5.1 Diffusion des données
Considérons comment les données sont distribuées en fonction de la clé entre les nœuds du cluster. Cassandra permet de définir une stratégie de diffusion des données. La première de ces stratégies distribue les données en fonction de la valeur de la clé md5 - un partitionneur aléatoire. La seconde prend en compte la représentation binaire de la clé elle-même - le balisage ordinal (partitionneur ordonné par octet).
La première stratégie, pour la plupart, offre plus d'avantages, car vous n'avez pas à vous soucier de la répartition uniforme des données entre les serveurs et de tels problèmes. La deuxième stratégie est utilisée dans de rares cas, par exemple, si des requêtes d'intervalle (range scan) sont nécessaires. Il est important de noter que le choix de cette stratégie se fait avant la création du cluster et de fait ne peut être modifié sans un rechargement complet des données.
Cassandra utilise une technique connue sous le nom de hachage cohérent pour distribuer les données. Cette approche vous permet de répartir les données entre les nœuds et de vous assurer que lorsqu'un nouveau nœud est ajouté et supprimé, la quantité de données transférées est faible. Pour ce faire, chaque nœud se voit attribuer une étiquette (jeton), qui divise l'ensemble de toutes les valeurs de clé md5 en parties. Étant donné que RandomPartitioner est utilisé dans la plupart des cas, considérons-le.
Comme je l'ai dit, RandomPartitioner calcule un md5 128 bits pour chaque clé. Pour déterminer dans quels nœuds les données seront stockées, il suffit de parcourir toutes les étiquettes des nœuds du plus petit au plus grand, et lorsque la valeur de l'étiquette devient supérieure à la valeur de la clé md5, alors ce nœud, accompagné d'un nombre de nœuds suivants (dans l'ordre des étiquettes) est sélectionné pour le stockage. Le nombre total de nœuds sélectionnés doit être égal au facteur de réplication. Le niveau de réplication est défini pour chaque keyspace et permet d'ajuster la redondance des données (data redundancy).


Avant qu'un nœud puisse être ajouté au cluster, il doit recevoir une étiquette. Le pourcentage de clés qui couvrent l'écart entre cette étiquette et la suivante détermine la quantité de données qui seront stockées sur le nœud. L'ensemble complet d'étiquettes d'un cluster est appelé un anneau.
Voici une illustration utilisant l'utilitaire nodetool intégré pour afficher un anneau de cluster de 6 nœuds avec des étiquettes régulièrement espacées.

5.2 Cohérence des données lors de l'écriture
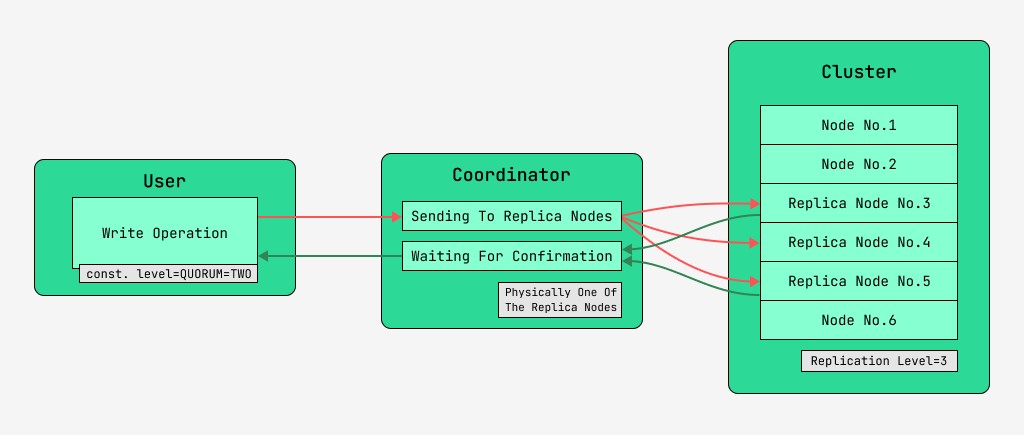
Les nœuds de cluster Cassandra sont équivalents et les clients peuvent se connecter à n'importe lequel d'entre eux, à la fois pour l'écriture et la lecture. Les requêtes passent par l'étape de coordination, au cours de laquelle, après avoir découvert à l'aide de la clé et du balisage sur quels nœuds les données doivent être situées, le serveur envoie des requêtes à ces nœuds. Nous appellerons le nœud qui effectue la coordination le coordinateur et les nœuds sélectionnés pour enregistrer l'enregistrement avec la clé donnée, les nœuds de réplique . Physiquement, l'un des nœuds de réplique peut être le coordinateur - cela dépend uniquement de la clé, du balisage et des étiquettes.
Pour chaque requête, aussi bien en lecture qu'en écriture, il est possible de paramétrer le niveau de cohérence des données.
Pour une écriture, ce niveau affectera le nombre de nœuds de réplique qui attendront la confirmation de la réussite de l'opération (données écrites) avant de rendre le contrôle à l'utilisateur. Pour un enregistrement, il existe ces niveaux de cohérence :
- ONE - le coordinateur envoie des demandes à tous les nœuds de réplique, mais après avoir attendu la confirmation du premier nœud, rend le contrôle à l'utilisateur ;
- DEUX - identique, mais le coordinateur attend la confirmation des deux premiers nœuds avant de rendre le contrôle ;
- TROIS - similaire, mais le coordinateur attend la confirmation des trois premiers nœuds avant de rendre le contrôle ;
- QUORUM - un quorum est collecté : le coordinateur attend la confirmation de l'enregistrement de plus de la moitié des nœuds répliqués, à savoir rond (N/2) + 1, où N est le niveau de réplication ;
- LOCAL_QUORUM - Le coordinateur attend la confirmation de plus de la moitié des nœuds de réplique dans le même centre de données où se trouve le coordinateur (potentiellement différent pour chaque demande). Vous permet de vous débarrasser des retards associés à l'envoi de données vers d'autres centres de données. Les problèmes liés au travail avec de nombreux centres de données sont examinés en passant dans cet article ;
- EACH_QUORUM - Le coordinateur attend la confirmation de plus de la moitié des nœuds de réplique dans chaque centre de données, indépendamment ;
- ALL - le coordinateur attend la confirmation de tous les nœuds de réplique ;
- ANY - permet d'écrire des données, même si tous les nœuds de réplique ne répondent pas. Le coordinateur attend soit la première réponse de l'un des nœuds de réplique, soit que les données soient stockées à l'aide d'un transfert suggéré sur le coordinateur.
5.3 Cohérence des données lors de la lecture
Pour les lectures, le niveau de cohérence affectera le nombre de nœuds de réplique qui seront lus. Pour la lecture, il existe ces niveaux de cohérence :
- ONE - le coordinateur envoie des requêtes au nœud de réplique le plus proche. Le reste des répliques est également lu pour la réparation de lecture avec la probabilité spécifiée dans la configuration de cassandra ;
- TWO est identique, mais le coordinateur envoie des requêtes aux deux nœuds les plus proches. La valeur avec l'horodatage le plus grand est choisie ;
- TROIS - similaire à l'option précédente, mais avec trois nœuds ;
- QUORUM - un quorum est collecté, c'est-à-dire que le coordinateur envoie des requêtes à plus de la moitié des nœuds de réplique, à savoir rond (N / 2) + 1, où N est le niveau de réplication ;
- LOCAL_QUORUM - un quorum est collecté dans le centre de données dans lequel la coordination a lieu, et les données avec le dernier horodatage sont renvoyées ;
- EACH_QUORUM - Le coordinateur renvoie les données après la réunion du quorum dans chacun des centres de données ;
- ALL - Le coordinateur renvoie les données après avoir lu tous les nœuds de réplica.

Ainsi, il est possible d'ajuster les temporisations des opérations de lecture et d'écriture et d'ajuster la cohérence (tune consistance), ainsi que la disponibilité (availability) de chaque type d'opération. En fait, la disponibilité est directement liée au niveau de cohérence des lectures et des écritures, car elle détermine le nombre de nœuds de réplica qui peuvent tomber et être encore confirmés.
Si le nombre de nœuds d'où provient l'acquittement d'écriture, plus le nombre de nœuds d'où s'effectue la lecture, est supérieur au niveau de réplication, alors on a la garantie que la nouvelle valeur sera toujours lue après l'écriture, et cela est appelée cohérence forte (cohérence forte). En l'absence de cohérence forte, il est possible qu'une opération de lecture renvoie des données obsolètes.
Dans tous les cas, la valeur finira par se propager entre les répliques, mais seulement après la fin de l'attente de coordination. Cette propagation est appelée cohérence éventuelle. Si tous les nœuds de réplique ne sont pas disponibles au moment de l'écriture, des outils de récupération tôt ou tard tels que les lectures correctives et la réparation de nœud anti-entropie entreront en jeu. Plus à ce sujet plus tard.
Ainsi, avec un niveau de cohérence de lecture et d'écriture QUORUM, une cohérence forte sera toujours maintenue, et ce sera un équilibre entre la latence de lecture et d'écriture. Avec TOUTES les écritures et UNE lecture, il y aura une forte cohérence et les lectures seront plus rapides et plus disponibles, c'est-à-dire que le nombre de nœuds en échec sur lesquels une lecture sera encore terminée peut être supérieur à celui avec QUORUM.
Pour les opérations d'écriture, tous les nœuds de travail de réplique seront requis. Lors de l'écriture d'UN, en lisant TOUS, il y aura également une cohérence stricte, et les opérations d'écriture seront plus rapides et la disponibilité en écriture sera grande, car il suffira de confirmer uniquement que l'opération d'écriture a eu lieu sur au moins un des serveurs, tandis que la lecture est plus lente et nécessite tous les nœuds de réplique. Si une application n'a pas d'exigence de cohérence stricte, il est alors possible d'accélérer les opérations de lecture et d'écriture, ainsi que d'améliorer la disponibilité en définissant des niveaux de cohérence inférieurs.