5.1 Datadistribution
Låt oss överväga hur data fördelas beroende på nyckeln bland klusternoderna. Cassandra låter dig ställa in en datadistributionsstrategi. Den första sådana strategin distribuerar data beroende på md5-nyckelvärdet - en slumpmässig partitionerare. Den andra tar hänsyn till bitrepresentationen av själva nyckeln - den ordinarie markeringen (byte-ordnad partitionerare).
Den första strategin ger för det mesta fler fördelar, eftersom du inte behöver oroa dig för jämn distribution av data mellan servrar och sådana problem. Den andra strategin används i sällsynta fall, till exempel om intervallfrågor (avståndssökning) behövs. Det är viktigt att notera att valet av denna strategi görs före skapandet av klustret och i själva verket inte kan ändras utan en fullständig omladdning av data.
Cassandra använder en teknik som kallas konsekvent hashing för att distribuera data. Detta tillvägagångssätt låter dig distribuera data mellan noder och se till att mängden data som överförs är liten när en ny nod läggs till och tas bort. För att göra detta tilldelas varje nod en etikett (token), som delar upp uppsättningen av alla md5-nyckelvärden i delar. Eftersom RandomPartitioner används i de flesta fall, låt oss överväga det.
Som jag sa, RandomPartitioner beräknar en 128-bitars md5 för varje nyckel. För att bestämma i vilka noder data kommer att lagras går den helt enkelt igenom alla nodernas etiketter från minsta till största, och när värdet på etiketten blir större än värdet på md5-nyckeln, så går denna nod, tillsammans med en antal efterföljande noder (i etikettordning) väljs för lagring. Det totala antalet valda noder måste vara lika med replikeringsfaktorn. Replikeringsnivån ställs in för varje tangentutrymme och låter dig justera redundansen för data (dataredundans).


Innan en nod kan läggas till i klustret måste den ges en etikett. Procentandelen nycklar som täcker gapet mellan denna etikett och nästa bestämmer hur mycket data som kommer att lagras på noden. Hela uppsättningen etiketter för ett kluster kallas en ring.
Här är en illustration som använder det inbyggda nodetverktyget för att visa en klusterring med 6 noder med jämnt fördelade etiketter.

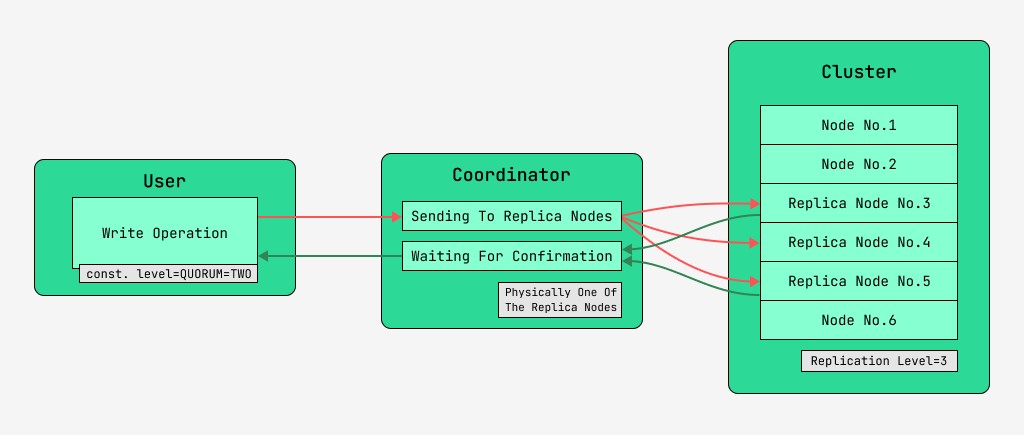
5.2 Datakonsistens vid skrivning
Cassandra-klusternoder är likvärdiga och klienter kan ansluta till vilken som helst av dem, både för att skriva och läsa. Förfrågningar går igenom koordinationsstadiet, under vilket servern, efter att ha tagit reda på med hjälp av nyckeln och markeringen på vilka noder data ska placeras, skickar förfrågningar till dessa noder. Vi kommer att kalla noden som utför koordineringen för koordinatorn och noderna som är valda för att spara posten med den givna nyckeln, replikanoderna . Fysiskt kan en av repliknoderna vara koordinatorn - det beror bara på nyckeln, uppmärkningen och etiketterna.
För varje begäran, både för läsning och skrivning, är det möjligt att ställa in nivån på datakonsistens.
För en skrivning kommer denna nivå att påverka antalet replikanoder som väntar på bekräftelse av framgångsrikt slutförande av operationen (data skrivna) innan kontrollen återgår till användaren. För en rekord, det finns dessa konsistensnivåer:
- ETT - koordinatorn skickar förfrågningar till alla replikanoder, men efter att ha väntat på bekräftelse från den första noden, återgår kontrollen till användaren;
- TVÅ - samma, men koordinatorn väntar på bekräftelse från de två första noderna innan han återgår till kontrollen;
- TRE - liknande, men koordinatorn väntar på bekräftelse från de tre första noderna innan han återgår till kontrollen;
- KVORUM - ett kvorum samlas in: koordinatorn väntar på bekräftelse av posten från mer än hälften av replikanoderna, nämligen rund (N / 2) + 1, där N är replikeringsnivån;
- LOCAL_QUORUM - Samordnaren väntar på bekräftelse från mer än hälften av replikanoderna i samma datacenter där samordnaren finns (potentiellt olika för varje begäran). Låter dig bli av med förseningar som är förknippade med att skicka data till andra datacenter. Problemen med att arbeta med många datacenter behandlas i den här artikeln i förbigående;
- EACH_QUORUM - Samordnaren väntar på bekräftelse från mer än hälften av replikanoderna i varje datacenter, oberoende av varandra;
- ALLA - koordinatorn väntar på bekräftelse från alla repliknoder;
- ANY - gör det möjligt att skriva data, även om alla repliknoder inte svarar. Koordinatorn väntar antingen på det första svaret från en av replikanoderna, eller på att data ska lagras med hjälp av en antydd handoff på koordinatorn.
5.3 Datakonsistens vid läsning
För läsningar kommer konsistensnivån att påverka antalet replikanoder som kommer att läsas från. För läsning finns det dessa konsistensnivåer:
- ETT - koordinatorn skickar förfrågningar till närmaste replikanod. Resten av replikerna läses också för läsreparation med den sannolikhet som anges i cassandra-konfigurationen;
- TVÅ är samma, men koordinatorn skickar förfrågningar till de två närmaste noderna. Värdet med den största tidsstämpeln väljs;
- TRE - liknande det tidigare alternativet, men med tre noder;
- KVORUM - ett kvorum samlas in, det vill säga samordnaren skickar förfrågningar till mer än hälften av replikanoderna, nämligen runda (N / 2) + 1, där N är replikeringsnivån;
- LOCAL_QUORUM - ett kvorum samlas in i datacentret där samordning sker, och data med den senaste tidsstämpeln returneras;
- EACH_QUORUM - Samordnaren returnerar data efter mötet med beslutförhet i vart och ett av datacentren;
- ALLA - Koordinatorn returnerar data efter att ha läst från alla repliknoder.

Således är det möjligt att justera tidsfördröjningarna för läs- och skrivoperationer och justera konsistensen (tune-konsistensen), såväl som tillgängligheten (tillgängligheten) för varje typ av operation. Faktum är att tillgänglighet är direkt relaterad till konsistensnivån för läsning och skrivning, eftersom den avgör hur många replikanoder som kan gå ner och fortfarande bekräftas.
Om antalet noder som skrivbekräftelsen kommer från, plus antalet noder som läsningen görs från, är större än replikeringsnivån, så har vi en garanti för att det nya värdet alltid läses efter skrivningen, och detta kallas stark konsistens (stark konsistens). I avsaknad av stark konsistens finns det en möjlighet att en läsoperation kommer att returnera inaktuella data.
I vilket fall som helst kommer värdet så småningom att spridas mellan repliker, men först efter att koordinationsväntan har avslutats. Denna spridning kallas eventuell konsistens. Om inte alla replikanoder är tillgängliga vid tidpunkten för skrivningen, kommer förr eller senare återställningsverktyg som avhjälpande läsningar och antientropinodreparation att träda i kraft. Mer om detta senare.
Sålunda, med en läs- och skrivkonsistensnivå för QUORUM kommer stark konsistens alltid att upprätthållas, och detta kommer att vara en balans mellan läs- och skrivfördröjning. Med ALLA skrivningar och EN läsning blir det stark konsistens och läsningar blir snabbare och mer tillgängliga, det vill säga antalet misslyckade noder där en läsning fortfarande kommer att slutföras kan vara större än med QUORUM.
För skrivoperationer kommer alla replikarbetarnoder att krävas. När man skriver ONE, läser ALLA, blir det också strikt konsistens, och skrivoperationerna blir snabbare och skrivtillgängligheten blir stor, eftersom det räcker för att endast bekräfta att skrivoperationen ägde rum på minst en av servrarna, medan läsningen är långsammare och kräver alla replikanoder. Om en applikation inte har ett krav på strikt konsistens är det möjligt att snabba upp både läs- och skrivoperationer, samt förbättra tillgängligheten genom att sätta lägre konsistensnivåer.