5.1 Gegevensdistributie
Laten we eens kijken hoe de gegevens worden verdeeld, afhankelijk van de sleutel tussen de clusterknooppunten. Met Cassandra kunt u een strategie voor gegevensdistributie instellen. De eerste dergelijke strategie verdeelt gegevens afhankelijk van de md5-sleutelwaarde - een willekeurige partitie. De tweede houdt rekening met de bitrepresentatie van de sleutel zelf - de ordinale opmaak (byte-ordered partitioner).
De eerste strategie biedt grotendeels meer voordelen, aangezien u zich geen zorgen hoeft te maken over een gelijkmatige verdeling van gegevens tussen servers en dergelijke problemen. De tweede strategie wordt in zeldzame gevallen gebruikt, bijvoorbeeld als intervalquery's (bereikscan) nodig zijn. Het is belangrijk op te merken dat de keuze voor deze strategie wordt gemaakt voordat de cluster wordt gemaakt en in feite niet kan worden gewijzigd zonder de gegevens volledig opnieuw te laden.
Cassandra gebruikt een techniek die bekend staat als consistente hashing om gegevens te verspreiden. Met deze aanpak kunt u gegevens tussen knooppunten verdelen en ervoor zorgen dat wanneer een nieuw knooppunt wordt toegevoegd en verwijderd, de hoeveelheid overgedragen gegevens klein is. Om dit te doen, krijgt elk knooppunt een label (token) toegewezen, dat de set van alle md5-sleutelwaarden in delen splitst. Aangezien RandomPartitioner in de meeste gevallen wordt gebruikt, laten we het eens bekijken.
Zoals ik al zei, berekent RandomPartitioner een 128-bits md5 voor elke sleutel. Om te bepalen in welke knooppunten de gegevens worden opgeslagen, gaat het eenvoudigweg door alle labels van de knooppunten van klein naar groot, en wanneer de waarde van het label groter wordt dan de waarde van de md5-sleutel, dan wordt dit knooppunt, samen met een aantal opeenvolgende knooppunten (in de volgorde van labels) wordt geselecteerd voor opslag. Het totale aantal geselecteerde knooppunten moet gelijk zijn aan de replicatiefactor. Het replicatieniveau wordt voor elke keyspace ingesteld en stelt u in staat de redundantie van gegevens aan te passen (dataredundantie).


Voordat een knooppunt aan het cluster kan worden toegevoegd, moet het een label krijgen. Het percentage sleutels dat het gat tussen dit label en het volgende overbrugt, bepaalt hoeveel gegevens op het knooppunt worden opgeslagen. De hele set labels voor een cluster wordt een ring genoemd.
Hier is een illustratie waarbij het ingebouwde hulpprogramma nodetool wordt gebruikt om een clusterring van 6 knooppunten met gelijkmatig verdeelde labels weer te geven.

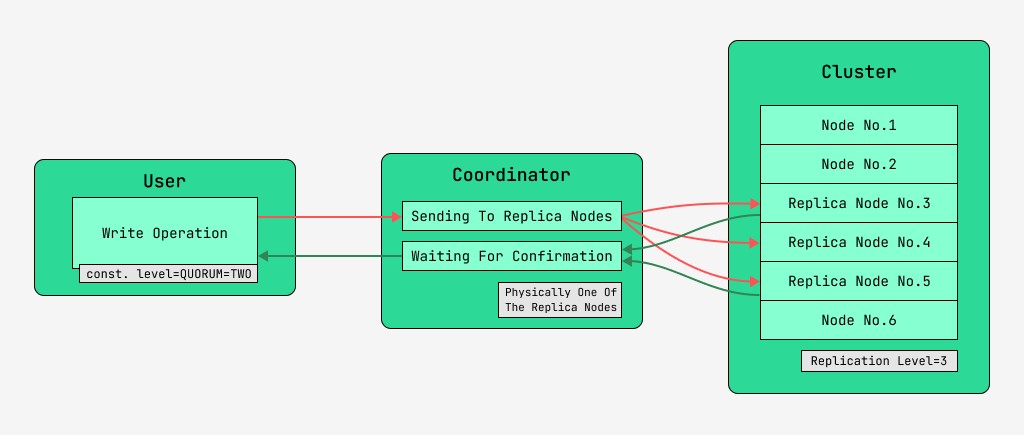
5.2 Gegevensconsistentie bij het schrijven
Cassandra-clusterknooppunten zijn gelijkwaardig en clients kunnen met elk van hen verbinding maken, zowel voor schrijven als voor lezen. Verzoeken doorlopen de coördinatiefase, waarin de server, nadat hij met behulp van de sleutel en de opmaak heeft ontdekt op welke knooppunten de gegevens zich moeten bevinden, verzoeken naar deze knooppunten stuurt. We zullen het knooppunt dat de coördinatie uitvoert de coördinator noemen , en de knooppunten die zijn geselecteerd om het record op te slaan met de gegeven sleutel, de replicaknooppunten . Fysiek kan een van de replicaknooppunten de coördinator zijn - dit hangt alleen af van de sleutel, opmaak en labels.
Voor elk verzoek, zowel voor lezen als schrijven, is het mogelijk om het niveau van gegevensconsistentie in te stellen.
Voor een schrijfbewerking is dit niveau van invloed op het aantal replicaknooppunten dat wacht op bevestiging van succesvolle voltooiing van de bewerking (gegevens geschreven) voordat de besturing wordt teruggegeven aan de gebruiker. Voor de goede orde, er zijn deze consistentieniveaus:
- EEN - de coördinator stuurt verzoeken naar alle replicaknooppunten, maar geeft na te hebben gewacht op bevestiging van het eerste knooppunt de besturing terug aan de gebruiker;
- TWEE - hetzelfde, maar de coördinator wacht op bevestiging van de eerste twee knooppunten voordat hij de besturing teruggeeft;
- DRIE - vergelijkbaar, maar de coördinator wacht op bevestiging van de eerste drie knooppunten voordat hij de controle teruggeeft;
- QUORUM - er wordt een quorum verzameld: de coördinator wacht op bevestiging van het record van meer dan de helft van de replicaknooppunten, namelijk ronde (N / 2) + 1, waarbij N het replicatieniveau is;
- LOCAL_QUORUM - De coördinator wacht op bevestiging van meer dan de helft van de replicaknooppunten in hetzelfde datacenter waar de coördinator zich bevindt (mogelijk verschillend voor elk verzoek). Hiermee kunt u de vertragingen wegwerken die gepaard gaan met het verzenden van gegevens naar andere datacenters. De problemen van het werken met veel datacenters worden in dit artikel terloops behandeld;
- EACH_QUORUM - De coördinator wacht op bevestiging van meer dan de helft van de replicaknooppunten in elk datacenter, onafhankelijk;
- ALLES - de coördinator wacht op bevestiging van alle replicaknooppunten;
- ANY - maakt het mogelijk om gegevens te schrijven, zelfs als niet alle replicaknooppunten reageren. De coördinator wacht ofwel op het eerste antwoord van een van de replicaknooppunten, ofwel op het opslaan van de gegevens met behulp van een hinted handoff op de coördinator.
5.3 Gegevensconsistentie bij het lezen
Voor lees bewerkingen is het consistentie niveau van invloed op het aantal replica knooppunten waaruit wordt gelezen. Voor het lezen zijn er deze consistentieniveaus:
- EEN - de coördinator stuurt verzoeken naar het dichtstbijzijnde replicaknooppunt. De rest van de replica's worden ook gelezen voor leesreparatie met de waarschijnlijkheid die is opgegeven in de cassandra-configuratie;
- TWEE is hetzelfde, maar de coördinator stuurt verzoeken naar de twee dichtstbijzijnde knooppunten. De waarde met de grootste tijdstempel wordt gekozen;
- DRIE - vergelijkbaar met de vorige optie, maar met drie knooppunten;
- QUORUM - er wordt een quorum verzameld, dat wil zeggen dat de coördinator verzoeken naar meer dan de helft van de replicaknooppunten stuurt, namelijk rond (N / 2) + 1, waarbij N het replicatieniveau is;
- LOCAL_QUORUM - een quorum wordt verzameld in het datacenter waarin de coördinatie plaatsvindt en de gegevens met de laatste tijdstempel worden geretourneerd;
- EACH_QUORUM - De coördinator retourneert gegevens na de vergadering van het quorum in elk van de datacenters;
- ALLES - De coördinator retourneert gegevens na het lezen van alle replicaknooppunten.

Het is dus mogelijk om de tijdsvertragingen van lees- en schrijfbewerkingen aan te passen en de consistentie (afstemconsistentie) aan te passen, evenals de beschikbaarheid (beschikbaarheid) van elk type bewerking. Beschikbaarheid is in feite direct gerelateerd aan het consistentieniveau van lees- en schrijfbewerkingen, omdat het bepaalt hoeveel replicaknooppunten kunnen worden uitgeschakeld en nog steeds worden bevestigd.
Als het aantal knooppunten waarvan de schrijfbevestiging afkomstig is, plus het aantal knooppunten waarvan gelezen wordt, groter is dan het replicatieniveau, dan hebben we een garantie dat de nieuwe waarde altijd zal worden gelezen na het schrijven, en dit heet sterke consistentie (sterke consistentie). Als er geen sterke consistentie is, bestaat de mogelijkheid dat een leesbewerking verouderde gegevens retourneert.
In elk geval zal de waarde uiteindelijk tussen replica's worden verspreid, maar pas nadat de coördinatiewachttijd is beëindigd. Deze voortplanting wordt uiteindelijke consistentie genoemd. Als niet alle replicaknooppunten beschikbaar zijn op het moment van schrijven, zullen vroeg of laat herstelhulpmiddelen zoals corrigerende leesbewerkingen en reparatie van anti-entropieknooppunten een rol gaan spelen. Hierover later meer.
Dus met een QUORUM lees- en schrijfconsistentieniveau zal altijd een sterke consistentie worden behouden, en dit zal een balans zijn tussen lees- en schrijflatentie. Met ALLE schrijfbewerkingen en ÉÉN leesbewerkingen zal er een sterke consistentie zijn en zullen leesbewerkingen sneller en meer beschikbaar zijn, d.w.z. het aantal mislukte knooppunten waarbij een leesbewerking nog steeds wordt voltooid, kan groter zijn dan bij QUORUM.
Voor schrijf bewerkingen zijn alle replica werk knooppunten vereist. Bij het schrijven van EEN, het lezen van ALLES, zal er ook een strikte consistentie zijn en zullen schrijfbewerkingen sneller zijn en zal de schrijfbeschikbaarheid groot zijn, omdat het voldoende is om alleen te bevestigen dat de schrijfbewerking plaatsvond op ten minste één van de servers, terwijl het lezen is langzamer en vereist alle replicaknooppunten. Als een applicatie geen vereiste heeft voor strikte consistentie, dan is het mogelijk om zowel lees- als schrijfbewerkingen te versnellen en de beschikbaarheid te verbeteren door lagere consistentieniveaus in te stellen.