5.1 डेटा वितरण
क्लस्टर नोड्समधील कीच्या आधारावर डेटा कसा वितरित केला जातो याचा विचार करूया. Cassandra तुम्हाला डेटा वितरण धोरण सेट करण्याची परवानगी देते. अशी पहिली स्ट्रॅटेजी md5 की मूल्यावर अवलंबून डेटा वितरित करते - एक यादृच्छिक विभाजनकर्ता. दुसरा कीचे स्वतःचे बिट प्रतिनिधित्व लक्षात घेते - ऑर्डिनल मार्कअप (बाइट-ऑर्डर केलेले विभाजन).
प्रथम रणनीती, बहुतेक भागांसाठी, अधिक फायदे देते, कारण आपल्याला सर्व्हर आणि अशा समस्यांमधील डेटाच्या वितरणाबद्दल काळजी करण्याची आवश्यकता नाही. दुसरी रणनीती दुर्मिळ प्रकरणांमध्ये वापरली जाते, उदाहरणार्थ, जर अंतराल क्वेरी (श्रेणी स्कॅन) आवश्यक असतील. हे लक्षात घेणे महत्त्वाचे आहे की या धोरणाची निवड क्लस्टरच्या निर्मितीपूर्वी केली जाते आणि प्रत्यक्षात डेटा पूर्ण रीलोड केल्याशिवाय बदलता येत नाही.
कॅसॅंड्रा डेटा वितरित करण्यासाठी सातत्यपूर्ण हॅशिंग म्हणून ओळखले जाणारे तंत्र वापरते. हा दृष्टीकोन तुम्हाला नोड्स दरम्यान डेटा वितरीत करण्यास आणि नवीन नोड जोडला आणि काढला जातो तेव्हा हस्तांतरित केलेल्या डेटाचे प्रमाण कमी असल्याचे सुनिश्चित करण्याची परवानगी देतो. हे करण्यासाठी, प्रत्येक नोडला एक लेबल (टोकन) नियुक्त केले जाते, जे सर्व md5 की व्हॅल्यूजच्या संचाला भागांमध्ये विभाजित करते. RandomPartitioner बहुतेक प्रकरणांमध्ये वापरले जात असल्याने, त्याचा विचार करूया.
मी म्हटल्याप्रमाणे, RandomPartitioner प्रत्येक कीसाठी 128-बिट md5 मोजतो. डेटा कोणत्या नोड्समध्ये संग्रहित केला जाईल हे निर्धारित करण्यासाठी, ते फक्त सर्वात लहान ते सर्वात मोठ्या नोड्सच्या सर्व लेबलांमधून जाते आणि जेव्हा लेबलचे मूल्य md5 कीच्या मूल्यापेक्षा मोठे होते, तेव्हा हा नोड, स्टोरेजसाठी त्यानंतरच्या नोड्सची संख्या (लेबलच्या क्रमाने) निवडली आहे. निवडलेल्या नोड्सची एकूण संख्या प्रतिकृती घटकाच्या समान असणे आवश्यक आहे. प्रतिकृती पातळी प्रत्येक कीस्पेससाठी सेट केली जाते आणि तुम्हाला डेटाची रिडंडंसी (डेटा रिडंडंसी) समायोजित करण्याची परवानगी देते.


क्लस्टरमध्ये नोड जोडण्याआधी, त्याला लेबल दिले जाणे आवश्यक आहे. या लेबल आणि पुढीलमधील अंतर कव्हर करणार्या कीची टक्केवारी नोडवर किती डेटा संग्रहित केला जाईल हे निर्धारित करते. क्लस्टरसाठी लेबल्सच्या संपूर्ण संचाला रिंग म्हणतात.
समान अंतरावर असलेल्या लेबलसह 6 नोड्सची क्लस्टर रिंग प्रदर्शित करण्यासाठी अंगभूत नोडटूल युटिलिटी वापरून येथे एक उदाहरण दिले आहे.

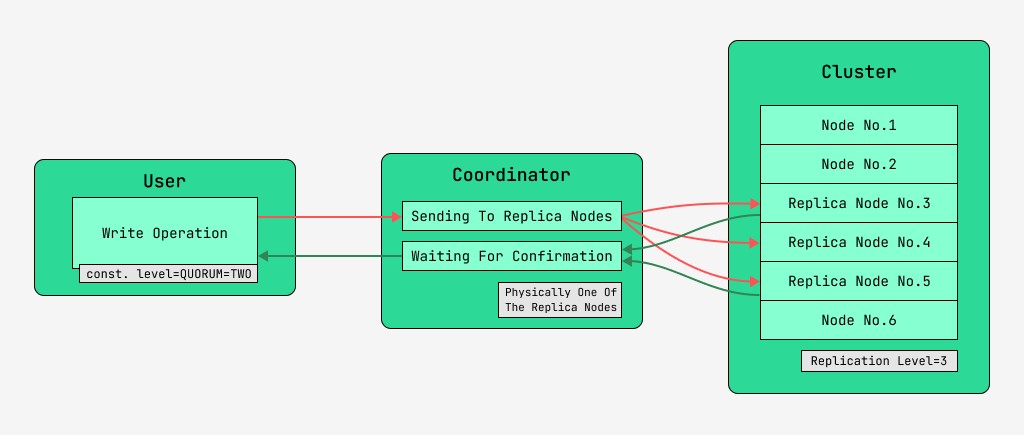
5.2 लिहिताना डेटा सुसंगतता
कॅसॅंड्रा क्लस्टर नोड्स समतुल्य आहेत आणि क्लायंट त्यांपैकी कोणत्याहीशी, लेखन आणि वाचन दोन्हीसाठी कनेक्ट करू शकतात. विनंत्या समन्वयाच्या टप्प्यातून जातात, त्या दरम्यान, की आणि मार्कअपच्या मदतीने डेटा कोणत्या नोड्सवर स्थित असावा हे शोधून काढल्यानंतर, सर्व्हर या नोड्सना विनंत्या पाठवतो. आम्ही समन्वय साधणार्या नोडला समन्वयक म्हणू आणि दिलेल्या कीसह रेकॉर्ड सेव्ह करण्यासाठी निवडलेल्या नोड्स, प्रतिकृती नोड्स. भौतिकदृष्ट्या, प्रतिकृती नोड्सपैकी एक समन्वयक असू शकतो - ते फक्त की, मार्कअप आणि लेबलांवर अवलंबून असते.
प्रत्येक विनंतीसाठी, वाचन आणि लेखन दोन्हीसाठी, डेटा सुसंगततेची पातळी सेट करणे शक्य आहे.
लेखनासाठी, ही पातळी प्रतिकृती नोड्सच्या संख्येवर परिणाम करेल जे वापरकर्त्याला नियंत्रण परत करण्यापूर्वी ऑपरेशनच्या यशस्वी पूर्ततेची (डेटा लिहिलेली) पुष्टी होण्याची प्रतीक्षा करेल. रेकॉर्डसाठी, या सातत्य पातळी आहेत:
- एक - समन्वयक सर्व प्रतिकृती नोड्सना विनंत्या पाठवतो, परंतु पहिल्या नोडच्या पुष्टीकरणाची प्रतीक्षा केल्यानंतर, वापरकर्त्याला नियंत्रण परत करतो;
- दोन - समान, परंतु समन्वयक नियंत्रण परत करण्यापूर्वी पहिल्या दोन नोड्समधून पुष्टीकरणाची प्रतीक्षा करतो;
- तीन - समान, परंतु समन्वयक नियंत्रण परत करण्यापूर्वी पहिल्या तीन नोड्समधून पुष्टीकरणाची प्रतीक्षा करतो;
- कोरम - एक कोरम गोळा केला जातो: समन्वयक अर्ध्याहून अधिक प्रतिकृती नोड्समधून रेकॉर्डच्या पुष्टीकरणाची वाट पाहत आहे, म्हणजे गोल (N / 2) + 1, जेथे N ही प्रतिकृती पातळी आहे;
- LOCAL_QUORUM - समन्वयक जिथे समन्वयक स्थित आहे त्याच डेटा सेंटरमधील अर्ध्याहून अधिक प्रतिकृती नोड्सकडून पुष्टीकरणाची प्रतीक्षा करत आहे (प्रत्येक विनंतीसाठी संभाव्यतः भिन्न). इतर डेटा केंद्रांना डेटा पाठविण्याशी संबंधित विलंबांपासून मुक्त होण्यास आपल्याला अनुमती देते. बर्याच डेटा सेंटर्ससह कार्य करण्याचे मुद्दे या लेखात उत्तीर्णपणे विचारात घेतले आहेत;
- EACH_QUORUM - समन्वयक स्वतंत्रपणे, प्रत्येक डेटा सेंटरमधील अर्ध्याहून अधिक प्रतिकृती नोड्सकडून पुष्टीकरणाची वाट पाहत आहे;
- सर्व - समन्वयक सर्व प्रतिकृती नोड्सकडून पुष्टीकरणाची प्रतीक्षा करतो;
- कोणतीही - सर्व प्रतिकृती नोड प्रतिसाद देत नसले तरीही डेटा लिहिणे शक्य करते. संयोजक एकतर प्रतिकृती नोड्सपैकी एकाच्या पहिल्या प्रतिसादाची किंवा समन्वयकावर सूचित हँडऑफ वापरून डेटा संग्रहित करण्यासाठी प्रतीक्षा करतो.
5.3 वाचताना डेटा सुसंगतता
वाचनासाठी, सुसंगतता पातळी प्रतिकृती नोड्सच्या संख्येवर परिणाम करेल जे वाचले जातील. वाचनासाठी, या सातत्य पातळी आहेत:
- एक - समन्वयक जवळच्या प्रतिकृती नोडला विनंती पाठवतो. उर्वरित प्रतिकृती देखील कॅसँड्रा कॉन्फिगरेशनमध्ये निर्दिष्ट केलेल्या संभाव्यतेसह वाचन दुरुस्तीसाठी वाचल्या जातात;
- TWO समान आहे, परंतु समन्वयक दोन जवळच्या नोड्सना विनंत्या पाठवतो. सर्वात मोठ्या टाइमस्टॅम्पसह मूल्य निवडले आहे;
- तीन - मागील पर्यायाप्रमाणेच, परंतु तीन नोड्ससह;
- कोरम - एक कोरम गोळा केला जातो, म्हणजेच समन्वयक अर्ध्याहून अधिक प्रतिकृती नोड्सना विनंत्या पाठवतो, म्हणजे गोल (N / 2) + 1, जेथे N ही प्रतिकृती पातळी आहे;
- LOCAL_QUORUM - डेटा सेंटरमध्ये एक कोरम गोळा केला जातो ज्यामध्ये समन्वय होतो आणि नवीनतम टाइमस्टॅम्पसह डेटा परत केला जातो;
- EACH_QUORUM - प्रत्येक डेटा सेंटरमध्ये कोरम पूर्ण झाल्यानंतर समन्वयक डेटा परत करतो;
- सर्व - सर्व प्रतिकृती नोड्समधून वाचल्यानंतर समन्वयक डेटा परत करतो.

अशा प्रकारे, वाचन आणि लेखन ऑपरेशन्सचा वेळ विलंब समायोजित करणे आणि सुसंगतता (ट्यून सुसंगतता), तसेच प्रत्येक प्रकारच्या ऑपरेशनची उपलब्धता (उपलब्धता) समायोजित करणे शक्य आहे. खरं तर, उपलब्धता थेट वाचन आणि लेखनाच्या सातत्य पातळीशी संबंधित आहे, कारण ते किती प्रतिकृती नोड खाली जाऊ शकतात आणि तरीही पुष्टी केली जाऊ शकतात हे निर्धारित करते.
ज्या नोड्समधून लेखन पावती येते, तसेच ज्या नोड्समधून वाचन केले जाते त्यांची संख्या, प्रतिकृती पातळीपेक्षा जास्त असल्यास, आम्हाला हमी आहे की नवीन मूल्य नेहमी लिहिल्यानंतर वाचले जाईल, आणि हे मजबूत सुसंगतता (मजबूत सातत्य) म्हणतात. मजबूत सुसंगततेच्या अनुपस्थितीत, एक वाचन ऑपरेशन जुना डेटा परत करेल अशी शक्यता आहे.
कोणत्याही परिस्थितीत, मूल्य शेवटी प्रतिकृती दरम्यान प्रसारित होईल, परंतु समन्वय प्रतीक्षा संपल्यानंतरच. या प्रसाराला अंतिम सुसंगतता म्हणतात. लेखनाच्या वेळी सर्व प्रतिकृती नोड उपलब्ध नसल्यास, लवकर किंवा नंतर पुनर्प्राप्ती साधने जसे की उपचारात्मक वाचन आणि अँटी-एंट्रोपी नोड दुरुस्ती कार्यात येतील. याबद्दल अधिक नंतर.
अशा प्रकारे, QUORUM वाचन आणि लेखन सातत्य पातळीसह, मजबूत सातत्य नेहमीच राखले जाईल, आणि हे वाचन आणि लेखन विलंब दरम्यान संतुलन असेल. सर्व लेखन आणि एक वाचनासह मजबूत सुसंगतता असेल आणि वाचन जलद आणि अधिक उपलब्ध असेल, म्हणजे अयशस्वी नोड्सची संख्या ज्यावर वाचन पूर्ण केले जाईल ते QUORUM पेक्षा जास्त असू शकते.
लेखन ऑपरेशन्ससाठी, सर्व प्रतिकृती वर्कर नोड्स आवश्यक असतील. एक लिहिताना, सर्व वाचताना, कठोर सुसंगतता देखील असेल आणि लेखन ऑपरेशन्स जलद होतील आणि लिहिण्याची उपलब्धता मोठी असेल, कारण लेखन ऑपरेशन कमीतकमी एका सर्व्हरवर झाले आहे याची पुष्टी करण्यासाठी ते पुरेसे असेल. वाचन हळू आहे आणि सर्व प्रतिकृती नोड्स आवश्यक आहेत. जर एखाद्या ऍप्लिकेशनला कठोर सुसंगततेची आवश्यकता नसेल, तर वाचन आणि लेखन या दोन्ही क्रियांचा वेग वाढवणे तसेच कमी सुसंगतता पातळी सेट करून उपलब्धता सुधारणे शक्य आहे.