Hej! Dagens lektion vil være lidt anderledes end resten. Det vil adskille sig ved, at det kun er indirekte relateret til Java. Når det er sagt, er dette emne meget vigtigt for enhver programmør. Vi skal tale om algoritmer . Hvad er en algoritme? Enkelt sagt er det en række handlinger, der skal udføres for at opnå et ønsket resultat . Vi bruger ofte algoritmer i hverdagen. For eksempel har du hver morgen en bestemt opgave: gå i skole eller arbejde, og samtidig være:
Påklædt
Ren
Fed
Hvilken algoritme lader dig opnå dette resultat?
Vågn op ved hjælp af et vækkeur.
Tag et brusebad og vask dig selv.
Lav morgenmad og noget kaffe eller te.
Spise.
Hvis du ikke har stryget dit tøj den foregående aften, så stryg det.
Få tøj på.
Forlad huset.
Denne sekvens af handlinger vil helt sikkert lade dig få det ønskede resultat. Inden for programmering arbejder vi konstant på at løse opgaver. En betydelig del af disse opgaver kan udføres ved hjælp af algoritmer, der allerede er kendte. Antag for eksempel, at din opgave er at sortere en liste med 100 navne i et array . Denne opgave er ret enkel, men den kan løses på forskellige måder. Her er en mulig løsning: Algoritme til alfabetisk sortering af navne:
Køb eller download 1961-udgaven af Webster's Third New International Dictionary.
Find hvert navn fra vores liste i denne ordbog.
På et stykke papir skal du skrive den side i ordbogen, hvor navnet står.
Brug stykkerne papir til at sortere navnene.
Vil en sådan sekvens af handlinger udføre vores opgave? Ja, det vil det bestemt. Er denne løsning effektiv ? Næsten. Her kommer vi til et andet meget vigtigt aspekt af algoritmer: deres effektivitet . Der er flere måder at udføre denne opgave på. Men både i programmering og i det almindelige liv ønsker vi at vælge den mest effektive måde. Hvis din opgave er at lave et smurt stykke toast, kan du starte med at så hvede og malke en ko. Men det ville være ineffektivtløsning — det vil tage meget tid og vil koste mange penge. Du kan klare din enkle opgave ved blot at købe brød og smør. Selvom det giver dig mulighed for at løse problemet, er algoritmen, der involverer hvede og en ko, for kompleks til at bruge i praksis. I programmering har vi speciel notation kaldet big O notation til at vurdere kompleksiteten af algoritmer. Big O gør det muligt at vurdere, hvor meget en algoritmes eksekveringstid afhænger af inputdatastørrelsen . Lad os se på det enkleste eksempel: dataoverførsel. Forestil dig, at du skal sende nogle oplysninger i form af en fil over en lang afstand (for eksempel 5000 miles). Hvilken algoritme ville være mest effektiv? Det afhænger af de data, du arbejder med. Antag for eksempel, at vi har en lydfil på 10 MB. I dette tilfælde er den mest effektive algoritme at sende filen over internettet. Det kunne ikke tage mere end et par minutter! Lad os gentage vores algoritme: "Hvis du ønsker at overføre information i form af filer over en afstand på 5000 miles, skal du sende dataene via internettet". Fremragende. Lad os nu analysere det. Løser det vores opgave?Nå, ja, det gør det. Men hvad kan vi sige om dens kompleksitet? Hmm, nu bliver tingene mere interessante. Faktum er, at vores algoritme er meget afhængig af inputdataene, nemlig størrelsen på filerne. Hvis vi har 10 megabyte, så er alt fint. Men hvad hvis vi skal sende 500 megabyte? 20 gigabyte? 500 terabyte? 30 petabyte? Holder vores algoritme op med at virke? Nej, alle disse mængder af data kan faktisk overføres. Vil det tage længere tid? Ja, det vil! Nu kender vi en vigtig funktion ved vores algoritme: Jo større mængde data der skal sendes, jo længere tid vil det tage at køre algoritmen. Men vi vil gerne have en mere præcis forståelse af dette forhold (mellem størrelsen på inputdata og den tid, det tager at sende det). I vores tilfælde er den algoritmiske kompleksitet lineær . "Lineær" betyder, at når mængden af inputdata stiger, vil den tid, det tager at sende dem, stige omtrent proportionalt. Hvis mængden af data fordobles, vil den tid, der kræves for at sende den, være dobbelt så meget. Hvis data stiger med 10 gange, så vil transmissionstiden øges 10 gange. Ved at bruge stor O-notation udtrykkes kompleksiteten af vores algoritme som O(n). Du bør huske denne notation for fremtiden - den bruges altid til algoritmer med lineær kompleksitet. Bemærk, at vi ikke taler om flere ting, der kan variere her: Internethastighed, vores computers regnekraft og så videre. Når man vurderer kompleksiteten af en algoritme, giver det simpelthen ikke mening at overveje disse faktorer - under alle omstændigheder er de uden for vores kontrol. Big O-notation udtrykker kompleksiteten af selve algoritmen, ikke det "miljø", som den kører i. Lad os fortsætte med vores eksempel. Antag, at vi i sidste ende lærer, at vi skal sende filer på i alt 800 terabyte. Vi kan selvfølgelig løse vores opgave ved at sende dem over internettet. Der er kun et problem: ved standard husstandsdatatransmissionshastigheder (100 megabit pr. sekund) vil det tage cirka 708 dage. Næsten 2 år! :O Vores algoritme passer åbenbart ikke godt her. Vi har brug for en anden løsning! Uventet kommer IT-giganten Amazon os til undsætning! Amazons snescootertjeneste lader os uploade en stor mængde data til mobillager og derefter levere det til den ønskede adresse med lastbil! Så vi har en ny algoritme! "Hvis du ønsker at overføre information i form af filer over en afstand på 5000 miles, og det ville tage mere end 14 dage at sende det via internettet, bør du sende dataene på en Amazon-lastbil." Vi valgte 14 dage vilkårligt her. Lad os sige, at dette er den længste periode, vi kan vente. Lad os analysere vores algoritme. Hvad med dens hastighed? Selvom lastbilen kun kører med 50 mph, vil den tilbagelægge 5000 miles på kun 100 timer. Det er lidt over fire dage! Dette er meget bedre end muligheden for at sende dataene over internettet. Og hvad med kompleksiteten af denne algoritme? Er det også lineært, altså O(n)? Nej det er ikke. Når alt kommer til alt, er lastbilen ligeglad med, hvor tungt du læsser den – den vil stadig køre med nogenlunde samme hastighed og nå frem til tiden. Uanset om vi har 800 terabyte eller 10 gange det, når lastbilen stadig sin destination inden for 5 dage. Med andre ord har den lastbilbaserede dataoverførselsalgoritme konstant kompleksitet. Her betyder "konstant", at den ikke afhænger af inputdatastørrelsen. Sæt et 1GB flashdrev i lastbilen, det vil ankomme inden for 5 dage. Sæt i diske, der indeholder 800 terabyte data, vil de ankomme inden for 5 dage. Når du bruger stor O-notation, er konstant kompleksitet angivet med O(1) . Vi er blevet fortrolige med O(n) og O(1) , så lad os nu se på flere eksempler i programmeringsverdenen :) Antag at du får en matrix med 100 numre, og opgaven er at vise hver af dem på konsollen. Du skriver en almindelig forloop, der udfører denne opgave
int[] numbers = new int[100];
// ...fill the array with numbers
for (int i: numbers) {
System.out.println(i);
}
Hvad er kompleksiteten af denne algoritme? Lineær, dvs. O(n). Antallet af handlinger, som programmet skal udføre, afhænger af, hvor mange numre, der sendes til det. Hvis der er 100 tal i arrayet, vil der være 100 handlinger (udsagn til at vise strenge på skærmen). Hvis der er 10.000 numre i arrayet, skal der udføres 10.000 handlinger. Kan vores algoritme forbedres på nogen måde? Nej. Lige meget hvad, bliver vi nødt til at lave N passerer gennem arrayet og udføre N sætninger for at vise strenge på konsollen. Overvej et andet eksempel.
public static void main(String[] args) {
LinkedList<Integer> numbers = new LinkedList<>();
numbers.add(0, 20202);
numbers.add(0, 123);
numbers.add(0, 8283);
}
Vi har en tom LinkedList, hvor vi indsætter flere tal. Vi er nødt til at evaluere den algoritmiske kompleksitet ved at indsætte et enkelt tal i LinkedListvores eksempel, og hvordan det afhænger af antallet af elementer på listen. Svaret er O(1), altså konstant kompleksitet . Hvorfor? Bemærk, at vi indsætter hvert tal i begyndelsen af listen. Derudover vil du huske, at når du indsætter et tal i en LinkedList, flytter elementerne sig ingen steder. Linkene (eller referencerne) er opdateret (hvis du har glemt, hvordan LinkedList fungerer, så kig på en af vores gamle lektioner ). Hvis det første tal på vores liste er x, og vi indsætter tallet y foran på listen, skal vi kun gøre dette:
x.previous = y;
y.previous = null;
y.next = x;
Når vi opdaterer linkene, er vi ligeglade med, hvor mange tal der allerede er iLinkedList , om en eller en milliard. Algoritmens kompleksitet er konstant, altså O(1).
Logaritmisk kompleksitet
Gå ikke i panik! :) Hvis ordet "logaritmisk" giver dig lyst til at lukke denne lektion og stoppe med at læse, skal du bare holde et par minutter. Der vil ikke være nogen vanvittig matematik her (der er masser af den slags forklaringer andre steder), og vi vil udskille hvert eksempel. Forestil dig, at din opgave er at finde et bestemt tal i en række af 100 tal. Mere præcist skal du tjekke, om det er der eller ej. Så snart det nødvendige nummer er fundet, afsluttes søgningen, og du viser følgende i konsollen: "Det nødvendige nummer blev fundet! Dets indeks i arrayet = ...." Hvordan ville du udføre denne opgave? Her er løsningen indlysende: du skal iterere over elementerne i arrayet én efter én, begyndende fra det første (eller fra det sidste) og kontrollere, om det aktuelle nummer matcher det, du leder efter. Derfor, antallet af handlinger afhænger direkte af antallet af elementer i arrayet. Hvis vi har 100 tal, kan vi potentielt være nødt til at gå til det næste element 100 gange og udføre 100 sammenligninger. Hvis der er 1000 tal, så kan der være 1000 sammenligninger. Dette er åbenbart lineær kompleksitet, dvsO(n) . Og nu vil vi tilføje en forfining til vores eksempel: den matrix, hvor du skal finde tallet, er sorteret i stigende rækkefølge . Ændrer dette noget i forhold til vores opgave? Vi kunne stadig udføre en brute-force-søgning efter det ønskede nummer. Men alternativt kunne vi bruge den velkendte binære søgealgoritme . I den øverste række i billedet ser vi et sorteret array. Vi skal finde tallet 23 i den. I stedet for at iterere over tallene, deler vi simpelthen arrayet i 2 dele og tjekker det midterste tal i arrayet. Find det tal, der er placeret i celle 4, og tjek det (anden række i billedet). Dette tal er 16, og vi leder efter 23. Det nuværende antal er mindre end det, vi leder efter. Hvad betyder det? Det betyder atalle de tidligere numre (dem, der er placeret før tallet 16) behøver ikke at blive kontrolleret : de er garanteret mindre end det, vi leder efter, fordi vores array er sorteret! Vi fortsætter søgningen blandt de resterende 5 elementer. Bemærk:vi har kun foretaget én sammenligning, men vi har allerede elimineret halvdelen af de mulige muligheder. Vi har kun 5 elementer tilbage. Vi vil gentage vores forrige trin ved endnu en gang at dele det resterende underarray i to og igen tage det midterste element (den 3. række i billedet). Tallet er 56, og det er større end det, vi leder efter. Hvad betyder det? Det betyder, at vi har elimineret yderligere 3 muligheder: selve tallet 56 samt de to numre efter det (da de med garanti er større end 23, fordi arrayet er sorteret). Vi har kun 2 tal tilbage at kontrollere (den sidste række i billedet) — tallene med matrixindeks 5 og 6. Vi tjekker det første af dem, og finder det, vi ledte efter — tallet 23! Dens indeks er 5! Lad os se på resultaterne af vores algoritme, og så vil analysere dens kompleksitet. Forresten, nu forstår du, hvorfor dette kaldes binær søgning: den er afhængig af gentagne gange at dele dataene i to. Resultatet er imponerende! Hvis vi brugte en lineær søgning til at lede efter tallet, ville vi have brug for op til 10 sammenligninger, men med en binær søgning klarede vi opgaven med kun 3! I værste fald ville der være 4 sammenligninger (hvis det tal, vi ønskede i det sidste trin, var det andet af de resterende muligheder, snarere end det første. Så hvad med dets kompleksitet? Dette er et meget interessant punkt :) Den binære søgealgoritme er meget mindre afhængig af antallet af elementer i arrayet end den lineære søgealgoritme (det vil sige simpel iteration). Med 10 elementer i arrayet vil en lineær søgning maksimalt kræve 10 sammenligninger, men en binær søgning vil højst have brug for 4 sammenligninger. Det er en forskel på en faktor på 2,5. Men for en matrix på 1000 elementer vil en lineær søgning kræve op til 1000 sammenligninger, men en binær søgning ville kun kræve 10 ! Forskellen er nu 100 gange! Bemærk:antallet af elementer i arrayet er steget 100 gange (fra 10 til 1000), men antallet af sammenligninger, der kræves til en binær søgning, er kun steget med en faktor på 2,5 (fra 4 til 10). Hvis vi når til 10.000 elementer , vil forskellen være endnu mere imponerende: 10.000 sammenligninger til lineær søgning og i alt 14 sammenligninger til binær søgning. Og igen, hvis antallet af elementer stiger med 1000 gange (fra 10 til 10000), så stiger antallet af sammenligninger med en faktor på kun 3,5 (fra 4 til 14). Kompleksiteten af den binære søgealgoritme er logaritmisk , eller, hvis vi bruger stor O-notation, O(log n). Hvorfor hedder det det? Logaritmen er som det modsatte af eksponentiering. Den binære logaritme er den potens, som tallet 2 skal hæves til for at opnå et tal. For eksempel har vi 10.000 elementer, som vi skal søge ved hjælp af den binære søgealgoritme. I øjeblikket kan du se på værditabellen for at vide, at dette vil kræve maksimalt 14 sammenligninger. Men hvad hvis ingen har leveret sådan en tabel, og du skal beregne det nøjagtige maksimale antal sammenligninger? Du skal bare svare på et simpelt spørgsmål: til hvilken styrke skal du hæve tallet 2, så resultatet er større end eller lig med antallet af elementer, der skal kontrolleres? For 10.000 er det 14. potens. 2 til 13. potens er for lille (8192), men 2 til 14. potens = 16384, og dette tal opfylder vores betingelse (det er større end eller lig med antallet af elementer i arrayet). Vi fandt logaritmen: 14. Så mange sammenligninger kan vi have brug for! :) Algoritmer og algoritmisk kompleksitet er et for bredt emne til at passe ind i én lektion. Men at vide det er meget vigtigt: Mange jobsamtaler vil involvere spørgsmål, der involverer algoritmer. I teorien kan jeg anbefale nogle bøger til dig. Du kan starte med " Grokking Algorithms ". Eksemplerne i denne bog er skrevet i Python, men bogen bruger meget simpelt sprog og eksempler. Det er den bedste mulighed for en begynder, og hvad mere er, den er ikke særlig stor. Blandt mere seriøs læsning har vi bøger af Robert Lafore og Robert Sedgewick. Begge er skrevet i Java, hvilket vil gøre indlæringen lidt nemmere for dig. Når alt kommer til alt, er du ganske fortrolig med dette sprog! :) For elever med gode matematiske færdigheder er den bedste mulighed Thomas Cormens bog . Men teori alene vil ikke fylde din mave! Viden != Evne . Du kan øve dig i at løse problemer, der involverer algoritmer, på HackerRank og LeetCode . Opgaver fra disse hjemmesider bliver ofte brugt selv under interviews hos Google og Facebook, så du kommer bestemt ikke til at kede dig :) For at forstærke dette lektionsmateriale anbefaler jeg, at du ser denne fremragende video om big O notation på YouTube. Vi ses i de næste lektioner! :)
 Når det er sagt, er dette emne meget vigtigt for enhver programmør. Vi skal tale om algoritmer . Hvad er en algoritme? Enkelt sagt er det en række handlinger, der skal udføres for at opnå et ønsket resultat . Vi bruger ofte algoritmer i hverdagen. For eksempel har du hver morgen en bestemt opgave: gå i skole eller arbejde, og samtidig være:
Når det er sagt, er dette emne meget vigtigt for enhver programmør. Vi skal tale om algoritmer . Hvad er en algoritme? Enkelt sagt er det en række handlinger, der skal udføres for at opnå et ønsket resultat . Vi bruger ofte algoritmer i hverdagen. For eksempel har du hver morgen en bestemt opgave: gå i skole eller arbejde, og samtidig være:
 I dette tilfælde er den mest effektive algoritme at sende filen over internettet. Det kunne ikke tage mere end et par minutter! Lad os gentage vores algoritme: "Hvis du ønsker at overføre information i form af filer over en afstand på 5000 miles, skal du sende dataene via internettet". Fremragende. Lad os nu analysere det. Løser det vores opgave?Nå, ja, det gør det. Men hvad kan vi sige om dens kompleksitet? Hmm, nu bliver tingene mere interessante. Faktum er, at vores algoritme er meget afhængig af inputdataene, nemlig størrelsen på filerne. Hvis vi har 10 megabyte, så er alt fint. Men hvad hvis vi skal sende 500 megabyte? 20 gigabyte? 500 terabyte? 30 petabyte? Holder vores algoritme op med at virke? Nej, alle disse mængder af data kan faktisk overføres. Vil det tage længere tid? Ja, det vil! Nu kender vi en vigtig funktion ved vores algoritme: Jo større mængde data der skal sendes, jo længere tid vil det tage at køre algoritmen. Men vi vil gerne have en mere præcis forståelse af dette forhold (mellem størrelsen på inputdata og den tid, det tager at sende det). I vores tilfælde er den algoritmiske kompleksitet lineær . "Lineær" betyder, at når mængden af inputdata stiger, vil den tid, det tager at sende dem, stige omtrent proportionalt. Hvis mængden af data fordobles, vil den tid, der kræves for at sende den, være dobbelt så meget. Hvis data stiger med 10 gange, så vil transmissionstiden øges 10 gange. Ved at bruge stor O-notation udtrykkes kompleksiteten af vores algoritme som O(n). Du bør huske denne notation for fremtiden - den bruges altid til algoritmer med lineær kompleksitet. Bemærk, at vi ikke taler om flere ting, der kan variere her: Internethastighed, vores computers regnekraft og så videre. Når man vurderer kompleksiteten af en algoritme, giver det simpelthen ikke mening at overveje disse faktorer - under alle omstændigheder er de uden for vores kontrol. Big O-notation udtrykker kompleksiteten af selve algoritmen, ikke det "miljø", som den kører i. Lad os fortsætte med vores eksempel. Antag, at vi i sidste ende lærer, at vi skal sende filer på i alt 800 terabyte. Vi kan selvfølgelig løse vores opgave ved at sende dem over internettet. Der er kun et problem: ved standard husstandsdatatransmissionshastigheder (100 megabit pr. sekund) vil det tage cirka 708 dage. Næsten 2 år! :O Vores algoritme passer åbenbart ikke godt her. Vi har brug for en anden løsning! Uventet kommer IT-giganten Amazon os til undsætning! Amazons snescootertjeneste lader os uploade en stor mængde data til mobillager og derefter levere det til den ønskede adresse med lastbil!
I dette tilfælde er den mest effektive algoritme at sende filen over internettet. Det kunne ikke tage mere end et par minutter! Lad os gentage vores algoritme: "Hvis du ønsker at overføre information i form af filer over en afstand på 5000 miles, skal du sende dataene via internettet". Fremragende. Lad os nu analysere det. Løser det vores opgave?Nå, ja, det gør det. Men hvad kan vi sige om dens kompleksitet? Hmm, nu bliver tingene mere interessante. Faktum er, at vores algoritme er meget afhængig af inputdataene, nemlig størrelsen på filerne. Hvis vi har 10 megabyte, så er alt fint. Men hvad hvis vi skal sende 500 megabyte? 20 gigabyte? 500 terabyte? 30 petabyte? Holder vores algoritme op med at virke? Nej, alle disse mængder af data kan faktisk overføres. Vil det tage længere tid? Ja, det vil! Nu kender vi en vigtig funktion ved vores algoritme: Jo større mængde data der skal sendes, jo længere tid vil det tage at køre algoritmen. Men vi vil gerne have en mere præcis forståelse af dette forhold (mellem størrelsen på inputdata og den tid, det tager at sende det). I vores tilfælde er den algoritmiske kompleksitet lineær . "Lineær" betyder, at når mængden af inputdata stiger, vil den tid, det tager at sende dem, stige omtrent proportionalt. Hvis mængden af data fordobles, vil den tid, der kræves for at sende den, være dobbelt så meget. Hvis data stiger med 10 gange, så vil transmissionstiden øges 10 gange. Ved at bruge stor O-notation udtrykkes kompleksiteten af vores algoritme som O(n). Du bør huske denne notation for fremtiden - den bruges altid til algoritmer med lineær kompleksitet. Bemærk, at vi ikke taler om flere ting, der kan variere her: Internethastighed, vores computers regnekraft og så videre. Når man vurderer kompleksiteten af en algoritme, giver det simpelthen ikke mening at overveje disse faktorer - under alle omstændigheder er de uden for vores kontrol. Big O-notation udtrykker kompleksiteten af selve algoritmen, ikke det "miljø", som den kører i. Lad os fortsætte med vores eksempel. Antag, at vi i sidste ende lærer, at vi skal sende filer på i alt 800 terabyte. Vi kan selvfølgelig løse vores opgave ved at sende dem over internettet. Der er kun et problem: ved standard husstandsdatatransmissionshastigheder (100 megabit pr. sekund) vil det tage cirka 708 dage. Næsten 2 år! :O Vores algoritme passer åbenbart ikke godt her. Vi har brug for en anden løsning! Uventet kommer IT-giganten Amazon os til undsætning! Amazons snescootertjeneste lader os uploade en stor mængde data til mobillager og derefter levere det til den ønskede adresse med lastbil!  Så vi har en ny algoritme! "Hvis du ønsker at overføre information i form af filer over en afstand på 5000 miles, og det ville tage mere end 14 dage at sende det via internettet, bør du sende dataene på en Amazon-lastbil." Vi valgte 14 dage vilkårligt her. Lad os sige, at dette er den længste periode, vi kan vente. Lad os analysere vores algoritme. Hvad med dens hastighed? Selvom lastbilen kun kører med 50 mph, vil den tilbagelægge 5000 miles på kun 100 timer. Det er lidt over fire dage! Dette er meget bedre end muligheden for at sende dataene over internettet. Og hvad med kompleksiteten af denne algoritme? Er det også lineært, altså O(n)? Nej det er ikke. Når alt kommer til alt, er lastbilen ligeglad med, hvor tungt du læsser den – den vil stadig køre med nogenlunde samme hastighed og nå frem til tiden. Uanset om vi har 800 terabyte eller 10 gange det, når lastbilen stadig sin destination inden for 5 dage. Med andre ord har den lastbilbaserede dataoverførselsalgoritme konstant kompleksitet. Her betyder "konstant", at den ikke afhænger af inputdatastørrelsen. Sæt et 1GB flashdrev i lastbilen, det vil ankomme inden for 5 dage. Sæt i diske, der indeholder 800 terabyte data, vil de ankomme inden for 5 dage. Når du bruger stor O-notation, er konstant kompleksitet angivet med O(1) . Vi er blevet fortrolige med O(n) og O(1) , så lad os nu se på flere eksempler i programmeringsverdenen :) Antag at du får en matrix med 100 numre, og opgaven er at vise hver af dem på konsollen. Du skriver en almindelig
Så vi har en ny algoritme! "Hvis du ønsker at overføre information i form af filer over en afstand på 5000 miles, og det ville tage mere end 14 dage at sende det via internettet, bør du sende dataene på en Amazon-lastbil." Vi valgte 14 dage vilkårligt her. Lad os sige, at dette er den længste periode, vi kan vente. Lad os analysere vores algoritme. Hvad med dens hastighed? Selvom lastbilen kun kører med 50 mph, vil den tilbagelægge 5000 miles på kun 100 timer. Det er lidt over fire dage! Dette er meget bedre end muligheden for at sende dataene over internettet. Og hvad med kompleksiteten af denne algoritme? Er det også lineært, altså O(n)? Nej det er ikke. Når alt kommer til alt, er lastbilen ligeglad med, hvor tungt du læsser den – den vil stadig køre med nogenlunde samme hastighed og nå frem til tiden. Uanset om vi har 800 terabyte eller 10 gange det, når lastbilen stadig sin destination inden for 5 dage. Med andre ord har den lastbilbaserede dataoverførselsalgoritme konstant kompleksitet. Her betyder "konstant", at den ikke afhænger af inputdatastørrelsen. Sæt et 1GB flashdrev i lastbilen, det vil ankomme inden for 5 dage. Sæt i diske, der indeholder 800 terabyte data, vil de ankomme inden for 5 dage. Når du bruger stor O-notation, er konstant kompleksitet angivet med O(1) . Vi er blevet fortrolige med O(n) og O(1) , så lad os nu se på flere eksempler i programmeringsverdenen :) Antag at du får en matrix med 100 numre, og opgaven er at vise hver af dem på konsollen. Du skriver en almindelig 
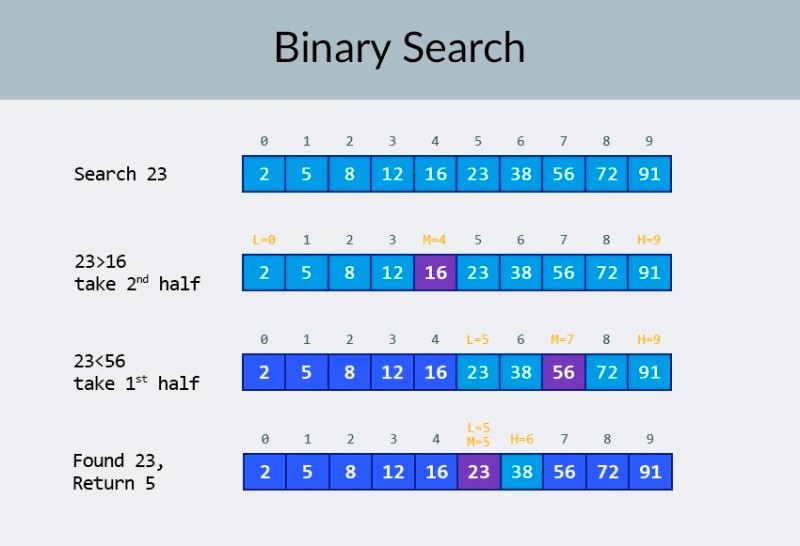 I den øverste række i billedet ser vi et sorteret array. Vi skal finde tallet 23 i den. I stedet for at iterere over tallene, deler vi simpelthen arrayet i 2 dele og tjekker det midterste tal i arrayet. Find det tal, der er placeret i celle 4, og tjek det (anden række i billedet). Dette tal er 16, og vi leder efter 23. Det nuværende antal er mindre end det, vi leder efter. Hvad betyder det? Det betyder atalle de tidligere numre (dem, der er placeret før tallet 16) behøver ikke at blive kontrolleret : de er garanteret mindre end det, vi leder efter, fordi vores array er sorteret! Vi fortsætter søgningen blandt de resterende 5 elementer. Bemærk:vi har kun foretaget én sammenligning, men vi har allerede elimineret halvdelen af de mulige muligheder. Vi har kun 5 elementer tilbage. Vi vil gentage vores forrige trin ved endnu en gang at dele det resterende underarray i to og igen tage det midterste element (den 3. række i billedet). Tallet er 56, og det er større end det, vi leder efter. Hvad betyder det? Det betyder, at vi har elimineret yderligere 3 muligheder: selve tallet 56 samt de to numre efter det (da de med garanti er større end 23, fordi arrayet er sorteret). Vi har kun 2 tal tilbage at kontrollere (den sidste række i billedet) — tallene med matrixindeks 5 og 6. Vi tjekker det første af dem, og finder det, vi ledte efter — tallet 23! Dens indeks er 5! Lad os se på resultaterne af vores algoritme, og så vil analysere dens kompleksitet. Forresten, nu forstår du, hvorfor dette kaldes binær søgning: den er afhængig af gentagne gange at dele dataene i to. Resultatet er imponerende! Hvis vi brugte en lineær søgning til at lede efter tallet, ville vi have brug for op til 10 sammenligninger, men med en binær søgning klarede vi opgaven med kun 3! I værste fald ville der være 4 sammenligninger (hvis det tal, vi ønskede i det sidste trin, var det andet af de resterende muligheder, snarere end det første. Så hvad med dets kompleksitet? Dette er et meget interessant punkt :) Den binære søgealgoritme er meget mindre afhængig af antallet af elementer i arrayet end den lineære søgealgoritme (det vil sige simpel iteration). Med 10 elementer i arrayet vil en lineær søgning maksimalt kræve 10 sammenligninger, men en binær søgning vil højst have brug for 4 sammenligninger. Det er en forskel på en faktor på 2,5. Men for en matrix på 1000 elementer vil en lineær søgning kræve op til 1000 sammenligninger, men en binær søgning ville kun kræve 10 ! Forskellen er nu 100 gange! Bemærk:antallet af elementer i arrayet er steget 100 gange (fra 10 til 1000), men antallet af sammenligninger, der kræves til en binær søgning, er kun steget med en faktor på 2,5 (fra 4 til 10). Hvis vi når til 10.000 elementer , vil forskellen være endnu mere imponerende: 10.000 sammenligninger til lineær søgning og i alt 14 sammenligninger til binær søgning. Og igen, hvis antallet af elementer stiger med 1000 gange (fra 10 til 10000), så stiger antallet af sammenligninger med en faktor på kun 3,5 (fra 4 til 14). Kompleksiteten af den binære søgealgoritme er logaritmisk , eller, hvis vi bruger stor O-notation, O(log n). Hvorfor hedder det det? Logaritmen er som det modsatte af eksponentiering. Den binære logaritme er den potens, som tallet 2 skal hæves til for at opnå et tal. For eksempel har vi 10.000 elementer, som vi skal søge ved hjælp af den binære søgealgoritme.
I den øverste række i billedet ser vi et sorteret array. Vi skal finde tallet 23 i den. I stedet for at iterere over tallene, deler vi simpelthen arrayet i 2 dele og tjekker det midterste tal i arrayet. Find det tal, der er placeret i celle 4, og tjek det (anden række i billedet). Dette tal er 16, og vi leder efter 23. Det nuværende antal er mindre end det, vi leder efter. Hvad betyder det? Det betyder atalle de tidligere numre (dem, der er placeret før tallet 16) behøver ikke at blive kontrolleret : de er garanteret mindre end det, vi leder efter, fordi vores array er sorteret! Vi fortsætter søgningen blandt de resterende 5 elementer. Bemærk:vi har kun foretaget én sammenligning, men vi har allerede elimineret halvdelen af de mulige muligheder. Vi har kun 5 elementer tilbage. Vi vil gentage vores forrige trin ved endnu en gang at dele det resterende underarray i to og igen tage det midterste element (den 3. række i billedet). Tallet er 56, og det er større end det, vi leder efter. Hvad betyder det? Det betyder, at vi har elimineret yderligere 3 muligheder: selve tallet 56 samt de to numre efter det (da de med garanti er større end 23, fordi arrayet er sorteret). Vi har kun 2 tal tilbage at kontrollere (den sidste række i billedet) — tallene med matrixindeks 5 og 6. Vi tjekker det første af dem, og finder det, vi ledte efter — tallet 23! Dens indeks er 5! Lad os se på resultaterne af vores algoritme, og så vil analysere dens kompleksitet. Forresten, nu forstår du, hvorfor dette kaldes binær søgning: den er afhængig af gentagne gange at dele dataene i to. Resultatet er imponerende! Hvis vi brugte en lineær søgning til at lede efter tallet, ville vi have brug for op til 10 sammenligninger, men med en binær søgning klarede vi opgaven med kun 3! I værste fald ville der være 4 sammenligninger (hvis det tal, vi ønskede i det sidste trin, var det andet af de resterende muligheder, snarere end det første. Så hvad med dets kompleksitet? Dette er et meget interessant punkt :) Den binære søgealgoritme er meget mindre afhængig af antallet af elementer i arrayet end den lineære søgealgoritme (det vil sige simpel iteration). Med 10 elementer i arrayet vil en lineær søgning maksimalt kræve 10 sammenligninger, men en binær søgning vil højst have brug for 4 sammenligninger. Det er en forskel på en faktor på 2,5. Men for en matrix på 1000 elementer vil en lineær søgning kræve op til 1000 sammenligninger, men en binær søgning ville kun kræve 10 ! Forskellen er nu 100 gange! Bemærk:antallet af elementer i arrayet er steget 100 gange (fra 10 til 1000), men antallet af sammenligninger, der kræves til en binær søgning, er kun steget med en faktor på 2,5 (fra 4 til 10). Hvis vi når til 10.000 elementer , vil forskellen være endnu mere imponerende: 10.000 sammenligninger til lineær søgning og i alt 14 sammenligninger til binær søgning. Og igen, hvis antallet af elementer stiger med 1000 gange (fra 10 til 10000), så stiger antallet af sammenligninger med en faktor på kun 3,5 (fra 4 til 14). Kompleksiteten af den binære søgealgoritme er logaritmisk , eller, hvis vi bruger stor O-notation, O(log n). Hvorfor hedder det det? Logaritmen er som det modsatte af eksponentiering. Den binære logaritme er den potens, som tallet 2 skal hæves til for at opnå et tal. For eksempel har vi 10.000 elementer, som vi skal søge ved hjælp af den binære søgealgoritme. 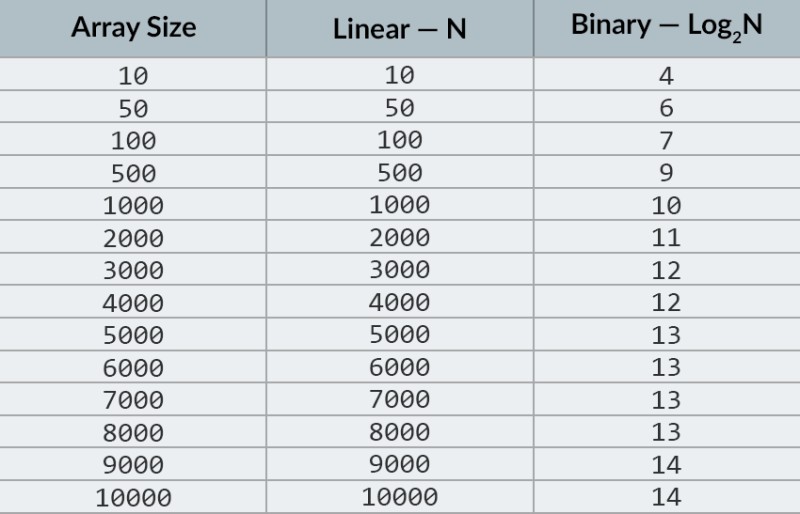 I øjeblikket kan du se på værditabellen for at vide, at dette vil kræve maksimalt 14 sammenligninger. Men hvad hvis ingen har leveret sådan en tabel, og du skal beregne det nøjagtige maksimale antal sammenligninger? Du skal bare svare på et simpelt spørgsmål: til hvilken styrke skal du hæve tallet 2, så resultatet er større end eller lig med antallet af elementer, der skal kontrolleres? For 10.000 er det 14. potens. 2 til 13. potens er for lille (8192), men 2 til 14. potens = 16384, og dette tal opfylder vores betingelse (det er større end eller lig med antallet af elementer i arrayet). Vi fandt logaritmen: 14. Så mange sammenligninger kan vi have brug for! :) Algoritmer og algoritmisk kompleksitet er et for bredt emne til at passe ind i én lektion. Men at vide det er meget vigtigt: Mange jobsamtaler vil involvere spørgsmål, der involverer algoritmer. I teorien kan jeg anbefale nogle bøger til dig. Du kan starte med " Grokking Algorithms ". Eksemplerne i denne bog er skrevet i Python, men bogen bruger meget simpelt sprog og eksempler. Det er den bedste mulighed for en begynder, og hvad mere er, den er ikke særlig stor. Blandt mere seriøs læsning har vi bøger af Robert Lafore og Robert Sedgewick. Begge er skrevet i Java, hvilket vil gøre indlæringen lidt nemmere for dig. Når alt kommer til alt, er du ganske fortrolig med dette sprog! :) For elever med gode matematiske færdigheder er den bedste mulighed Thomas Cormens bog . Men teori alene vil ikke fylde din mave! Viden != Evne . Du kan øve dig i at løse problemer, der involverer algoritmer, på HackerRank og LeetCode . Opgaver fra disse hjemmesider bliver ofte brugt selv under interviews hos Google og Facebook, så du kommer bestemt ikke til at kede dig :) For at forstærke dette lektionsmateriale anbefaler jeg, at du ser denne fremragende video om big O notation på YouTube. Vi ses i de næste lektioner! :)
I øjeblikket kan du se på værditabellen for at vide, at dette vil kræve maksimalt 14 sammenligninger. Men hvad hvis ingen har leveret sådan en tabel, og du skal beregne det nøjagtige maksimale antal sammenligninger? Du skal bare svare på et simpelt spørgsmål: til hvilken styrke skal du hæve tallet 2, så resultatet er større end eller lig med antallet af elementer, der skal kontrolleres? For 10.000 er det 14. potens. 2 til 13. potens er for lille (8192), men 2 til 14. potens = 16384, og dette tal opfylder vores betingelse (det er større end eller lig med antallet af elementer i arrayet). Vi fandt logaritmen: 14. Så mange sammenligninger kan vi have brug for! :) Algoritmer og algoritmisk kompleksitet er et for bredt emne til at passe ind i én lektion. Men at vide det er meget vigtigt: Mange jobsamtaler vil involvere spørgsmål, der involverer algoritmer. I teorien kan jeg anbefale nogle bøger til dig. Du kan starte med " Grokking Algorithms ". Eksemplerne i denne bog er skrevet i Python, men bogen bruger meget simpelt sprog og eksempler. Det er den bedste mulighed for en begynder, og hvad mere er, den er ikke særlig stor. Blandt mere seriøs læsning har vi bøger af Robert Lafore og Robert Sedgewick. Begge er skrevet i Java, hvilket vil gøre indlæringen lidt nemmere for dig. Når alt kommer til alt, er du ganske fortrolig med dette sprog! :) For elever med gode matematiske færdigheder er den bedste mulighed Thomas Cormens bog . Men teori alene vil ikke fylde din mave! Viden != Evne . Du kan øve dig i at løse problemer, der involverer algoritmer, på HackerRank og LeetCode . Opgaver fra disse hjemmesider bliver ofte brugt selv under interviews hos Google og Facebook, så du kommer bestemt ikke til at kede dig :) For at forstærke dette lektionsmateriale anbefaler jeg, at du ser denne fremragende video om big O notation på YouTube. Vi ses i de næste lektioner! :)

GO TO FULL VERSION