안녕! 오늘의 수업은 나머지 수업과 약간 다를 것입니다. Java와 간접적으로만 관련되어 있다는 점에서 다를 것입니다. 즉, 이 주제는 모든 프로그래머에게 매우 중요합니다. 우리는 알고리즘 에 대해 이야기할 것입니다 . 알고리즘이란 무엇입니까? 간단히 말해서 원하는 결과를 얻기 위해 완료해야 하는 일련의 작업입니다 . 우리는 일상생활에서 알고리즘을 자주 사용합니다. 예를 들어, 매일 아침 특정 작업이 있습니다. 학교에 가거나 직장에 가면서 동시에 다음과 같이 됩니다.
옷을 입은
깨끗한
연준
이 결과를 얻을 수 있는 알고리즘은 무엇 입니까?
알람 시계를 사용하여 일어나십시오.
샤워를 하고 몸을 씻으세요.
아침 식사와 커피 또는 차를 만드십시오.
먹다.
전날 저녁에 옷을 다림질하지 않았다면 다림질하십시오.
옷을 입다.
집을 떠나다.
이 일련의 작업을 통해 원하는 결과를 확실히 얻을 수 있습니다. 프로그래밍에서 우리는 작업을 완료하기 위해 끊임없이 노력하고 있습니다. 이러한 작업의 상당 부분은 이미 알려진 알고리즘을 사용하여 수행할 수 있습니다. 예를 들어 작업이 다음과 같다고 가정합니다. 배열에서 100개의 이름 목록을 정렬합니다 . 이 작업은 매우 간단하지만 다른 방법으로 해결할 수 있습니다. 가능한 해결책은 다음과 같습니다. 이름을 사전순으로 정렬하는 알고리즘:
Webster's Third New International Dictionary의 1961년판을 구입하거나 다운로드하십시오.
이 사전의 목록에서 모든 이름을 찾으십시오.
종이에 이름이 있는 사전 페이지를 적습니다.
종이 조각을 사용하여 이름을 정렬합니다.
이러한 일련의 행동이 우리의 임무를 완수할까요? 예, 확실히 그럴 것입니다. 이 솔루션은 효율적 입니까 ? 거의 ~ 아니다. 여기서 우리는 알고리즘의 또 다른 매우 중요한 측면인 효율성 에 도달합니다 . 이 작업을 수행하는 방법에는 여러 가지가 있습니다. 그러나 프로그래밍과 일상생활에서 우리는 가장 효율적인 방법을 선택하기를 원합니다. 당신의 임무가 버터 바른 토스트 조각을 만드는 것이라면 밀을 뿌리고 젖소의 젖을 짜는 것부터 시작할 수 있습니다. 그러나 그것은 비효율적 일 것입니다솔루션 — 많은 시간과 비용이 소요됩니다. 빵과 버터를 사면 간단한 작업을 수행할 수 있습니다. 문제를 해결할 수는 있지만 밀과 소가 관련된 알고리즘은 실제로 사용하기에는 너무 복잡합니다. 프로그래밍에서 알고리즘의 복잡성을 평가하기 위해 Big O 표기법 이라는 특별한 표기법이 있습니다 . Big O를 사용하면 알고리즘의 실행 시간이 입력 데이터 크기에 얼마나 의존하는지 평가할 수 있습니다 . 가장 간단한 예인 데이터 전송을 살펴보겠습니다. 장거리(예: 5000마일)에 걸쳐 파일 형식으로 일부 정보를 보내야 한다고 상상해 보십시오. 가장 효율적인 알고리즘은 무엇입니까? 작업 중인 데이터에 따라 다릅니다. 예를 들어 10MB의 오디오 파일이 있다고 가정합니다. 이 경우 가장 효율적인 알고리즘은 인터넷을 통해 파일을 보내는 것입니다. 그것은 몇 분 이상 걸릴 수 없습니다! 우리의 알고리즘을 다시 말해봅시다. "5000마일의 거리에 걸쳐 파일 형태로 정보를 전송하려면 인터넷을 통해 데이터를 전송해야 합니다." 훌륭한. 이제 분석해 봅시다. 우리의 임무를 완수합니까?네, 그렇습니다. 그러나 그 복잡성에 대해 무엇을 말할 수 있습니까? 흠, 이제 상황이 점점 더 흥미로워지고 있습니다. 사실 우리 알고리즘은 입력 데이터, 즉 파일 크기에 크게 의존합니다. 10MB가 있으면 모든 것이 정상입니다. 하지만 500MB를 보내야 한다면 어떻게 해야 할까요? 20기가바이트? 500테라바이트? 30페타바이트? 알고리즘이 작동을 멈출까요? 아니요, 이 모든 양의 데이터는 실제로 전송할 수 있습니다. 더 오래 걸릴까요? 예, 그럴 것입니다! 이제 우리는 알고리즘의 중요한 기능을 알고 있습니다. 보낼 데이터의 양이 많을수록 알고리즘을 실행하는 데 더 오래 걸립니다.. 그러나 우리는 이 관계(입력 데이터 크기와 전송에 필요한 시간 사이)를 보다 정확하게 이해하고 싶습니다. 우리의 경우 알고리즘 복잡성은 선형 입니다 . "선형"은 입력 데이터의 양이 증가함에 따라 전송하는 데 걸리는 시간이 대략 비례하여 증가함을 의미합니다. 데이터 양이 2배가 되면 전송에 걸리는 시간도 2배가 됩니다. 데이터가 10배 증가하면 전송 시간은 10배 증가합니다. Big O 표기법을 사용하여 알고리즘의 복잡성은 O(n) 으로 표현됩니다.. 미래를 위해 이 표기법을 기억해야 합니다. 선형 복잡성이 있는 알고리즘에 항상 사용됩니다. 여기서는 인터넷 속도, 컴퓨터의 계산 능력 등 다양할 수 있는 몇 가지 사항에 대해 말하는 것이 아닙니다. 알고리즘의 복잡성을 평가할 때 이러한 요소를 고려하는 것은 이치에 맞지 않습니다. 어쨌든 이러한 요소는 우리의 통제 범위 밖에 있습니다. Big O 표기법은 알고리즘이 실행되는 "환경"이 아니라 알고리즘 자체의 복잡성을 나타냅니다. 우리의 예를 계속합시다. 최종적으로 총 800테라바이트의 파일을 보내야 한다는 사실을 알게 되었다고 가정해 보겠습니다. 물론 우리는 인터넷을 통해 그것들을 보냄으로써 우리의 임무를 완수할 수 있습니다. 한 가지 문제가 있습니다. 표준 가정용 데이터 전송 속도(초당 100메가비트)에서 약 708일이 소요됩니다. 거의 2년! :O 우리의 알고리즘은 분명히 여기에 적합하지 않습니다. 우리는 다른 해결책이 필요합니다! 예기치 않게 IT 거대 Amazon이 우리를 구출합니다! Amazon의 Snowmobile 서비스를 사용하면 대량의 데이터를 모바일 스토리지에 업로드한 다음 트럭으로 원하는 주소로 배달할 수 있습니다! 그래서 우리는 새로운 알고리즘을 가지고 있습니다! "파일 형태의 정보를 5000마일 이상 전송하고 인터넷을 통해 전송하는 데 14일 이상이 걸리는 경우 Amazon 트럭에 데이터를 전송해야 합니다." 여기서 임의로 14일을 선택했습니다. 이것이 우리가 기다릴 수 있는 가장 긴 기간이라고 가정해 봅시다. 알고리즘을 분석해 봅시다. 속도는 어떻습니까? 트럭이 시속 50마일로 이동하더라도 단 100시간 만에 5000마일을 주행할 수 있습니다. 4일이 조금 넘었습니다! 이것은 인터넷을 통해 데이터를 보내는 옵션보다 훨씬 낫습니다. 그리고 이 알고리즘의 복잡성은 어떻습니까? 또한 선형입니까, 즉 O(n)입니까? 전혀 그렇지 않다. 결국, 트럭은 당신이 얼마나 많은 짐을 싣는지 상관하지 않습니다. 트럭은 여전히 거의 같은 속도로 운전하고 제시간에 도착할 것입니다. 800테라바이트가 있든 10배가 있든 트럭은 여전히 5일 이내에 목적지에 도착합니다. 즉, 트럭 기반 데이터 전송 알고리즘은 지속적으로 복잡 합니다.. 여기서 "상수"란 입력 데이터 크기에 의존하지 않는 것을 의미합니다. 1GB 플래시 드라이브를 트럭에 넣으면 5일 이내에 도착합니다. 800테라바이트의 데이터가 들어 있는 디스크를 넣으면 5일 이내에 도착합니다. Big O 표기법을 사용할 때 상수 복잡도는 O(1) 로 표시됩니다 . 우리는 O(n) 및 O(1) 에 익숙해졌으므로 이제 프로그래밍 세계에서 더 많은 예를 살펴보겠습니다 :) 100개의 숫자 배열이 주어졌고 작업이 각 숫자를 콘솔. for이 작업을 수행하는 일반 루프를 작성합니다.
int[] numbers = new int[100];
// ...fill the array with numbers
for (int i: numbers) {
System.out.println(i);
}
이 알고리즘의 복잡성은 무엇입니까? 선형, 즉 O(n). 프로그램이 수행해야 하는 작업의 수는 전달되는 숫자의 수에 따라 다릅니다. 배열에 100개의 숫자가 있으면 100개의 동작(화면에 문자열을 표시하는 명령문)이 있습니다. 배열에 10,000개의 숫자가 있으면 10,000개의 작업을 수행해야 합니다. 어떤 방식으로든 알고리즘을 개선할 수 있습니까? 아니요. 무슨 일이 있어도 배열을 N 번 통과 하고 N 문을 실행하여 콘솔에 문자열을 표시 해야 합니다 . 다른 예를 고려하십시오.
public static void main(String[] args) {
LinkedList<Integer> numbers = new LinkedList<>();
numbers.add(0, 20202);
numbers.add(0, 123);
numbers.add(0, 8283);
}
LinkedList여러 숫자를 삽입하는 빈 공간이 있습니다 . LinkedList예제에서 하나의 숫자를 에 삽입하는 알고리즘 복잡성과 목록의 요소 수에 따라 달라지는 방식을 평가해야 합니다 . 대답은 O(1), 즉 상수 복잡성 입니다 . 왜? 목록의 시작 부분에 각 번호를 삽입합니다. 또한 에 숫자를 삽입할 때 LinkedList요소가 아무데도 이동하지 않는다는 것을 기억할 것입니다. 링크(또는 참조)가 업데이트됩니다(LinkedList 작동 방식을 잊은 경우 이전 강의 중 하나를 참조하십시오 ). 목록의 첫 번째 숫자가 이고 x목록 앞에 숫자 y를 삽입하면 다음과 같이 하면 됩니다.
x.previous = y;
y.previous = null;
y.next = x;
링크를 업데이트할 때 10억이든 10억이든 이미 얼마나 많은 숫자가 있는지는 신경 쓰지 않습니다 . LinkedList알고리즘의 복잡성은 일정합니다. 즉, O(1)입니다.
대수 복잡도
당황하지 말 것! :) "로그"라는 단어 때문에 이 수업을 끝내고 읽기를 중단하고 싶다면 몇 분만 기다리십시오. 여기에는 미친 수학이 없을 것이며(다른 곳에서 이와 같은 설명이 많이 있습니다) 각 예를 따로 선택할 것입니다. 100개의 숫자 배열에서 하나의 특정 숫자를 찾는 것이 작업이라고 상상해 보십시오. 더 정확하게는 그것이 있는지 여부를 확인해야합니다. 필요한 번호를 찾자마자 검색이 종료되고 콘솔에 다음과 같이 표시됩니다. 여기서 해결책은 분명합니다. 처음부터(또는 마지막부터) 시작하여 배열의 요소를 하나씩 반복하고 현재 숫자가 찾고 있는 것과 일치하는지 확인해야 합니다. 따라서, 작업 수는 배열의 요소 수에 직접적으로 의존합니다. 100개의 숫자가 있는 경우 잠재적으로 다음 요소로 100번 이동하고 100번의 비교를 수행해야 할 수 있습니다. 1000개의 숫자가 있으면 1000개의 비교가 있을 수 있습니다. 이것은 분명히 선형 복잡성입니다.오(n) . 이제 우리는 우리의 예에 한 가지 개선 사항을 추가할 것입니다. 숫자를 찾아야 하는 배열이 오름차순으로 정렬됩니다 . 이것이 우리의 작업과 관련하여 변경되는 사항이 있습니까? 우리는 여전히 원하는 번호에 대해 무차별 대입 검색을 수행할 수 있습니다. 그러나 대안으로 잘 알려진 이진 검색 알고리즘을 사용할 수 있습니다 . 이미지의 맨 위 행에는 정렬된 배열이 표시됩니다. 그 안에서 숫자 23을 찾아야 합니다. 숫자를 반복하는 대신 배열을 두 부분으로 나누고 배열의 중간 숫자를 확인합니다. 셀 4에 있는 숫자를 찾아 확인합니다(이미지의 두 번째 행). 이 숫자는 16이고 우리는 23을 찾고 있습니다. 현재 숫자는 우리가 찾고 있는 것보다 적습니다. 그게 무슨 뜻이야? 그것은 의미합니다이전의 모든 숫자(숫자 16 앞에 있는 숫자)는 확인할 필요가 없습니다 . 배열이 정렬되어 있기 때문에 찾고 있는 숫자보다 작다는 것이 보장됩니다! 나머지 5개 요소 중에서 검색을 계속합니다. 메모:한 번의 비교만 수행했지만 이미 가능한 옵션의 절반을 제거했습니다. 5개의 요소만 남았습니다. 나머지 하위 배열을 다시 한 번 반으로 나누고 중간 요소(이미지의 세 번째 행)를 다시 취함으로써 이전 단계를 반복합니다. 숫자는 56이고 우리가 찾고 있는 것보다 큽니다. 그게 무슨 뜻이야? 그것은 우리가 다른 3개의 가능성을 제거했음을 의미합니다: 숫자 56 자체와 그 뒤의 두 숫자(배열이 정렬되기 때문에 23보다 큰 것이 보장되기 때문입니다). 확인할 수 있는 숫자는 2개(이미지의 마지막 행)뿐입니다. 배열 인덱스가 5와 6인 숫자입니다. 그 중 첫 번째 숫자를 확인하고 찾고 있던 숫자 23을 찾습니다! 지수는 5입니다! 알고리즘의 결과를 살펴보고 ' 복잡성을 분석하겠습니다. 그건 그렇고, 이제 이것이 왜 이진 검색이라고 불리는지 이해하실 것입니다. 이것은 반복적으로 데이터를 반으로 나누는 것에 의존합니다. 결과는 인상적입니다! 숫자를 찾기 위해 선형 검색을 사용했다면 최대 10번의 비교가 필요했지만 이진 검색을 사용하면 3번으로 작업을 완료했습니다! 최악의 경우, 4번의 비교가 있을 것입니다(마지막 단계에서 우리가 원하는 숫자가 첫 번째가 아니라 나머지 가능성 중 두 번째인 경우. 그렇다면 복잡성은 어떻습니까? 이것은 매우 흥미로운 점입니다 :) 이진 검색 알고리즘은 선형 검색 알고리즘(즉, 단순 반복)보다 배열의 요소 수에 훨씬 덜 의존합니다. 배열에 10개의 요소가 있는 경우 선형 검색에는 최대 10개의 비교가 필요하지만 이진 검색에는 최대 4개의 비교가 필요합니다. 2.5배 정도 차이가 납니다. 그러나 1000개 요소 배열의 경우 선형 검색에는 최대 1000개의 비교가 필요하지만 이진 검색에는 10개만 필요합니다 ! 그 차이는 이제 100배입니다! 메모:배열의 요소 수는 100배(10에서 1000으로) 증가했지만 이진 검색에 필요한 비교 수는 2.5배(4에서 10으로) 증가했습니다. 10,000개의 요소 에 도달하면 그 차이는 훨씬 더 커질 것입니다. 선형 검색의 경우 10,000개의 비교, 이진 검색의 경우 총 14개의 비교입니다 . 그리고 다시 요소 수가 1000배 증가하면(10에서 10000으로) 비교 횟수는 3.5배(4에서 14로)만 증가합니다. 이진 검색 알고리즘의 복잡도는 대수적 이거나, 빅오 표기법을 사용하는 경우 O(log n). 왜 그렇게 부릅니까? 로그는 지수의 반대와 같습니다. 이진 로그는 숫자를 얻기 위해 숫자 2를 올려야 하는 거듭제곱입니다. 예를 들어 이진 검색 알고리즘을 사용하여 검색해야 하는 10,000개의 요소가 있습니다. 현재 이 작업을 수행하려면 최대 14번의 비교가 필요하다는 것을 알기 위해 값 테이블을 볼 수 있습니다. 그러나 아무도 이러한 테이블을 제공하지 않았고 정확한 최대 비교 수를 계산해야 하는 경우에는 어떻게 해야 합니까? 간단한 질문에 답하기만 하면 됩니다. 결과가 검사할 요소의 수보다 크거나 같도록 숫자 2를 어떤 힘으로 올려야 합니까? 10,000의 경우 14제곱입니다. 2의 13승은 너무 작은데(8192), 2의 14승 = 16384, 이 숫자는 조건을 충족합니다(배열의 요소 수보다 크거나 같음). 우리는 로그를 찾았습니다: 14. 그것이 우리가 필요한 비교의 수입니다! :) 알고리즘과 알고리즘의 복잡성은 한 강의에 맞추기에는 너무 광범위한 주제입니다. 그러나 그것을 아는 것이 매우 중요합니다. 많은 취업 면접에는 알고리즘과 관련된 질문이 포함될 것입니다. 이론적으로 몇 권의 책을 추천해 드릴 수 있습니다. " Grokking Algorithms " 로 시작할 수 있습니다 . 이 책의 예제는 Python으로 작성되었지만 이 책에서는 매우 간단한 언어와 예제를 사용합니다. 초보자에게 가장 좋은 옵션이며 더군다나 그다지 크지 않습니다. 더 진지한 독서 중에는 Robert Lafore 와 Robert Sedgewick 의 책이 있습니다.. 둘 다 Java로 작성되었으므로 학습이 조금 더 쉬워집니다. 결국, 당신은 이 언어에 꽤 익숙합니다! :) 수학 실력이 좋은 학생들에게 가장 좋은 선택은 Thomas Cormen의 책 입니다 . 그러나 이론만으로는 배를 채울 수 없습니다! 지식 != 능력 . HackerRank 및 LeetCode 에서 알고리즘과 관련된 문제 해결을 연습할 수 있습니다 . 이러한 웹사이트의 작업은 Google 및 Facebook의 인터뷰 중에도 자주 사용되므로 절대 지루하지 않을 것입니다 :) 이 수업 자료를 보강하려면 YouTube에서 빅오 표기법에 대한 훌륭한 비디오를 시청하는 것이 좋습니다. 다음 수업에서 만나요! :)
 즉, 이 주제는 모든 프로그래머에게 매우 중요합니다. 우리는 알고리즘 에 대해 이야기할 것입니다 . 알고리즘이란 무엇입니까? 간단히 말해서 원하는 결과를 얻기 위해 완료해야 하는 일련의 작업입니다 . 우리는 일상생활에서 알고리즘을 자주 사용합니다. 예를 들어, 매일 아침 특정 작업이 있습니다. 학교에 가거나 직장에 가면서 동시에 다음과 같이 됩니다.
즉, 이 주제는 모든 프로그래머에게 매우 중요합니다. 우리는 알고리즘 에 대해 이야기할 것입니다 . 알고리즘이란 무엇입니까? 간단히 말해서 원하는 결과를 얻기 위해 완료해야 하는 일련의 작업입니다 . 우리는 일상생활에서 알고리즘을 자주 사용합니다. 예를 들어, 매일 아침 특정 작업이 있습니다. 학교에 가거나 직장에 가면서 동시에 다음과 같이 됩니다.
 이 경우 가장 효율적인 알고리즘은 인터넷을 통해 파일을 보내는 것입니다. 그것은 몇 분 이상 걸릴 수 없습니다! 우리의 알고리즘을 다시 말해봅시다. "5000마일의 거리에 걸쳐 파일 형태로 정보를 전송하려면 인터넷을 통해 데이터를 전송해야 합니다." 훌륭한. 이제 분석해 봅시다. 우리의 임무를 완수합니까?네, 그렇습니다. 그러나 그 복잡성에 대해 무엇을 말할 수 있습니까? 흠, 이제 상황이 점점 더 흥미로워지고 있습니다. 사실 우리 알고리즘은 입력 데이터, 즉 파일 크기에 크게 의존합니다. 10MB가 있으면 모든 것이 정상입니다. 하지만 500MB를 보내야 한다면 어떻게 해야 할까요? 20기가바이트? 500테라바이트? 30페타바이트? 알고리즘이 작동을 멈출까요? 아니요, 이 모든 양의 데이터는 실제로 전송할 수 있습니다. 더 오래 걸릴까요? 예, 그럴 것입니다! 이제 우리는 알고리즘의 중요한 기능을 알고 있습니다. 보낼 데이터의 양이 많을수록 알고리즘을 실행하는 데 더 오래 걸립니다.. 그러나 우리는 이 관계(입력 데이터 크기와 전송에 필요한 시간 사이)를 보다 정확하게 이해하고 싶습니다. 우리의 경우 알고리즘 복잡성은 선형 입니다 . "선형"은 입력 데이터의 양이 증가함에 따라 전송하는 데 걸리는 시간이 대략 비례하여 증가함을 의미합니다. 데이터 양이 2배가 되면 전송에 걸리는 시간도 2배가 됩니다. 데이터가 10배 증가하면 전송 시간은 10배 증가합니다. Big O 표기법을 사용하여 알고리즘의 복잡성은 O(n) 으로 표현됩니다.. 미래를 위해 이 표기법을 기억해야 합니다. 선형 복잡성이 있는 알고리즘에 항상 사용됩니다. 여기서는 인터넷 속도, 컴퓨터의 계산 능력 등 다양할 수 있는 몇 가지 사항에 대해 말하는 것이 아닙니다. 알고리즘의 복잡성을 평가할 때 이러한 요소를 고려하는 것은 이치에 맞지 않습니다. 어쨌든 이러한 요소는 우리의 통제 범위 밖에 있습니다. Big O 표기법은 알고리즘이 실행되는 "환경"이 아니라 알고리즘 자체의 복잡성을 나타냅니다. 우리의 예를 계속합시다. 최종적으로 총 800테라바이트의 파일을 보내야 한다는 사실을 알게 되었다고 가정해 보겠습니다. 물론 우리는 인터넷을 통해 그것들을 보냄으로써 우리의 임무를 완수할 수 있습니다. 한 가지 문제가 있습니다. 표준 가정용 데이터 전송 속도(초당 100메가비트)에서 약 708일이 소요됩니다. 거의 2년! :O 우리의 알고리즘은 분명히 여기에 적합하지 않습니다. 우리는 다른 해결책이 필요합니다! 예기치 않게 IT 거대 Amazon이 우리를 구출합니다! Amazon의 Snowmobile 서비스를 사용하면 대량의 데이터를 모바일 스토리지에 업로드한 다음 트럭으로 원하는 주소로 배달할 수 있습니다!
이 경우 가장 효율적인 알고리즘은 인터넷을 통해 파일을 보내는 것입니다. 그것은 몇 분 이상 걸릴 수 없습니다! 우리의 알고리즘을 다시 말해봅시다. "5000마일의 거리에 걸쳐 파일 형태로 정보를 전송하려면 인터넷을 통해 데이터를 전송해야 합니다." 훌륭한. 이제 분석해 봅시다. 우리의 임무를 완수합니까?네, 그렇습니다. 그러나 그 복잡성에 대해 무엇을 말할 수 있습니까? 흠, 이제 상황이 점점 더 흥미로워지고 있습니다. 사실 우리 알고리즘은 입력 데이터, 즉 파일 크기에 크게 의존합니다. 10MB가 있으면 모든 것이 정상입니다. 하지만 500MB를 보내야 한다면 어떻게 해야 할까요? 20기가바이트? 500테라바이트? 30페타바이트? 알고리즘이 작동을 멈출까요? 아니요, 이 모든 양의 데이터는 실제로 전송할 수 있습니다. 더 오래 걸릴까요? 예, 그럴 것입니다! 이제 우리는 알고리즘의 중요한 기능을 알고 있습니다. 보낼 데이터의 양이 많을수록 알고리즘을 실행하는 데 더 오래 걸립니다.. 그러나 우리는 이 관계(입력 데이터 크기와 전송에 필요한 시간 사이)를 보다 정확하게 이해하고 싶습니다. 우리의 경우 알고리즘 복잡성은 선형 입니다 . "선형"은 입력 데이터의 양이 증가함에 따라 전송하는 데 걸리는 시간이 대략 비례하여 증가함을 의미합니다. 데이터 양이 2배가 되면 전송에 걸리는 시간도 2배가 됩니다. 데이터가 10배 증가하면 전송 시간은 10배 증가합니다. Big O 표기법을 사용하여 알고리즘의 복잡성은 O(n) 으로 표현됩니다.. 미래를 위해 이 표기법을 기억해야 합니다. 선형 복잡성이 있는 알고리즘에 항상 사용됩니다. 여기서는 인터넷 속도, 컴퓨터의 계산 능력 등 다양할 수 있는 몇 가지 사항에 대해 말하는 것이 아닙니다. 알고리즘의 복잡성을 평가할 때 이러한 요소를 고려하는 것은 이치에 맞지 않습니다. 어쨌든 이러한 요소는 우리의 통제 범위 밖에 있습니다. Big O 표기법은 알고리즘이 실행되는 "환경"이 아니라 알고리즘 자체의 복잡성을 나타냅니다. 우리의 예를 계속합시다. 최종적으로 총 800테라바이트의 파일을 보내야 한다는 사실을 알게 되었다고 가정해 보겠습니다. 물론 우리는 인터넷을 통해 그것들을 보냄으로써 우리의 임무를 완수할 수 있습니다. 한 가지 문제가 있습니다. 표준 가정용 데이터 전송 속도(초당 100메가비트)에서 약 708일이 소요됩니다. 거의 2년! :O 우리의 알고리즘은 분명히 여기에 적합하지 않습니다. 우리는 다른 해결책이 필요합니다! 예기치 않게 IT 거대 Amazon이 우리를 구출합니다! Amazon의 Snowmobile 서비스를 사용하면 대량의 데이터를 모바일 스토리지에 업로드한 다음 트럭으로 원하는 주소로 배달할 수 있습니다!  그래서 우리는 새로운 알고리즘을 가지고 있습니다! "파일 형태의 정보를 5000마일 이상 전송하고 인터넷을 통해 전송하는 데 14일 이상이 걸리는 경우 Amazon 트럭에 데이터를 전송해야 합니다." 여기서 임의로 14일을 선택했습니다. 이것이 우리가 기다릴 수 있는 가장 긴 기간이라고 가정해 봅시다. 알고리즘을 분석해 봅시다. 속도는 어떻습니까? 트럭이 시속 50마일로 이동하더라도 단 100시간 만에 5000마일을 주행할 수 있습니다. 4일이 조금 넘었습니다! 이것은 인터넷을 통해 데이터를 보내는 옵션보다 훨씬 낫습니다. 그리고 이 알고리즘의 복잡성은 어떻습니까? 또한 선형입니까, 즉 O(n)입니까? 전혀 그렇지 않다. 결국, 트럭은 당신이 얼마나 많은 짐을 싣는지 상관하지 않습니다. 트럭은 여전히 거의 같은 속도로 운전하고 제시간에 도착할 것입니다. 800테라바이트가 있든 10배가 있든 트럭은 여전히 5일 이내에 목적지에 도착합니다. 즉, 트럭 기반 데이터 전송 알고리즘은 지속적으로 복잡 합니다.. 여기서 "상수"란 입력 데이터 크기에 의존하지 않는 것을 의미합니다. 1GB 플래시 드라이브를 트럭에 넣으면 5일 이내에 도착합니다. 800테라바이트의 데이터가 들어 있는 디스크를 넣으면 5일 이내에 도착합니다. Big O 표기법을 사용할 때 상수 복잡도는 O(1) 로 표시됩니다 . 우리는 O(n) 및 O(1) 에 익숙해졌으므로 이제 프로그래밍 세계에서 더 많은 예를 살펴보겠습니다 :) 100개의 숫자 배열이 주어졌고 작업이 각 숫자를 콘솔.
그래서 우리는 새로운 알고리즘을 가지고 있습니다! "파일 형태의 정보를 5000마일 이상 전송하고 인터넷을 통해 전송하는 데 14일 이상이 걸리는 경우 Amazon 트럭에 데이터를 전송해야 합니다." 여기서 임의로 14일을 선택했습니다. 이것이 우리가 기다릴 수 있는 가장 긴 기간이라고 가정해 봅시다. 알고리즘을 분석해 봅시다. 속도는 어떻습니까? 트럭이 시속 50마일로 이동하더라도 단 100시간 만에 5000마일을 주행할 수 있습니다. 4일이 조금 넘었습니다! 이것은 인터넷을 통해 데이터를 보내는 옵션보다 훨씬 낫습니다. 그리고 이 알고리즘의 복잡성은 어떻습니까? 또한 선형입니까, 즉 O(n)입니까? 전혀 그렇지 않다. 결국, 트럭은 당신이 얼마나 많은 짐을 싣는지 상관하지 않습니다. 트럭은 여전히 거의 같은 속도로 운전하고 제시간에 도착할 것입니다. 800테라바이트가 있든 10배가 있든 트럭은 여전히 5일 이내에 목적지에 도착합니다. 즉, 트럭 기반 데이터 전송 알고리즘은 지속적으로 복잡 합니다.. 여기서 "상수"란 입력 데이터 크기에 의존하지 않는 것을 의미합니다. 1GB 플래시 드라이브를 트럭에 넣으면 5일 이내에 도착합니다. 800테라바이트의 데이터가 들어 있는 디스크를 넣으면 5일 이내에 도착합니다. Big O 표기법을 사용할 때 상수 복잡도는 O(1) 로 표시됩니다 . 우리는 O(n) 및 O(1) 에 익숙해졌으므로 이제 프로그래밍 세계에서 더 많은 예를 살펴보겠습니다 :) 100개의 숫자 배열이 주어졌고 작업이 각 숫자를 콘솔. 
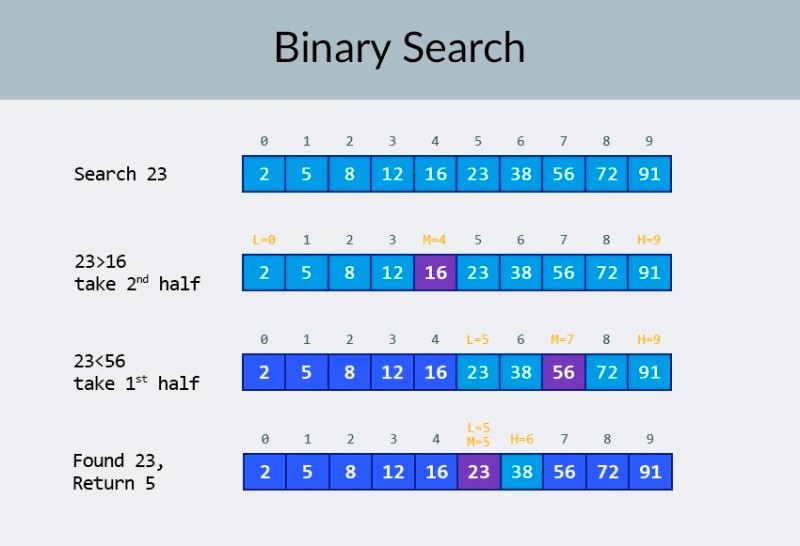 이미지의 맨 위 행에는 정렬된 배열이 표시됩니다. 그 안에서 숫자 23을 찾아야 합니다. 숫자를 반복하는 대신 배열을 두 부분으로 나누고 배열의 중간 숫자를 확인합니다. 셀 4에 있는 숫자를 찾아 확인합니다(이미지의 두 번째 행). 이 숫자는 16이고 우리는 23을 찾고 있습니다. 현재 숫자는 우리가 찾고 있는 것보다 적습니다. 그게 무슨 뜻이야? 그것은 의미합니다이전의 모든 숫자(숫자 16 앞에 있는 숫자)는 확인할 필요가 없습니다 . 배열이 정렬되어 있기 때문에 찾고 있는 숫자보다 작다는 것이 보장됩니다! 나머지 5개 요소 중에서 검색을 계속합니다. 메모:한 번의 비교만 수행했지만 이미 가능한 옵션의 절반을 제거했습니다. 5개의 요소만 남았습니다. 나머지 하위 배열을 다시 한 번 반으로 나누고 중간 요소(이미지의 세 번째 행)를 다시 취함으로써 이전 단계를 반복합니다. 숫자는 56이고 우리가 찾고 있는 것보다 큽니다. 그게 무슨 뜻이야? 그것은 우리가 다른 3개의 가능성을 제거했음을 의미합니다: 숫자 56 자체와 그 뒤의 두 숫자(배열이 정렬되기 때문에 23보다 큰 것이 보장되기 때문입니다). 확인할 수 있는 숫자는 2개(이미지의 마지막 행)뿐입니다. 배열 인덱스가 5와 6인 숫자입니다. 그 중 첫 번째 숫자를 확인하고 찾고 있던 숫자 23을 찾습니다! 지수는 5입니다! 알고리즘의 결과를 살펴보고 ' 복잡성을 분석하겠습니다. 그건 그렇고, 이제 이것이 왜 이진 검색이라고 불리는지 이해하실 것입니다. 이것은 반복적으로 데이터를 반으로 나누는 것에 의존합니다. 결과는 인상적입니다! 숫자를 찾기 위해 선형 검색을 사용했다면 최대 10번의 비교가 필요했지만 이진 검색을 사용하면 3번으로 작업을 완료했습니다! 최악의 경우, 4번의 비교가 있을 것입니다(마지막 단계에서 우리가 원하는 숫자가 첫 번째가 아니라 나머지 가능성 중 두 번째인 경우. 그렇다면 복잡성은 어떻습니까? 이것은 매우 흥미로운 점입니다 :) 이진 검색 알고리즘은 선형 검색 알고리즘(즉, 단순 반복)보다 배열의 요소 수에 훨씬 덜 의존합니다. 배열에 10개의 요소가 있는 경우 선형 검색에는 최대 10개의 비교가 필요하지만 이진 검색에는 최대 4개의 비교가 필요합니다. 2.5배 정도 차이가 납니다. 그러나 1000개 요소 배열의 경우 선형 검색에는 최대 1000개의 비교가 필요하지만 이진 검색에는 10개만 필요합니다 ! 그 차이는 이제 100배입니다! 메모:배열의 요소 수는 100배(10에서 1000으로) 증가했지만 이진 검색에 필요한 비교 수는 2.5배(4에서 10으로) 증가했습니다. 10,000개의 요소 에 도달하면 그 차이는 훨씬 더 커질 것입니다. 선형 검색의 경우 10,000개의 비교, 이진 검색의 경우 총 14개의 비교입니다 . 그리고 다시 요소 수가 1000배 증가하면(10에서 10000으로) 비교 횟수는 3.5배(4에서 14로)만 증가합니다. 이진 검색 알고리즘의 복잡도는 대수적 이거나, 빅오 표기법을 사용하는 경우 O(log n). 왜 그렇게 부릅니까? 로그는 지수의 반대와 같습니다. 이진 로그는 숫자를 얻기 위해 숫자 2를 올려야 하는 거듭제곱입니다. 예를 들어 이진 검색 알고리즘을 사용하여 검색해야 하는 10,000개의 요소가 있습니다.
이미지의 맨 위 행에는 정렬된 배열이 표시됩니다. 그 안에서 숫자 23을 찾아야 합니다. 숫자를 반복하는 대신 배열을 두 부분으로 나누고 배열의 중간 숫자를 확인합니다. 셀 4에 있는 숫자를 찾아 확인합니다(이미지의 두 번째 행). 이 숫자는 16이고 우리는 23을 찾고 있습니다. 현재 숫자는 우리가 찾고 있는 것보다 적습니다. 그게 무슨 뜻이야? 그것은 의미합니다이전의 모든 숫자(숫자 16 앞에 있는 숫자)는 확인할 필요가 없습니다 . 배열이 정렬되어 있기 때문에 찾고 있는 숫자보다 작다는 것이 보장됩니다! 나머지 5개 요소 중에서 검색을 계속합니다. 메모:한 번의 비교만 수행했지만 이미 가능한 옵션의 절반을 제거했습니다. 5개의 요소만 남았습니다. 나머지 하위 배열을 다시 한 번 반으로 나누고 중간 요소(이미지의 세 번째 행)를 다시 취함으로써 이전 단계를 반복합니다. 숫자는 56이고 우리가 찾고 있는 것보다 큽니다. 그게 무슨 뜻이야? 그것은 우리가 다른 3개의 가능성을 제거했음을 의미합니다: 숫자 56 자체와 그 뒤의 두 숫자(배열이 정렬되기 때문에 23보다 큰 것이 보장되기 때문입니다). 확인할 수 있는 숫자는 2개(이미지의 마지막 행)뿐입니다. 배열 인덱스가 5와 6인 숫자입니다. 그 중 첫 번째 숫자를 확인하고 찾고 있던 숫자 23을 찾습니다! 지수는 5입니다! 알고리즘의 결과를 살펴보고 ' 복잡성을 분석하겠습니다. 그건 그렇고, 이제 이것이 왜 이진 검색이라고 불리는지 이해하실 것입니다. 이것은 반복적으로 데이터를 반으로 나누는 것에 의존합니다. 결과는 인상적입니다! 숫자를 찾기 위해 선형 검색을 사용했다면 최대 10번의 비교가 필요했지만 이진 검색을 사용하면 3번으로 작업을 완료했습니다! 최악의 경우, 4번의 비교가 있을 것입니다(마지막 단계에서 우리가 원하는 숫자가 첫 번째가 아니라 나머지 가능성 중 두 번째인 경우. 그렇다면 복잡성은 어떻습니까? 이것은 매우 흥미로운 점입니다 :) 이진 검색 알고리즘은 선형 검색 알고리즘(즉, 단순 반복)보다 배열의 요소 수에 훨씬 덜 의존합니다. 배열에 10개의 요소가 있는 경우 선형 검색에는 최대 10개의 비교가 필요하지만 이진 검색에는 최대 4개의 비교가 필요합니다. 2.5배 정도 차이가 납니다. 그러나 1000개 요소 배열의 경우 선형 검색에는 최대 1000개의 비교가 필요하지만 이진 검색에는 10개만 필요합니다 ! 그 차이는 이제 100배입니다! 메모:배열의 요소 수는 100배(10에서 1000으로) 증가했지만 이진 검색에 필요한 비교 수는 2.5배(4에서 10으로) 증가했습니다. 10,000개의 요소 에 도달하면 그 차이는 훨씬 더 커질 것입니다. 선형 검색의 경우 10,000개의 비교, 이진 검색의 경우 총 14개의 비교입니다 . 그리고 다시 요소 수가 1000배 증가하면(10에서 10000으로) 비교 횟수는 3.5배(4에서 14로)만 증가합니다. 이진 검색 알고리즘의 복잡도는 대수적 이거나, 빅오 표기법을 사용하는 경우 O(log n). 왜 그렇게 부릅니까? 로그는 지수의 반대와 같습니다. 이진 로그는 숫자를 얻기 위해 숫자 2를 올려야 하는 거듭제곱입니다. 예를 들어 이진 검색 알고리즘을 사용하여 검색해야 하는 10,000개의 요소가 있습니다. 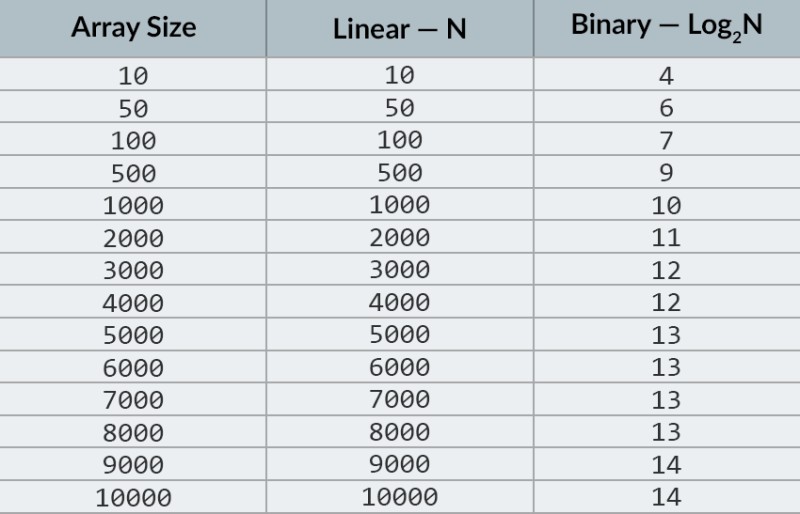 현재 이 작업을 수행하려면 최대 14번의 비교가 필요하다는 것을 알기 위해 값 테이블을 볼 수 있습니다. 그러나 아무도 이러한 테이블을 제공하지 않았고 정확한 최대 비교 수를 계산해야 하는 경우에는 어떻게 해야 합니까? 간단한 질문에 답하기만 하면 됩니다. 결과가 검사할 요소의 수보다 크거나 같도록 숫자 2를 어떤 힘으로 올려야 합니까? 10,000의 경우 14제곱입니다. 2의 13승은 너무 작은데(8192), 2의 14승 = 16384, 이 숫자는 조건을 충족합니다(배열의 요소 수보다 크거나 같음). 우리는 로그를 찾았습니다: 14. 그것이 우리가 필요한 비교의 수입니다! :) 알고리즘과 알고리즘의 복잡성은 한 강의에 맞추기에는 너무 광범위한 주제입니다. 그러나 그것을 아는 것이 매우 중요합니다. 많은 취업 면접에는 알고리즘과 관련된 질문이 포함될 것입니다. 이론적으로 몇 권의 책을 추천해 드릴 수 있습니다. " Grokking Algorithms " 로 시작할 수 있습니다 . 이 책의 예제는 Python으로 작성되었지만 이 책에서는 매우 간단한 언어와 예제를 사용합니다. 초보자에게 가장 좋은 옵션이며 더군다나 그다지 크지 않습니다. 더 진지한 독서 중에는 Robert Lafore 와 Robert Sedgewick 의 책이 있습니다.. 둘 다 Java로 작성되었으므로 학습이 조금 더 쉬워집니다. 결국, 당신은 이 언어에 꽤 익숙합니다! :) 수학 실력이 좋은 학생들에게 가장 좋은 선택은 Thomas Cormen의 책 입니다 . 그러나 이론만으로는 배를 채울 수 없습니다! 지식 != 능력 . HackerRank 및 LeetCode 에서 알고리즘과 관련된 문제 해결을 연습할 수 있습니다 . 이러한 웹사이트의 작업은 Google 및 Facebook의 인터뷰 중에도 자주 사용되므로 절대 지루하지 않을 것입니다 :) 이 수업 자료를 보강하려면 YouTube에서 빅오 표기법에 대한 훌륭한 비디오를 시청하는 것이 좋습니다. 다음 수업에서 만나요! :)
현재 이 작업을 수행하려면 최대 14번의 비교가 필요하다는 것을 알기 위해 값 테이블을 볼 수 있습니다. 그러나 아무도 이러한 테이블을 제공하지 않았고 정확한 최대 비교 수를 계산해야 하는 경우에는 어떻게 해야 합니까? 간단한 질문에 답하기만 하면 됩니다. 결과가 검사할 요소의 수보다 크거나 같도록 숫자 2를 어떤 힘으로 올려야 합니까? 10,000의 경우 14제곱입니다. 2의 13승은 너무 작은데(8192), 2의 14승 = 16384, 이 숫자는 조건을 충족합니다(배열의 요소 수보다 크거나 같음). 우리는 로그를 찾았습니다: 14. 그것이 우리가 필요한 비교의 수입니다! :) 알고리즘과 알고리즘의 복잡성은 한 강의에 맞추기에는 너무 광범위한 주제입니다. 그러나 그것을 아는 것이 매우 중요합니다. 많은 취업 면접에는 알고리즘과 관련된 질문이 포함될 것입니다. 이론적으로 몇 권의 책을 추천해 드릴 수 있습니다. " Grokking Algorithms " 로 시작할 수 있습니다 . 이 책의 예제는 Python으로 작성되었지만 이 책에서는 매우 간단한 언어와 예제를 사용합니다. 초보자에게 가장 좋은 옵션이며 더군다나 그다지 크지 않습니다. 더 진지한 독서 중에는 Robert Lafore 와 Robert Sedgewick 의 책이 있습니다.. 둘 다 Java로 작성되었으므로 학습이 조금 더 쉬워집니다. 결국, 당신은 이 언어에 꽤 익숙합니다! :) 수학 실력이 좋은 학생들에게 가장 좋은 선택은 Thomas Cormen의 책 입니다 . 그러나 이론만으로는 배를 채울 수 없습니다! 지식 != 능력 . HackerRank 및 LeetCode 에서 알고리즘과 관련된 문제 해결을 연습할 수 있습니다 . 이러한 웹사이트의 작업은 Google 및 Facebook의 인터뷰 중에도 자주 사용되므로 절대 지루하지 않을 것입니다 :) 이 수업 자료를 보강하려면 YouTube에서 빅오 표기법에 대한 훌륭한 비디오를 시청하는 것이 좋습니다. 다음 수업에서 만나요! :)

GO TO FULL VERSION