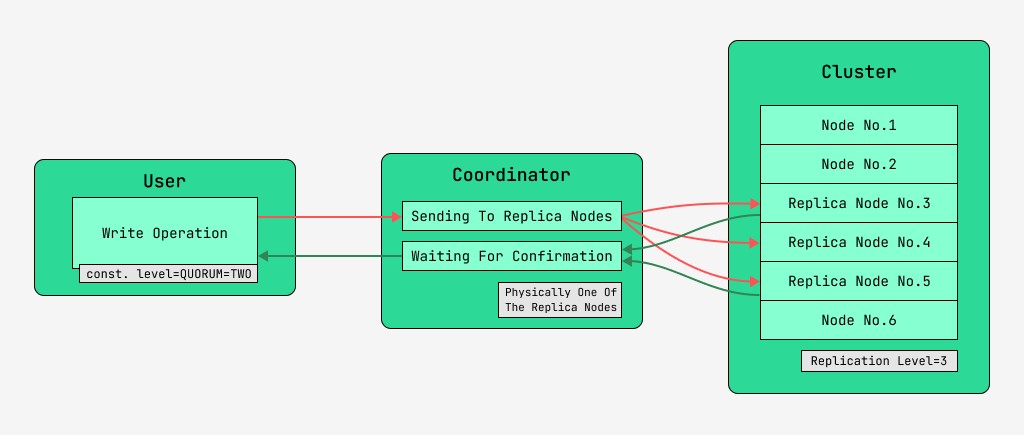
5.2 쓰기 시 데이터 일관성
Cassandra 클러스터 노드는 동일하며 클라이언트는 쓰기 및 읽기를 위해 이들 중 하나에 연결할 수 있습니다. 요청은 조정 단계를 거치며, 그 동안 데이터가 있어야 하는 노드와 키의 도움을 받아 서버가 이러한 노드에 요청을 보냅니다. 조정을 수행하는 노드를 코디네이터라고 하고 , 주어진 키로 레코드를 저장하기 위해 선택된 노드를 레플리카 노드라고 합니다. 물리적으로 복제본 노드 중 하나는 코디네이터가 될 수 있습니다. 코디네이터는 키, 마크업 및 레이블에만 의존합니다.
읽기 및 쓰기에 대한 각 요청에 대해 데이터 일관성 수준을 설정할 수 있습니다.
쓰기의 경우 이 수준은 사용자에게 제어권을 반환하기 전에 작업(기록된 데이터)의 성공적인 완료 확인을 기다리는 복제본 노드 수에 영향을 미칩니다. 레코드의 경우 다음과 같은 일관성 수준이 있습니다.
- ONE - 코디네이터가 모든 복제본 노드에 요청을 보내지만 첫 번째 노드의 확인을 기다린 후 사용자에게 제어권을 반환합니다.
- TWO - 동일하지만 조정자는 제어를 반환하기 전에 처음 두 노드의 확인을 기다립니다.
- THREE - 비슷하지만 조정자는 제어를 반환하기 전에 처음 세 노드의 확인을 기다립니다.
- QUORUM - 쿼럼이 수집됩니다. 코디네이터는 복제 노드의 절반 이상, 즉 라운드(N / 2) + 1에서 레코드 확인을 기다리고 있습니다. 여기서 N은 복제 수준입니다.
- LOCAL_QUORUM - 코디네이터가 코디네이터가 있는 동일한 데이터 센터에 있는 복제본 노드의 절반 이상에서 확인을 기다리고 있습니다(요청마다 다를 수 있음). 다른 데이터 센터로 데이터를 보내는 것과 관련된 지연을 제거할 수 있습니다. 많은 데이터 센터와 함께 작업하는 문제는 이 문서에서 통과적으로 고려됩니다.
- EACH_QUORUM - 코디네이터가 독립적으로 각 데이터 센터의 복제 노드 절반 이상에서 확인을 기다리고 있습니다.
- ALL - 코디네이터는 모든 복제본 노드의 확인을 기다립니다.
- ANY - 모든 복제본 노드가 응답하지 않는 경우에도 데이터를 쓸 수 있습니다. 코디네이터는 복제 노드 중 하나의 첫 번째 응답을 기다리거나 코디네이터에서 암시된 핸드오프를 사용하여 데이터가 저장될 때까지 기다립니다.
5.3 읽을 때 데이터 일관성
읽기의 경우 일관성 수준은 읽을 복제본 노드 수에 영향을 미칩니다. 읽기에는 다음과 같은 일관성 수준이 있습니다.
- ONE - 코디네이터가 가장 가까운 복제본 노드에 요청을 보냅니다. 나머지 복제본도 cassandra 구성에 지정된 확률로 읽기 복구를 위해 읽습니다.
- TWO 는 같지만 코디네이터가 가장 가까운 두 노드에 요청을 보냅니다. 타임스탬프가 가장 큰 값이 선택됩니다.
- THREE - 이전 옵션과 유사하지만 세 개의 노드가 있습니다.
- QUORUM - 쿼럼이 수집됩니다. 즉, 코디네이터가 복제 노드의 절반 이상, 즉 라운드(N / 2) + 1에 요청을 보냅니다. 여기서 N은 복제 수준입니다.
- LOCAL_QUORUM - 조정이 이루어지는 데이터 센터에서 쿼럼이 수집되고 최신 타임스탬프가 있는 데이터가 반환됩니다.
- EACH_QUORUM - 코디네이터는 각 데이터 센터의 정족수 회의 후 데이터를 반환합니다.
- ALL - 코디네이터는 모든 복제본 노드에서 읽은 후 데이터를 반환합니다.

따라서 읽기 및 쓰기 작업의 시간 지연을 조정하고 각 작업 유형의 가용성(availability)뿐만 아니라 일관성(tune consistency)을 조정할 수 있습니다. 실제로 가용성은 읽기 및 쓰기의 일관성 수준과 직접적인 관련이 있습니다. 이는 얼마나 많은 복제본 노드가 중단되고 여전히 확인될 수 있는지를 결정하기 때문입니다.
쓰기 승인이 오는 노드의 수와 읽기가 이루어진 노드의 수를 더한 값이 복제 수준보다 크면 쓰기 후에 항상 새 값을 읽을 것이라는 보장이 있습니다. 강한 일관성 (강한 일관성)이라고합니다. 강력한 일관성이 없으면 읽기 작업이 오래된 데이터를 반환할 가능성이 있습니다.
어쨌든 값은 결국 복제본 간에 전파되지만 조정 대기가 끝난 후에만 전파됩니다. 이 전파를 최종 일관성이라고 합니다. 쓰기 시점에 모든 복제본 노드를 사용할 수 없는 경우 수정 읽기 및 엔트로피 방지 노드 복구와 같은 조만간 복구 도구가 작동하게 됩니다. 이에 대해서는 나중에 자세히 설명합니다.
따라서 QUORUM 읽기 및 쓰기 일관성 수준을 사용하면 강력한 일관성이 항상 유지되며 이는 읽기 및 쓰기 대기 시간 간의 균형이 됩니다. ALL 쓰기 및 ONE 읽기를 사용하면 강력한 일관성이 유지되고 읽기가 더 빠르고 사용 가능해집니다. 즉, 읽기가 여전히 완료되는 실패한 노드의 수가 QUORUM보다 클 수 있습니다.
쓰기 작업의 경우 모든 복제 작업자 노드가 필요합니다. ONE을 쓰고 ALL을 읽을 때 엄격한 일관성이 있으며 쓰기 작업이 서버 중 적어도 하나에서 발생했음을 확인하는 것만으로 충분하기 때문에 쓰기 작업이 더 빨라지고 쓰기 가용성이 커집니다. 읽기 속도가 느리고 모든 복제본 노드가 필요합니다. 응용 프로그램에 엄격한 일관성이 필요하지 않은 경우 읽기 및 쓰기 작업 속도를 높이고 일관성 수준을 더 낮게 설정하여 가용성을 높일 수 있습니다.