5.1 Distribuzione dei dati
Consideriamo come i dati vengono distribuiti in base alla chiave tra i nodi del cluster. Cassandra ti consente di impostare una strategia di distribuzione dei dati. La prima strategia di questo tipo distribuisce i dati in base al valore della chiave md5, un partizionatore casuale. Il secondo tiene conto della rappresentazione in bit della chiave stessa: il markup ordinale (partizionatore ordinato per byte).
La prima strategia, per la maggior parte, offre maggiori vantaggi, poiché non è necessario preoccuparsi della distribuzione uniforme dei dati tra i server e di tali problemi. La seconda strategia viene utilizzata in rari casi, ad esempio, se sono necessarie query a intervalli (scansione di intervalli). È importante notare che la scelta di questa strategia viene effettuata prima della creazione del cluster e infatti non può essere modificata senza un ricaricamento completo dei dati.
Cassandra utilizza una tecnica nota come hashing coerente per distribuire i dati. Questo approccio consente di distribuire i dati tra i nodi e assicurarsi che quando un nuovo nodo viene aggiunto e rimosso, la quantità di dati trasferiti sia ridotta. Per fare ciò, a ciascun nodo viene assegnata un'etichetta (token), che divide in parti l'insieme di tutti i valori della chiave md5. Poiché RandomPartitioner viene utilizzato nella maggior parte dei casi, consideriamolo.
Come ho detto, RandomPartitioner calcola un md5 a 128 bit per ogni chiave. Per determinare in quali nodi verranno archiviati i dati, passa semplicemente attraverso tutte le etichette dei nodi dal più piccolo al più grande e quando il valore dell'etichetta diventa maggiore del valore della chiave md5, allora questo nodo, insieme a un numero di nodi successivi (nell'ordine delle etichette) viene selezionato per l'archiviazione. Il numero totale di nodi selezionati deve essere uguale al fattore di replica. Il livello di replica è impostato per ogni keyspace e consente di regolare la ridondanza dei dati (ridondanza dei dati).


Prima di poter aggiungere un nodo al cluster, è necessario assegnargli un'etichetta. La percentuale di chiavi che coprono lo spazio tra questa etichetta e quella successiva determina la quantità di dati che verranno archiviati sul nodo. L'intero set di etichette per un cluster è chiamato anello.
Ecco un'illustrazione che utilizza l'utilità nodetool incorporata per visualizzare un anello di cluster di 6 nodi con etichette equidistanti.

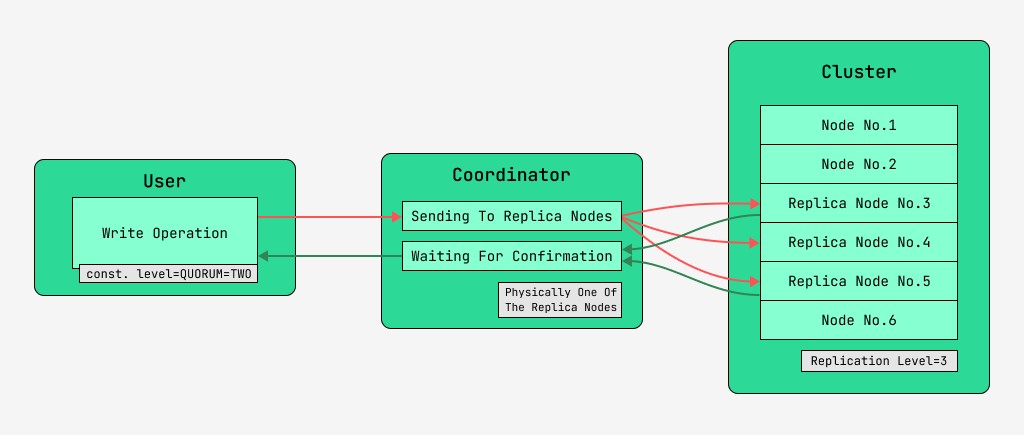
5.2 Coerenza dei dati durante la scrittura
I nodi del cluster Cassandra sono equivalenti e i client possono connettersi a uno qualsiasi di essi, sia per la scrittura che per la lettura. Le richieste passano attraverso la fase di coordinamento, durante la quale, dopo aver scoperto con l'aiuto della chiave e del markup su quali nodi devono trovarsi i dati, il server invia richieste a questi nodi. Chiameremo il nodo che esegue il coordinamento il coordinatore e i nodi selezionati per salvare il record con la chiave data, i nodi di replica . Fisicamente, uno dei nodi di replica può essere il coordinatore: dipende solo dalla chiave, dal markup e dalle etichette.
Per ogni richiesta, sia in lettura che in scrittura, è possibile impostare il livello di consistenza dei dati.
Per una scrittura, questo livello influirà sul numero di nodi di replica che attenderanno la conferma del corretto completamento dell'operazione (dati scritti) prima di restituire il controllo all'utente. Per la cronaca, ci sono questi livelli di coerenza:
- UNO - il coordinatore invia le richieste a tutti i nodi di replica, ma dopo aver atteso la conferma dal primo nodo, restituisce il controllo all'utente;
- TWO - lo stesso, ma il coordinatore attende la conferma dai primi due nodi prima di restituire il controllo;
- TRE - simile, ma il coordinatore attende la conferma dai primi tre nodi prima di restituire il controllo;
- QUORUM - viene raccolto un quorum: il coordinatore attende la conferma del record da più della metà dei nodi di replica, ovvero round (N / 2) + 1, dove N è il livello di replica;
- LOCAL_QUORUM - Il coordinatore è in attesa di conferma da più della metà dei nodi di replica nello stesso data center in cui si trova il coordinatore (potenzialmente diverso per ogni richiesta). Consente di eliminare i ritardi associati all'invio di dati ad altri data center. I problemi relativi all'utilizzo di molti data center sono considerati di passaggio in questo articolo;
- EACH_QUORUM - Il coordinatore è in attesa di conferma da più della metà dei nodi di replica in ciascun data center, in modo indipendente;
- ALL - il coordinatore attende la conferma da tutti i nodi di replica;
- ANY : consente di scrivere dati, anche se tutti i nodi di replica non rispondono. Il coordinatore attende la prima risposta da uno dei nodi di replica o l'archiviazione dei dati utilizzando un passaggio suggerito sul coordinatore.
5.3 Coerenza dei dati durante la lettura
Per le letture, il livello di coerenza influirà sul numero di nodi di replica da cui verranno letti. Per la lettura, ci sono questi livelli di coerenza:
- UNO : il coordinatore invia le richieste al nodo di replica più vicino. Anche il resto delle repliche viene letto per la riparazione in lettura con la probabilità specificata nella configurazione cassandra;
- TWO è uguale, ma il coordinatore invia le richieste ai due nodi più vicini. Viene scelto il valore con il timestamp più grande;
- TRE - simile all'opzione precedente, ma con tre nodi;
- QUORUM - viene raccolto un quorum, ovvero il coordinatore invia richieste a più della metà dei nodi di replica, ovvero round (N / 2) + 1, dove N è il livello di replica;
- LOCAL_QUORUM - viene raccolto un quorum nel data center in cui avviene il coordinamento e vengono restituiti i dati con il timestamp più recente;
- EACH_QUORUM - Il coordinatore restituisce i dati dopo la riunione del quorum in ciascuno dei data center;
- ALL - Il coordinatore restituisce i dati dopo aver letto da tutti i nodi di replica.

Pertanto, è possibile regolare i ritardi temporali delle operazioni di lettura e scrittura e regolare la coerenza (sintonizzare la coerenza), nonché la disponibilità (disponibilità) di ciascun tipo di operazione. In effetti, la disponibilità è direttamente correlata al livello di coerenza delle letture e delle scritture, in quanto determina quanti nodi di replica possono essere disattivati ed essere comunque confermati.
Se il numero di nodi da cui proviene il riconoscimento di scrittura, più il numero di nodi da cui viene effettuata la lettura, è maggiore del livello di replica, allora abbiamo la garanzia che il nuovo valore verrà sempre letto dopo la scrittura, e questo si chiama consistenza forte (coerenza forte). In assenza di coerenza assoluta, esiste la possibilità che un'operazione di lettura restituisca dati obsoleti.
In ogni caso, il valore alla fine si propagherà tra le repliche, ma solo al termine dell'attesa di coordinamento. Questa propagazione è chiamata coerenza finale. Se non tutti i nodi di replica sono disponibili al momento della scrittura, prima o poi entreranno in gioco strumenti di recupero come le letture correttive e la riparazione dei nodi anti-entropia. Ne parleremo più avanti.
Pertanto, con un livello di coerenza di lettura e scrittura QUORUM, verrà sempre mantenuta una forte coerenza e questo sarà un equilibrio tra la latenza di lettura e scrittura. Con TUTTE le scritture e UNA lettura ci sarà una forte coerenza e le letture saranno più veloci e più disponibili, ovvero il numero di nodi non riusciti in cui una lettura sarà ancora completata può essere maggiore che con QUORUM.
Per le operazioni di scrittura, saranno richiesti tutti i nodi di lavoro di replica. Quando si scrive UNO, leggendo TUTTI, ci sarà anche una coerenza rigorosa, e le operazioni di scrittura saranno più veloci e la disponibilità di scrittura sarà ampia, perché sarà sufficiente confermare solo che l'operazione di scrittura è avvenuta su almeno uno dei server, mentre la lettura è più lenta e richiede tutti i nodi di replica. Se un'applicazione non richiede una coerenza rigorosa, è possibile velocizzare le operazioni di lettura e scrittura, nonché migliorare la disponibilità impostando livelli di coerenza inferiori.