5.1 Datenverteilung
Betrachten wir, wie die Daten je nach Schlüssel auf die Clusterknoten verteilt werden. Mit Cassandra können Sie eine Datenverteilungsstrategie festlegen. Die erste derartige Strategie verteilt Daten abhängig vom MD5-Schlüsselwert – ein zufälliger Partitionierer. Der zweite berücksichtigt die Bitdarstellung des Schlüssels selbst – das Ordinal-Markup (Byte-geordneter Partitionierer).
Die erste Strategie bietet größtenteils mehr Vorteile, da Sie sich keine Sorgen um die gleichmäßige Verteilung der Daten zwischen den Servern und solche Probleme machen müssen. Die zweite Strategie wird in seltenen Fällen verwendet, beispielsweise wenn Intervallabfragen (Range Scan) erforderlich sind. Es ist wichtig zu beachten, dass die Wahl dieser Strategie vor der Erstellung des Clusters getroffen wird und tatsächlich nicht ohne ein vollständiges Neuladen der Daten geändert werden kann.
Cassandra verwendet eine Technik, die als konsistentes Hashing bekannt ist, um Daten zu verteilen. Mit diesem Ansatz können Sie Daten zwischen Knoten verteilen und sicherstellen, dass beim Hinzufügen und Entfernen eines neuen Knotens die übertragene Datenmenge gering ist. Dazu wird jedem Knoten ein Label (Token) zugewiesen, das die Menge aller MD5-Schlüsselwerte in Teile aufteilt. Da RandomPartitioner in den meisten Fällen verwendet wird, betrachten wir es.
Wie gesagt, RandomPartitioner berechnet für jeden Schlüssel einen 128-Bit-MD5. Um zu bestimmen, in welchen Knoten die Daten gespeichert werden, werden einfach alle Beschriftungen der Knoten vom kleinsten zum größten durchgegangen. Wenn der Wert der Beschriftung größer als der Wert des MD5-Schlüssels wird, wird dieser Knoten zusammen mit a Anzahl der nachfolgenden Knoten (in der Reihenfolge der Beschriftungen) wird zur Speicherung ausgewählt. Die Gesamtzahl der ausgewählten Knoten muss dem Replikationsfaktor entsprechen. Die Replikationsebene wird für jeden Schlüsselraum festgelegt und ermöglicht die Anpassung der Datenredundanz (Datenredundanz).


Bevor ein Knoten zum Cluster hinzugefügt werden kann, muss ihm ein Label zugewiesen werden. Der Prozentsatz der Schlüssel, die die Lücke zwischen dieser Bezeichnung und der nächsten abdecken, bestimmt, wie viele Daten auf dem Knoten gespeichert werden. Der gesamte Satz von Etiketten für einen Cluster wird als Ring bezeichnet.
Hier ist eine Abbildung, in der das integrierte Dienstprogramm „nodetool“ verwendet wird, um einen Clusterring aus 6 Knoten mit gleichmäßig verteilten Beschriftungen anzuzeigen.

5.2 Datenkonsistenz beim Schreiben
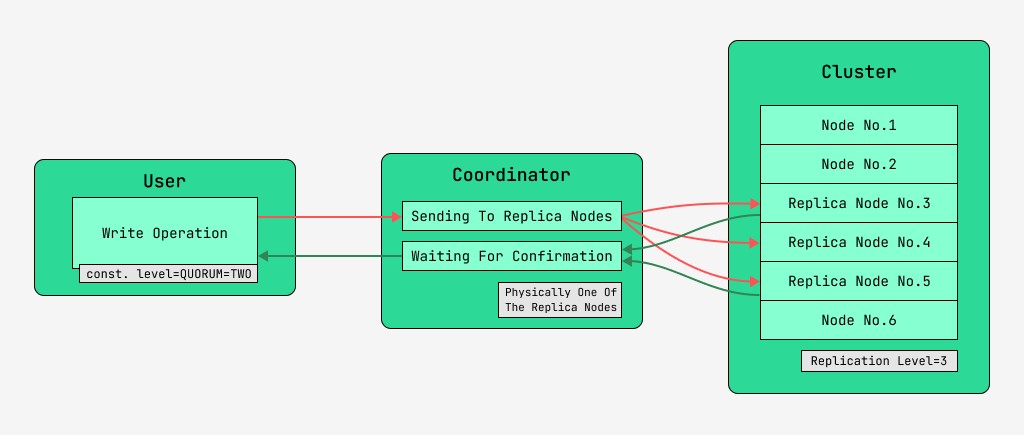
Cassandra-Clusterknoten sind gleichwertig und Clients können mit jedem von ihnen eine Verbindung herstellen, sowohl zum Schreiben als auch zum Lesen. Anfragen durchlaufen die Phase der Koordination, in der der Server, nachdem er mithilfe des Schlüssels und des Markups herausgefunden hat, auf welchen Knoten sich die Daten befinden sollen, Anfragen an diese Knoten sendet. Wir nennen den Knoten, der die Koordination durchführt, den Koordinator und die Knoten, die zum Speichern des Datensatzes mit dem angegebenen Schlüssel ausgewählt werden, die Replikatknoten . Physisch kann einer der Replikatknoten der Koordinator sein – es hängt nur von Schlüssel, Markup und Labels ab.
Für jede Anfrage, sowohl beim Lesen als auch beim Schreiben, ist es möglich, den Grad der Datenkonsistenz festzulegen.
Bei einem Schreibvorgang wirkt sich diese Ebene auf die Anzahl der Replikatknoten aus, die auf die Bestätigung des erfolgreichen Abschlusses des Vorgangs (geschriebene Daten) warten, bevor sie die Kontrolle an den Benutzer zurückgeben. Für eine Aufzeichnung gibt es diese Konsistenzebenen:
- EINS – der Koordinator sendet Anfragen an alle Replikatknoten, gibt aber nach dem Warten auf die Bestätigung vom ersten Knoten die Kontrolle an den Benutzer zurück;
- ZWEI – das Gleiche, aber der Koordinator wartet auf die Bestätigung der ersten beiden Knoten, bevor er die Kontrolle zurückgibt;
- DREI – ähnlich, aber der Koordinator wartet auf die Bestätigung der ersten drei Knoten, bevor er die Kontrolle zurückgibt;
- QUORUM – ein Quorum wird gesammelt: Der Koordinator wartet auf die Bestätigung des Datensatzes von mehr als der Hälfte der Replikatknoten, nämlich Runde (N / 2) + 1, wobei N die Replikationsebene ist;
- LOCAL_QUORUM – Der Koordinator wartet auf die Bestätigung von mehr als der Hälfte der Replikatknoten im selben Rechenzentrum, in dem sich der Koordinator befindet (möglicherweise bei jeder Anfrage unterschiedlich). Ermöglicht Ihnen, die Verzögerungen zu vermeiden, die mit dem Senden von Daten an andere Rechenzentren verbunden sind. Die Probleme bei der Arbeit mit vielen Rechenzentren werden in diesem Artikel am Rande behandelt;
- EACH_QUORUM – Der Koordinator wartet unabhängig voneinander auf die Bestätigung von mehr als der Hälfte der Replikatknoten in jedem Rechenzentrum.
- ALL – der Koordinator wartet auf die Bestätigung von allen Replikatknoten;
- ANY – ermöglicht das Schreiben von Daten, auch wenn nicht alle Replikatknoten antworten. Der Koordinator wartet entweder auf die erste Antwort von einem der Replikatknoten oder darauf, dass die Daten mithilfe einer angedeuteten Übergabe auf dem Koordinator gespeichert werden.
5.3 Datenkonsistenz beim Lesen
Bei Lesevorgängen wirkt sich der Konsistenzgrad auf die Anzahl der Replikatknoten aus, von denen gelesen wird. Zum Lesen gibt es diese Konsistenzstufen:
- EINS – der Koordinator sendet Anfragen an den nächstgelegenen Replikatknoten. Die restlichen Replikate werden ebenfalls zur Lesereparatur mit der in der Cassandra-Konfiguration angegebenen Wahrscheinlichkeit gelesen;
- TWO ist dasselbe, aber der Koordinator sendet Anfragen an die beiden nächstgelegenen Knoten. Der Wert mit dem größten Zeitstempel wird ausgewählt;
- DREI – ähnlich der vorherigen Option, jedoch mit drei Knoten;
- QUORUM – Es wird ein Quorum gesammelt, das heißt, der Koordinator sendet Anfragen an mehr als die Hälfte der Replikatknoten, nämlich Runde (N / 2) + 1, wobei N die Replikationsebene ist;
- LOCAL_QUORUM – im Rechenzentrum, in dem die Koordinierung stattfindet, wird ein Quorum gesammelt und die Daten mit dem neuesten Zeitstempel zurückgegeben;
- EACH_QUORUM – Der Koordinator gibt Daten nach der Sitzung des Quorums in jedem der Rechenzentren zurück;
- ALLE – Der Koordinator gibt Daten zurück, nachdem er von allen Replikatknoten gelesen hat.

Somit ist es möglich, die Zeitverzögerungen von Lese- und Schreibvorgängen anzupassen und die Konsistenz (Tune-Konsistenz) sowie die Verfügbarkeit (Verfügbarkeit) jeder Art von Vorgang anzupassen. Tatsächlich steht die Verfügbarkeit in direktem Zusammenhang mit der Konsistenzebene der Lese- und Schreibvorgänge, da sie bestimmt, wie viele Replikatknoten ausfallen und trotzdem bestätigt werden können.
Wenn die Anzahl der Knoten, von denen die Schreibbestätigung kommt, plus die Anzahl der Knoten, von denen gelesen wird, größer als die Replikationsebene ist, haben wir die Garantie, dass der neue Wert immer nach dem Schreiben gelesen wird, und zwar wird als starke Konsistenz (starke Konsistenz) bezeichnet. Ohne starke Konsistenz besteht die Möglichkeit, dass ein Lesevorgang veraltete Daten zurückgibt.
In jedem Fall wird der Wert schließlich zwischen Replikaten weitergegeben, jedoch erst, nachdem die Koordinationswartezeit beendet ist. Diese Ausbreitung wird als Eventualkonsistenz bezeichnet. Wenn zum Zeitpunkt des Schreibvorgangs nicht alle Replikatknoten verfügbar sind, kommen früher oder später Wiederherstellungstools wie Abhilfe-Lesevorgänge und Anti-Entropie-Knotenreparatur ins Spiel. Mehr dazu später.
Somit wird mit einem QUORUM-Lese- und Schreibkonsistenzniveau immer eine starke Konsistenz aufrechterhalten, und dies wird ein Gleichgewicht zwischen Lese- und Schreiblatenz sein. Bei ALLEN Schreibvorgängen und EINEM Lesevorgang besteht eine starke Konsistenz und die Lesevorgänge sind schneller und verfügbarer, d. h. die Anzahl der ausgefallenen Knoten, an denen ein Lesevorgang noch abgeschlossen wird, kann größer sein als bei QUORUM.
Für Schreibvorgänge sind alle Replikat-Worker-Knoten erforderlich. Beim Schreiben von EINEM und beim Lesen von ALLEN gilt ebenfalls eine strikte Konsistenz, und die Schreibvorgänge sind schneller und die Schreibverfügbarkeit ist groß, da es ausreicht, nur zu bestätigen, dass der Schreibvorgang auf mindestens einem der Server stattgefunden hat Das Lesen ist langsamer und erfordert alle Replikatknoten. Wenn für eine Anwendung keine strenge Konsistenz erforderlich ist, ist es möglich, sowohl Lese- als auch Schreibvorgänge zu beschleunigen und die Verfügbarkeit zu verbessern, indem niedrigere Konsistenzstufen festgelegt werden.