5.1 データの配布
クラスタノード間でキーに応じてデータがどのように分散されるかを考えてみましょう。Cassandra を使用すると、データ分散戦略を設定できます。最初の戦略では、md5 キーの値に応じてデータを分散します (ランダム パーティショナー)。2 つ目では、キー自体のビット表現、つまり序数マークアップ (バイト順のパーティショナー) が考慮されます。
ほとんどの場合、最初の戦略の方が、サーバー間のデータの均等な分散やそのような問題について心配する必要がないため、より多くの利点が得られます。2 番目の戦略は、間隔クエリ (範囲スキャン) が必要な場合など、まれに使用されます。この戦略の選択はクラスターの作成前に行われ、実際にはデータを完全にリロードしないと変更できないことに注意することが重要です。
Cassandra は、コンシステント ハッシュとして知られる技術を使用してデータを分散します。このアプローチにより、ノード間でデータを分散し、新しいノードの追加および削除時に転送されるデータの量を確実に抑えることができます。これを行うために、各ノードにはラベル (トークン) が割り当てられ、すべての md5 キー値のセットが部分に分割されます。RandomPartitionerを使うことが多いので検討してみましょう。
先ほど述べたように、RandomPartitioner はキーごとに 128 ビットの md5 を計算します。データがどのノードに保存されるかを決定するには、単純にノードのすべてのラベルを最小から最大まで調べ、ラベルの値が md5 キーの値より大きくなると、このノードと後続のノードの数 (ラベルの順) がストレージ用に選択されます。選択したノードの合計数はレプリケーション係数と等しくなければなりません。レプリケーション レベルはキースペースごとに設定され、データの冗長性 (データ冗長性) を調整できます。


ノードをクラスターに追加するには、その前にラベルを付ける必要があります。このラベルと次のラベルの間のギャップをカバーするキーの割合によって、ノードに保存されるデータの量が決まります。クラスターのラベルのセット全体はリングと呼ばれます。
以下は、組み込みのnodetoolユーティリティを使用して、等間隔のラベルを持つ6つのノードのクラスタリングを表示する図です。

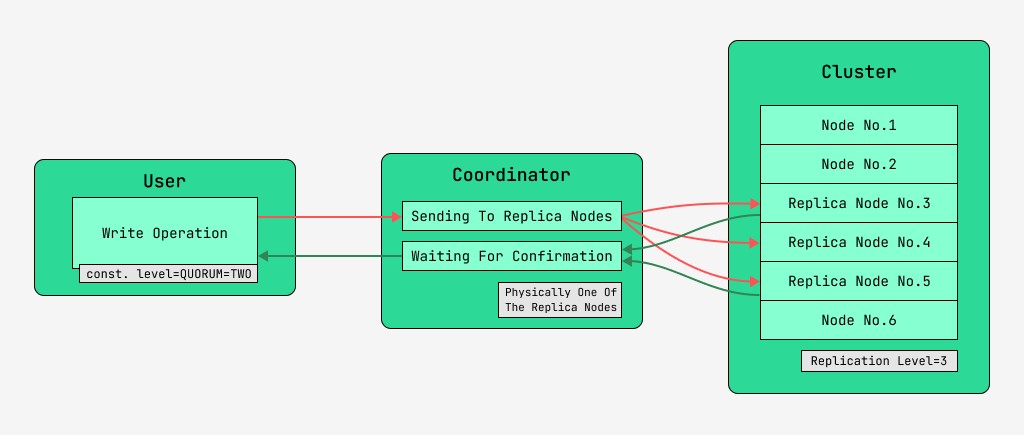
5.2 書き込み時のデータの整合性
Cassandra クラスタ ノードは同等であり、クライアントは書き込みと読み取りの両方でどのノードにも接続できます。リクエストは調整の段階を経ます。この段階で、キーとマークアップを使用してデータを配置する必要があるノードを特定した後、サーバーはこれらのノードにリクエストを送信します。調整を実行するノードをコーディネーターと呼び、指定されたキーを持つレコードを保存するために選択されたノードをレプリカノードと呼びます。物理的には、レプリカ ノードの 1 つがコーディネーターになることができます。コーディネーターは、キー、マークアップ、およびラベルにのみ依存します。
読み取りと書き込みの両方のリクエストごとに、データの一貫性のレベルを設定できます。
書き込みの場合、このレベルは、ユーザーに制御を返す前に、操作の正常な完了 (データの書き込み) の確認を待機するレプリカ ノードの数に影響します。記録として、次の整合性レベルがあります。
- ONE - コーディネーターはすべてのレプリカ ノードにリクエストを送信しますが、最初のノードからの確認を待った後、制御をユーザーに返します。
- 2 - 同じですが、コーディネーターは制御を返す前に最初の 2 つのノードからの確認を待ちます。
- THREE - 同様ですが、コーディネーターは制御を返す前に最初の 3 つのノードからの確認を待ちます。
- QUORUM - クォーラムが収集されます。コーディネーターは、半分以上のレプリカ ノードからのレコードの確認、つまり丸め (N / 2) + 1 (N はレプリケーション レベル) を待っています。
- LOCAL_QUORUM - コーディネーターは、コーディネーターが配置されている同じデータセンター内のレプリカ ノードの半分以上からの確認を待っています (リクエストごとに異なる可能性があります)。他のデータセンターへのデータ送信に伴う遅延を解消できます。多くのデータセンターと連携する場合の問題については、この記事でついでに検討します。
- EACH_QUORUM - コーディネーターは、各データ センター内のレプリカ ノードの半分以上からの確認を個別に待機しています。
- ALL - コーディネーターはすべてのレプリカ ノードからの確認を待ちます。
- ANY - すべてのレプリカ ノードが応答していない場合でも、データを書き込むことができます。コーディネーターは、レプリカ ノードの 1 つからの最初の応答を待つか、コーディネーターでのヒント付きハンドオフを使用してデータが保存されるまで待機します。
5.3 読み取り時のデータの一貫性
読み取りの場合、整合性レベルは読み取り元のレプリカ ノードの数に影響します。読み取りの場合、次の整合性レベルがあります。
- ONE - コーディネーターはリクエストを最も近いレプリカ ノードに送信します。残りのレプリカも、cassandra 設定で指定された確率で読み取り修復のために読み取られます。
- TWOは同じですが、コーディネーターは最も近い 2 つのノードにリクエストを送信します。最大のタイムスタンプを持つ値が選択されます。
- THREE - 前のオプションと似ていますが、ノードが 3 つあります。
- QUORUM - クォーラムが収集されます。つまり、コーディネーターは半分以上のレプリカ ノードにリクエストを送信します。つまり、(N / 2) + 1 を丸めます。N はレプリケーション レベルです。
- LOCAL_QUORUM - クォーラムは調整が行われるデータ センターに収集され、最新のタイムスタンプを持つデータが返されます。
- EACH_QUORUM - コーディネーターは、各データセンターでクォーラムが満たされた後にデータを返します。
- ALL - コーディネーターは、すべてのレプリカ ノードからの読み取り後にデータを返します。

したがって、読み取りおよび書き込み操作の時間遅延を調整し、各種類の操作の可用性 (可用性) だけでなく、一貫性 (調整の一貫性) も調整することができます。実際、可用性は、ダウンしても確認できるレプリカ ノードの数を決定するため、読み取りと書き込みの一貫性レベルに直接関係します。
書き込み確認が送信されたノードの数と読み取りが行われたノードの数がレプリケーション レベルより大きい場合、書き込み後に常に新しい値が読み取られることが保証されます。強整合性(強整合性)と呼ばれます。強い一貫性がない場合、読み取り操作で古いデータが返される可能性があります。
いずれの場合も、値は最終的にレプリカ間で伝播されますが、それは調整待機が終了した後でのみです。この伝播は結果整合性と呼ばれます。書き込み時にすべてのレプリカ ノードが利用可能ではない場合は、遅かれ早かれ、修復読み取りやアンチエントロピー ノード修復などの回復ツールが登場します。これについては後で詳しく説明します。
したがって、QUORUM の読み取りおよび書き込みの整合性レベルでは、強い整合性が常に維持され、これにより読み取りと書き込みの遅延のバランスが取れます。ALL 書き込みと 1 つの読み取りでは、強い整合性が確保され、読み取りが高速になり、より多くの可用性が得られます。つまり、読み取りが完了するまでに障害が発生したノードの数が QUORUM よりも多くなる可能性があります。
書き込み操作には、すべてのレプリカ ワーカー ノードが必要です。ONE に書き込み、ALL を読み取る場合も厳密な一貫性があり、書き込み操作が少なくとも 1 つのサーバーで行われたことを確認するだけで十分であるため、書き込み操作が高速になり、書き込み可用性が大きくなります。読み取りは遅くなり、すべてのレプリカ ノードが必要になります。アプリケーションに厳密な一貫性の要件がない場合は、一貫性レベルを低く設定することで、読み取り操作と書き込み操作の両方を高速化し、可用性を向上させることができます。