5.1 ডেটা বিতরণ
ক্লাস্টার নোডগুলির মধ্যে কীটির উপর নির্ভর করে ডেটা কীভাবে বিতরণ করা হয় তা বিবেচনা করা যাক। ক্যাসান্ড্রা আপনাকে একটি ডেটা বিতরণ কৌশল সেট করতে দেয়। এই ধরনের প্রথম কৌশলটি md5 কী মানের উপর নির্ভর করে ডেটা বিতরণ করে - একটি র্যান্ডম পার্টিশনার। দ্বিতীয়টি কীটির বিট উপস্থাপনাকে বিবেচনা করে - অর্ডিনাল মার্কআপ (বাইট-অর্ডার করা পার্টিশনার)।
প্রথম কৌশলটি, বেশিরভাগ অংশের জন্য, আরও সুবিধা দেয়, যেহেতু আপনাকে সার্ভার এবং এই জাতীয় সমস্যাগুলির মধ্যে ডেটা বিতরণ সম্পর্কেও চিন্তা করতে হবে না। দ্বিতীয় কৌশলটি বিরল ক্ষেত্রে ব্যবহার করা হয়, উদাহরণস্বরূপ, যদি ব্যবধানের প্রশ্ন (রেঞ্জ স্ক্যান) প্রয়োজন হয়। এটি লক্ষ করা গুরুত্বপূর্ণ যে এই কৌশলটির পছন্দ ক্লাস্টার তৈরির আগে করা হয়েছিল এবং প্রকৃতপক্ষে ডেটা সম্পূর্ণ পুনরায় লোড না করে পরিবর্তন করা যায় না।
ক্যাসান্ড্রা ডেটা বিতরণ করার জন্য ধারাবাহিক হ্যাশিং নামে পরিচিত একটি কৌশল ব্যবহার করে। এই পদ্ধতির সাহায্যে আপনি নোডগুলির মধ্যে ডেটা বিতরণ করতে পারবেন এবং নিশ্চিত করুন যে যখন একটি নতুন নোড যোগ করা এবং সরানো হয়, তখন স্থানান্তরিত ডেটার পরিমাণ কম হয়। এটি করার জন্য, প্রতিটি নোডকে একটি লেবেল (টোকেন) বরাদ্দ করা হয়, যা সমস্ত md5 কী মানের সেটকে অংশে বিভক্ত করে। যেহেতু বেশিরভাগ ক্ষেত্রেই RandomPartitioner ব্যবহার করা হয়, আসুন এটি বিবেচনা করা যাক।
আমি যেমন বলেছি, RandomPartitioner প্রতিটি কী-এর জন্য একটি 128-বিট md5 গণনা করে। কোন নোডগুলিতে ডেটা সংরক্ষণ করা হবে তা নির্ধারণ করতে, এটি কেবল নোডের সমস্ত লেবেল থেকে ছোট থেকে বৃহত্তম পর্যন্ত যায় এবং যখন লেবেলের মান md5 কী-এর মানের থেকে বেশি হয়ে যায়, তখন এই নোডটি সহ পরবর্তী নোডের সংখ্যা (লেবেলের ক্রম অনুসারে) স্টোরেজের জন্য নির্বাচন করা হয়েছে। নির্বাচিত নোডের মোট সংখ্যা প্রতিলিপি ফ্যাক্টরের সমান হতে হবে। প্রতিলিপি স্তর প্রতিটি কীস্পেসের জন্য সেট করা আছে এবং আপনাকে ডেটার রিডানডেন্সি (ডেটা রিডানডেন্সি) সামঞ্জস্য করতে দেয়।


একটি নোড ক্লাস্টারে যোগ করার আগে, এটি একটি লেবেল দেওয়া আবশ্যক। এই লেবেল এবং পরেরটির মধ্যে ব্যবধান কভার করে এমন কীগুলির শতাংশ নির্ধারণ করে যে নোডে কতটা ডেটা সংরক্ষণ করা হবে। একটি ক্লাস্টারের জন্য লেবেলের সম্পূর্ণ সেটটিকে রিং বলা হয়।
সমানভাবে ব্যবধানযুক্ত লেবেল সহ 6 নোডের একটি ক্লাস্টার রিং প্রদর্শন করার জন্য বিল্ট-ইন নোডটুল ইউটিলিটি ব্যবহার করে এখানে একটি চিত্র দেওয়া হল।

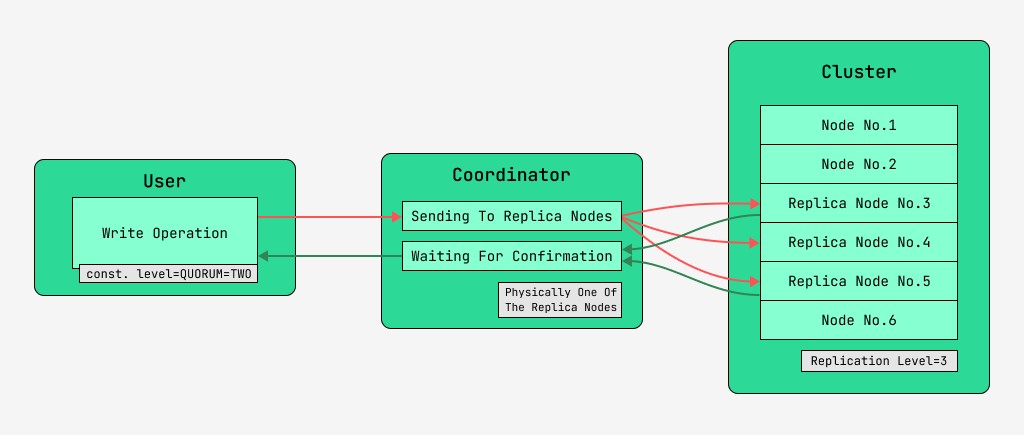
5.2 লেখার সময় ডেটা সামঞ্জস্য
ক্যাসান্ড্রা ক্লাস্টার নোডগুলি সমতুল্য, এবং ক্লায়েন্টরা লেখার জন্য এবং পড়ার জন্য উভয়ের সাথেই সংযোগ করতে পারে। অনুরোধগুলি সমন্বয়ের পর্যায়ে যায়, সেই সময়, কী এবং মার্কআপের সাহায্যে খুঁজে বের করে যে নোডগুলিতে ডেটা থাকা উচিত, সার্ভার এই নোডগুলিতে অনুরোধ পাঠায়। যে নোডটি সমন্বয় সম্পাদন করে তাকে আমরা সমন্বয়কারী বলব এবং যে নোডগুলিকে প্রদত্ত কী দিয়ে রেকর্ড সংরক্ষণ করার জন্য নির্বাচন করা হয়েছে, সেই নোডগুলিকে রেপ্লিকা নোড বলব। শারীরিকভাবে, রেপ্লিকা নোডগুলির মধ্যে একটি সমন্বয়কারী হতে পারে - এটি শুধুমাত্র কী, মার্কআপ এবং লেবেলের উপর নির্ভর করে।
প্রতিটি অনুরোধের জন্য, পড়া এবং লেখা উভয়ের জন্য, ডেটা সামঞ্জস্যের স্তর সেট করা সম্ভব।
একটি লেখার জন্য, এই স্তরটি প্রতিরূপ নোডের সংখ্যাকে প্রভাবিত করবে যা ব্যবহারকারীর কাছে নিয়ন্ত্রণ ফিরিয়ে দেওয়ার আগে অপারেশনের সফল সমাপ্তির (ডেটা লেখা) নিশ্চিতকরণের জন্য অপেক্ষা করবে। একটি রেকর্ডের জন্য, এই ধারাবাহিকতা স্তর রয়েছে:
- এক - সমন্বয়কারী সমস্ত রেপ্লিকা নোডগুলিতে অনুরোধ পাঠায়, কিন্তু প্রথম নোড থেকে নিশ্চিতকরণের জন্য অপেক্ষা করার পরে, ব্যবহারকারীকে নিয়ন্ত্রণ ফিরিয়ে দেয়;
- দুই - একই, কিন্তু সমন্বয়কারী নিয়ন্ত্রণ ফিরে আসার আগে প্রথম দুটি নোড থেকে নিশ্চিতকরণের জন্য অপেক্ষা করে;
- তিন - অনুরূপ, কিন্তু সমন্বয়কারী নিয়ন্ত্রণ ফিরে আসার আগে প্রথম তিনটি নোড থেকে নিশ্চিতকরণের জন্য অপেক্ষা করে;
- কোরাম - একটি কোরাম সংগ্রহ করা হয়: সমন্বয়কারী অর্ধেকেরও বেশি রেপ্লিকা নোড থেকে রেকর্ডের নিশ্চিতকরণের জন্য অপেক্ষা করছেন, যথা রাউন্ড (N/2) + 1, যেখানে N হল প্রতিলিপি স্তর;
- LOCAL_QUORUM - সমন্বয়কারী একই ডেটা সেন্টারে অর্ধেকেরও বেশি রেপ্লিকা নোড থেকে নিশ্চিতকরণের জন্য অপেক্ষা করছেন যেখানে সমন্বয়কারী অবস্থিত (প্রতিটি অনুরোধের জন্য সম্ভাব্য আলাদা)। আপনাকে অন্যান্য ডেটা সেন্টারে ডেটা পাঠানোর সাথে যুক্ত বিলম্ব থেকে মুক্তি পেতে দেয়। অনেক ডেটা সেন্টারের সাথে কাজ করার বিষয়গুলি এই নিবন্ধে বিবেচনা করা হয়েছে;
- EACH_QUORUM - সমন্বয়কারী প্রতিটি ডেটা সেন্টারে অর্ধেকেরও বেশি রেপ্লিকা নোড থেকে নিশ্চিতকরণের জন্য অপেক্ষা করছেন, স্বাধীনভাবে;
- সমস্ত - সমন্বয়কারী সমস্ত রেপ্লিকা নোড থেকে নিশ্চিতকরণের জন্য অপেক্ষা করে;
- যেকোনো - সমস্ত প্রতিলিপি নোড সাড়া না দিলেও ডেটা লেখা সম্ভব করে তোলে। সমন্বয়কারী হয় প্রতিরূপ নোডগুলির একটি থেকে প্রথম প্রতিক্রিয়ার জন্য বা সমন্বয়কারীতে একটি ইঙ্গিত হ্যান্ডঅফ ব্যবহার করে ডেটা সংরক্ষণ করার জন্য অপেক্ষা করে।
5.3 পড়ার সময় ডেটা ধারাবাহিকতা
পড়ার জন্য, সামঞ্জস্যের স্তরটি প্রতিলিপি নোডের সংখ্যাকে প্রভাবিত করবে যা থেকে পড়া হবে। পড়ার জন্য, এই ধারাবাহিকতা স্তর আছে:
- এক - সমন্বয়কারী নিকটতম প্রতিরূপ নোডে অনুরোধ পাঠায়। ক্যাসান্ড্রা কনফিগারেশনে নির্দিষ্ট সম্ভাব্যতার সাথে রিড মেরামতের জন্য বাকি প্রতিলিপিগুলিও পড়া হয়;
- TWO একই, কিন্তু সমন্বয়কারী দুটি নিকটতম নোডে অনুরোধ পাঠায়। সবচেয়ে বড় টাইমস্ট্যাম্প সহ মানটি বেছে নেওয়া হয়েছে;
- তিন - পূর্ববর্তী বিকল্পের অনুরূপ, কিন্তু তিনটি নোড সহ;
- কোরাম - একটি কোরাম সংগ্রহ করা হয়, অর্থাৎ, সমন্বয়কারী প্রতিলিপি নোডের অর্ধেকেরও বেশি অনুরোধ পাঠায়, যথা রাউন্ড (N/2) + 1, যেখানে N হল প্রতিলিপি স্তর;
- LOCAL_QUORUM - ডেটা সেন্টারে একটি কোরাম সংগ্রহ করা হয় যেখানে সমন্বয় ঘটে এবং সর্বশেষ টাইমস্ট্যাম্প সহ ডেটা ফেরত দেওয়া হয়;
- EACH_QUORUM - প্রতিটি ডেটা সেন্টারে কোরাম মিটিংয়ের পরে সমন্বয়কারী ডেটা ফেরত দেয়;
- সমস্ত - সমস্ত রেপ্লিকা নোড থেকে পড়ার পরে সমন্বয়কারী ডেটা ফেরত দেয়।

এইভাবে, পঠন এবং লেখার ক্রিয়াকলাপগুলির সময় বিলম্ব সামঞ্জস্য করা এবং ধারাবাহিকতা (টিউনের ধারাবাহিকতা), পাশাপাশি প্রতিটি ধরণের অপারেশনের প্রাপ্যতা (উপলভ্যতা) সামঞ্জস্য করা সম্ভব। প্রকৃতপক্ষে, প্রাপ্যতা সরাসরি পড়া এবং লেখার ধারাবাহিকতার স্তরের সাথে সম্পর্কিত, কারণ এটি নির্ধারণ করে যে কতগুলি প্রতিলিপি নোড নিচে যেতে পারে এবং এখনও নিশ্চিত করা যায়।
যদি নোডের সংখ্যা যেখান থেকে লেখার স্বীকৃতি আসে, এবং যে নোডগুলি থেকে পঠন করা হয় তার সংখ্যা প্রতিলিপি স্তরের চেয়ে বেশি হয়, তাহলে আমাদের একটি গ্যারান্টি আছে যে নতুন মান সর্বদা লেখার পরে পড়া হবে, এবং এটি বলা হয় শক্তিশালী ধারাবাহিকতা (শক্তিশালী ধারাবাহিকতা)। দৃঢ় সামঞ্জস্যের অনুপস্থিতিতে, একটি পঠিত ক্রিয়াকলাপ পুরানো ডেটা ফেরত দেওয়ার সম্ভাবনা রয়েছে।
যাই হোক না কেন, মান শেষ পর্যন্ত প্রতিলিপিগুলির মধ্যে প্রচারিত হবে, কিন্তু সমন্বয় অপেক্ষা শেষ হওয়ার পরেই। এই বংশবিস্তারকে বলা হয় চূড়ান্ত ধারাবাহিকতা। লেখার সময় যদি সমস্ত রেপ্লিকা নোড পাওয়া না যায়, তাহলে শীঘ্রই বা পরে পুনরুদ্ধারের সরঞ্জাম যেমন প্রতিকারমূলক রিডস এবং অ্যান্টি-এনট্রপি নোড মেরামত কার্যকর হবে। এই বিষয়ে পরে আরো.
এইভাবে, একটি QUORUM পঠন এবং লেখার ধারাবাহিকতা স্তরের সাথে, শক্তিশালী ধারাবাহিকতা সর্বদা বজায় থাকবে এবং এটি পড়ার এবং লেখার লেটেন্সির মধ্যে একটি ভারসাম্য হবে। সমস্ত লেখা এবং এক পঠনের সাথে দৃঢ় সামঞ্জস্যতা থাকবে এবং পঠনগুলি দ্রুততর এবং আরও উপলব্ধ হবে, অর্থাৎ ব্যর্থ নোডের সংখ্যা যেখানে একটি পঠন এখনও সম্পূর্ণ হবে তা QUORUM এর চেয়ে বেশি হতে পারে।
লেখার ক্রিয়াকলাপের জন্য, সমস্ত প্রতিরূপ কর্মী নোডের প্রয়োজন হবে। একটি লেখার সময়, সমস্ত পড়ার সময়, কঠোর সামঞ্জস্যতাও থাকবে, এবং লেখার ক্রিয়াকলাপগুলি আরও দ্রুত হবে এবং লেখার প্রাপ্যতা বড় হবে, কারণ এটি কেবলমাত্র নিশ্চিত করার জন্য যথেষ্ট হবে যে লেখার ক্রিয়াকলাপ কমপক্ষে একটি সার্ভারে ঘটেছে, যখন পড়া ধীর এবং সব প্রতিলিপি নোড প্রয়োজন. যদি একটি অ্যাপ্লিকেশনের কঠোর সামঞ্জস্যের জন্য প্রয়োজনীয়তা না থাকে, তাহলে এটি পড়া এবং লেখার উভয় ক্রিয়াকলাপের গতি বাড়ানো এবং সেইসাথে নিম্ন সামঞ্জস্যের স্তর সেট করে প্রাপ্যতা উন্নত করা সম্ভব।