Hej! Dagens lektion kommer att skilja sig något från resten. Det kommer att skilja sig åt genom att det bara är indirekt relaterat till Java. Som sagt, detta ämne är mycket viktigt för alla programmerare. Vi ska prata om algoritmer . Vad är en algoritm? Enkelt uttryckt är det en sekvens av åtgärder som måste slutföras för att uppnå ett önskat resultat . Vi använder ofta algoritmer i vardagen. Till exempel, varje morgon har du en specifik uppgift: gå till skolan eller jobbet, och samtidigt vara:
Klädd
Rena
Fed
Vilken algoritm låter dig uppnå detta resultat?
Vakna med en väckarklocka.
Ta en dusch och tvätta dig.
Gör frukost och lite kaffe eller te.
Äta.
Om du inte strök dina kläder kvällen innan, stryk dem.
Klä på sig.
Lämna huset.
Denna sekvens av åtgärder kommer definitivt att låta dig få det önskade resultatet. Inom programmering arbetar vi ständigt med att slutföra uppgifter. En betydande del av dessa uppgifter kan utföras med algoritmer som redan är kända. Anta till exempel att din uppgift är att: sortera en lista med 100 namn i en array . Denna uppgift är ganska enkel, men den kan lösas på olika sätt. Här är en möjlig lösning: Algoritm för att sortera namn alfabetiskt:
Köp eller ladda ner 1961 års upplaga av Webster's Third New International Dictionary.
Hitta alla namn från vår lista i den här ordboken.
På ett papper skriver du sidan i ordboken där namnet finns.
Använd papperslapparna för att sortera namnen.
Kommer en sådan sekvens av handlingar att fullgöra vår uppgift? Ja, det kommer det säkert att göra. Är denna lösning effektiv ? Knappast. Här kommer vi till en annan mycket viktig aspekt av algoritmer: deras effektivitet . Det finns flera sätt att utföra denna uppgift. Men både i programmering och i det vanliga livet vill vi välja det mest effektiva sättet. Om din uppgift är att göra en smörad bit rostat bröd kan du börja med att så vete och mjölka en ko. Men det vore ineffektivtlösning — det kommer att ta mycket tid och kosta mycket pengar. Du kan utföra din enkla uppgift genom att helt enkelt köpa bröd och smör. Även om det låter dig lösa problemet, är algoritmen som involverar vete och en ko för komplex för att användas i praktiken. I programmering har vi speciell notation som kallas big O notation för att bedöma komplexiteten hos algoritmer. Big O gör det möjligt att bedöma hur mycket en algoritms exekveringstid beror på indatastorleken . Låt oss titta på det enklaste exemplet: dataöverföring. Föreställ dig att du behöver skicka lite information i form av en fil över en lång sträcka (till exempel 5000 miles). Vilken algoritm skulle vara mest effektiv? Det beror på vilken data du arbetar med. Anta till exempel att vi har en ljudfil som är 10 MB. I det här fallet är den mest effektiva algoritmen att skicka filen över Internet. Det kunde inte ta mer än ett par minuter! Låt oss upprepa vår algoritm: "Om du vill överföra information i form av filer över ett avstånd på 5000 miles, bör du skicka data via Internet". Excellent. Låt oss nu analysera det. Klarar den vår uppgift?Jo, det gör det. Men vad kan vi säga om dess komplexitet? Hmm, nu börjar det bli mer intressant. Faktum är att vår algoritm är väldigt beroende av indata, nämligen storleken på filerna. Om vi har 10 megabyte är allt bra. Men vad händer om vi behöver skicka 500 megabyte? 20 gigabyte? 500 terabyte? 30 petabyte? Kommer vår algoritm att sluta fungera? Nej, alla dessa mängder data kan verkligen överföras. Kommer det att ta längre tid? Ja det kommer det! Nu vet vi en viktig funktion i vår algoritm: ju större mängd data som ska skickas, desto längre tid tar det att köra algoritmen. Men vi skulle vilja ha en mer exakt förståelse för detta förhållande (mellan storleken på indatadata och den tid som krävs för att skicka den). I vårt fall är den algoritmiska komplexiteten linjär . "Linjär" betyder att när mängden indata ökar, kommer tiden det tar att skicka den att öka ungefär proportionellt. Om mängden data fördubblas kommer tiden som krävs för att skicka den att vara dubbelt så lång. Om data ökar med 10 gånger kommer överföringstiden att öka 10 gånger. Med hjälp av stor O-notation uttrycks komplexiteten i vår algoritm som O(n). Du bör komma ihåg denna notation för framtiden - den används alltid för algoritmer med linjär komplexitet. Observera att vi inte pratar om flera saker som kan variera här: Internethastighet, vår dators beräkningskraft och så vidare. När man bedömer komplexiteten hos en algoritm är det helt enkelt inte meningsfullt att överväga dessa faktorer – i alla händelser ligger de utanför vår kontroll. Big O-notation uttrycker komplexiteten i själva algoritmen, inte "miljön" som den körs i. Låt oss fortsätta med vårt exempel. Anta att vi till slut lär oss att vi behöver skicka filer på totalt 800 terabyte. Vi kan naturligtvis utföra vår uppgift genom att skicka dem över Internet. Det finns bara ett problem: vid vanliga hushållsdataöverföringshastigheter (100 megabit per sekund) tar det cirka 708 dagar. Snart 2 år! :O Vår algoritm passar uppenbarligen inte bra här. Vi behöver någon annan lösning! Oväntat kommer IT-jätten Amazon till vår räddning! Amazons snöskotertjänst låter oss ladda upp en stor mängd data till mobil lagring och sedan leverera den till önskad adress med lastbil! Så vi har en ny algoritm! "Om du vill överföra information i form av filer över ett avstånd på 5000 miles och att göra det skulle ta mer än 14 dagar att skicka via Internet, bör du skicka data på en Amazon-lastbil." Vi valde 14 dagar godtyckligt här. Låt oss säga att det här är den längsta perioden vi kan vänta. Låt oss analysera vår algoritm. Hur är det med dess hastighet? Även om lastbilen färdas i endast 50 mph, kommer den att klara 5000 miles på bara 100 timmar. Det här är lite över fyra dagar! Detta är mycket bättre än alternativet att skicka data över Internet. Och hur är det med komplexiteten i denna algoritm? Är det också linjärt, dvs O(n)? Nej det är det inte. Lastbilen bryr sig trots allt inte hur tungt du lastar den – den kommer fortfarande att köra i ungefär samma hastighet och komma fram i tid. Oavsett om vi har 800 terabyte, eller 10 gånger så, kommer lastbilen fortfarande att nå sin destination inom 5 dagar. Med andra ord har den lastbilsbaserade dataöverföringsalgoritmen konstant komplexitet. Här betyder "konstant" att det inte beror på indatastorleken. Sätt i en 1GB flash-enhet i lastbilen, den kommer inom 5 dagar. Sätt i diskar som innehåller 800 terabyte data, den kommer inom 5 dagar. När du använder big O-notation betecknas konstant komplexitet med O(1) . Vi har blivit bekanta med O(n) och O(1) , så låt oss nu titta på fler exempel i programmeringsvärlden :) Anta att du får en array med 100 nummer, och uppgiften är att visa vart och ett av dem på konsolen. Du skriver en vanlig forslinga som utför denna uppgift
int[] numbers = new int[100];
// ...fill the array with numbers
for (int i: numbers) {
System.out.println(i);
}
Vad är komplexiteten i denna algoritm? Linjär, dvs O(n). Antalet åtgärder som programmet måste utföra beror på hur många nummer som skickas till det. Om det finns 100 nummer i arrayen kommer det att finnas 100 åtgärder (påståenden för att visa strängar på skärmen). Om det finns 10 000 nummer i arrayen måste 10 000 åtgärder utföras. Kan vår algoritm förbättras på något sätt? Nej. Oavsett vad kommer vi att behöva göra N passerar genom arrayen och exekvera N satser för att visa strängar på konsolen. Tänk på ett annat exempel.
public static void main(String[] args) {
LinkedList<Integer> numbers = new LinkedList<>();
numbers.add(0, 20202);
numbers.add(0, 123);
numbers.add(0, 8283);
}
Vi har en tom LinkedListi vilken vi infogar flera siffror. Vi måste utvärdera den algoritmiska komplexiteten för att infoga ett enstaka nummer i LinkedListvårt exempel, och hur det beror på antalet element i listan. Svaret är O(1), dvs konstant komplexitet . Varför? Observera att vi lägger in varje nummer i början av listan. Dessutom kommer du ihåg att när du infogar en siffra i en LinkedListflyttar elementen inte någonstans. Länkarna (eller referenserna) uppdateras (om du har glömt hur LinkedList fungerar, titta på en av våra gamla lektioner ). Om den första siffran i vår lista är x, och vi infogar siffran y längst fram i listan, behöver vi bara göra följande:
x.previous = y;
y.previous = null;
y.next = x;
När vi uppdaterar länkarna bryr vi oss inte om hur många nummer som redan finns i ,LinkedList om en eller en miljard. Algoritmens komplexitet är konstant, dvs O(1).
Logaritmisk komplexitet
Få inte panik! :) Om ordet "logaritmisk" gör att du vill avsluta den här lektionen och sluta läsa, håll bara ut ett par minuter. Det kommer inte att finnas någon galen matematik här (det finns gott om sådana förklaringar på andra ställen), och vi kommer att plocka isär varje exempel. Föreställ dig att din uppgift är att hitta ett specifikt nummer i en uppsättning av 100 nummer. Mer exakt måste du kontrollera om den finns där eller inte. Så snart det önskade numret har hittats avslutas sökningen och du visar följande i konsolen: "Det nödvändiga numret hittades! Dess index i arrayen = ...." Hur skulle du utföra denna uppgift? Här är lösningen uppenbar: du måste iterera över elementen i arrayen en efter en, börja från den första (eller från den sista) och kontrollera om det aktuella numret matchar det du letar efter. Följaktligen, antalet åtgärder beror direkt på antalet element i arrayen. Om vi har 100 siffror kan vi potentiellt behöva gå till nästa element 100 gånger och utföra 100 jämförelser. Om det finns 1000 nummer kan det bli 1000 jämförelser. Detta är uppenbarligen linjär komplexitet, dvsO(n) . Och nu ska vi lägga till en förfining till vårt exempel: arrayen där du behöver hitta numret sorteras i stigande ordning . Ändrar detta något när det gäller vår uppgift? Vi kunde fortfarande utföra en brute-force-sökning efter det önskade numret. Men alternativt kan vi använda den välkända binära sökalgoritmen . I den översta raden i bilden ser vi en sorterad array. Vi måste hitta siffran 23 i den. Istället för att iterera över siffrorna delar vi helt enkelt arrayen i 2 delar och kontrollerar mittnumret i arrayen. Hitta numret som finns i cell 4 och kontrollera det (andra raden i bilden). Detta nummer är 16, och vi letar efter 23. Det nuvarande antalet är mindre än vad vi letar efter. Vad betyder det? Det betyder attalla tidigare siffror (de som ligger före siffran 16) behöver inte kontrolleras : de är garanterat mindre än det vi letar efter, eftersom vår array är sorterad! Vi fortsätter sökandet bland de återstående 5 elementen. Notera:vi har bara gjort en jämförelse, men vi har redan eliminerat hälften av de möjliga alternativen. Vi har bara 5 element kvar. Vi kommer att upprepa vårt föregående steg genom att återigen dela den återstående delmatrisen på mitten och återigen ta mittelementet (den tredje raden i bilden). Siffran är 56, och den är större än den vi letar efter. Vad betyder det? Det betyder att vi har eliminerat ytterligare 3 möjligheter: själva talet 56 samt de två siffrorna efter det (eftersom de garanterat är större än 23, eftersom arrayen är sorterad). Vi har bara 2 siffror kvar att kontrollera (den sista raden i bilden) — talen med arrayindex 5 och 6. Vi kontrollerar det första av dem och hittar det vi letade efter — talet 23! Dess index är 5! Låt oss titta på resultaten av vår algoritm, och sedan ska analysera dess komplexitet. Förresten, nu förstår du varför detta kallas binär sökning: det är beroende av att upprepade gånger dela data på hälften. Resultatet är imponerande! Om vi använde en linjär sökning för att leta efter numret skulle vi behöva upp till 10 jämförelser, men med en binär sökning klarade vi uppgiften med bara 3! I värsta fall skulle det bli 4 jämförelser (om numret vi ville ha i det sista steget var det andra av de återstående möjligheterna, snarare än det första. Så hur är det med dess komplexitet? Detta är en mycket intressant punkt :) Den binära sökalgoritmen är mycket mindre beroende av antalet element i arrayen än den linjära sökalgoritmen (det vill säga enkel iteration). Med 10 element i arrayen kommer en linjär sökning att behöva maximalt 10 jämförelser, men en binär sökning kommer att behöva maximalt 4 jämförelser. Det är en skillnad med en faktor 2,5. Men för en array med 1000 element kommer en linjär sökning att behöva upp till 1000 jämförelser, men en binär sökning skulle bara kräva 10 ! Skillnaden är nu 100 gånger! Notera:antalet element i arrayen har ökat 100 gånger (från 10 till 1000), men antalet jämförelser som krävs för en binär sökning har ökat med en faktor på endast 2,5 (från 4 till 10). Om vi kommer till 10 000 element blir skillnaden ännu mer imponerande: 10 000 jämförelser för linjär sökning, och totalt 14 jämförelser för binär sökning. Och igen, om antalet element ökar med 1000 gånger (från 10 till 10000), ökar antalet jämförelser med en faktor på endast 3,5 (från 4 till 14). Komplexiteten hos den binära sökalgoritmen är logaritmisk , eller, om vi använder stor O-notation, O(log n). Varför heter det så? Logaritmen är som motsatsen till exponentiering. Den binära logaritmen är den potens till vilken talet 2 måste höjas för att få ett tal. Till exempel har vi 10 000 element som vi behöver söka med den binära sökalgoritmen. För närvarande kan du titta på värdetabellen för att veta att detta kommer att kräva maximalt 14 jämförelser. Men vad händer om ingen har tillhandahållit en sådan tabell och du behöver beräkna det exakta maximala antalet jämförelser? Du behöver bara svara på en enkel fråga: till vilken kraft behöver du höja siffran 2 så att resultatet är större än eller lika med antalet element som ska kontrolleras? För 10 000 är det den 14:e potensen. 2 till 13:e potensen är för liten (8192), men 2 till 14:e potensen = 16384, och detta nummer uppfyller vårt villkor (det är större än eller lika med antalet element i arrayen). Vi hittade logaritmen: 14. Så många jämförelser kan vi behöva! :) Algoritmer och algoritmisk komplexitet är ett för brett ämne för att passa in i en lektion. Men att veta det är mycket viktigt: många anställningsintervjuer kommer att involvera frågor som involverar algoritmer. För teorin kan jag rekommendera några böcker för dig. Du kan börja med " Grokking Algorithms ". Exemplen i den här boken är skrivna i Python, men boken använder mycket enkelt språk och exempel. Det är det bästa alternativet för en nybörjare och dessutom är det inte särskilt stort. Bland mer seriös läsning har vi böcker av Robert Lafore och Robert Sedgewick. Båda är skrivna i Java, vilket kommer att göra inlärningen lite lättare för dig. Du är trots allt ganska bekant med detta språk! :) För elever med goda matematikkunskaper är det bästa alternativet Thomas Cormens bok . Men enbart teori kommer inte att fylla din mage! Kunskap != Förmåga . Du kan träna på att lösa problem som involverar algoritmer på HackerRank och LeetCode . Uppgifter från dessa webbplatser används ofta även under intervjuer på Google och Facebook, så du kommer definitivt inte att bli uttråkad :) För att förstärka detta lektionsmaterial rekommenderar jag att du tittar på denna utmärkta video om big O-notation på YouTube. Vi ses på nästa lektion! :)
 Som sagt, detta ämne är mycket viktigt för alla programmerare. Vi ska prata om algoritmer . Vad är en algoritm? Enkelt uttryckt är det en sekvens av åtgärder som måste slutföras för att uppnå ett önskat resultat . Vi använder ofta algoritmer i vardagen. Till exempel, varje morgon har du en specifik uppgift: gå till skolan eller jobbet, och samtidigt vara:
Som sagt, detta ämne är mycket viktigt för alla programmerare. Vi ska prata om algoritmer . Vad är en algoritm? Enkelt uttryckt är det en sekvens av åtgärder som måste slutföras för att uppnå ett önskat resultat . Vi använder ofta algoritmer i vardagen. Till exempel, varje morgon har du en specifik uppgift: gå till skolan eller jobbet, och samtidigt vara:
 I det här fallet är den mest effektiva algoritmen att skicka filen över Internet. Det kunde inte ta mer än ett par minuter! Låt oss upprepa vår algoritm: "Om du vill överföra information i form av filer över ett avstånd på 5000 miles, bör du skicka data via Internet". Excellent. Låt oss nu analysera det. Klarar den vår uppgift?Jo, det gör det. Men vad kan vi säga om dess komplexitet? Hmm, nu börjar det bli mer intressant. Faktum är att vår algoritm är väldigt beroende av indata, nämligen storleken på filerna. Om vi har 10 megabyte är allt bra. Men vad händer om vi behöver skicka 500 megabyte? 20 gigabyte? 500 terabyte? 30 petabyte? Kommer vår algoritm att sluta fungera? Nej, alla dessa mängder data kan verkligen överföras. Kommer det att ta längre tid? Ja det kommer det! Nu vet vi en viktig funktion i vår algoritm: ju större mängd data som ska skickas, desto längre tid tar det att köra algoritmen. Men vi skulle vilja ha en mer exakt förståelse för detta förhållande (mellan storleken på indatadata och den tid som krävs för att skicka den). I vårt fall är den algoritmiska komplexiteten linjär . "Linjär" betyder att när mängden indata ökar, kommer tiden det tar att skicka den att öka ungefär proportionellt. Om mängden data fördubblas kommer tiden som krävs för att skicka den att vara dubbelt så lång. Om data ökar med 10 gånger kommer överföringstiden att öka 10 gånger. Med hjälp av stor O-notation uttrycks komplexiteten i vår algoritm som O(n). Du bör komma ihåg denna notation för framtiden - den används alltid för algoritmer med linjär komplexitet. Observera att vi inte pratar om flera saker som kan variera här: Internethastighet, vår dators beräkningskraft och så vidare. När man bedömer komplexiteten hos en algoritm är det helt enkelt inte meningsfullt att överväga dessa faktorer – i alla händelser ligger de utanför vår kontroll. Big O-notation uttrycker komplexiteten i själva algoritmen, inte "miljön" som den körs i. Låt oss fortsätta med vårt exempel. Anta att vi till slut lär oss att vi behöver skicka filer på totalt 800 terabyte. Vi kan naturligtvis utföra vår uppgift genom att skicka dem över Internet. Det finns bara ett problem: vid vanliga hushållsdataöverföringshastigheter (100 megabit per sekund) tar det cirka 708 dagar. Snart 2 år! :O Vår algoritm passar uppenbarligen inte bra här. Vi behöver någon annan lösning! Oväntat kommer IT-jätten Amazon till vår räddning! Amazons snöskotertjänst låter oss ladda upp en stor mängd data till mobil lagring och sedan leverera den till önskad adress med lastbil!
I det här fallet är den mest effektiva algoritmen att skicka filen över Internet. Det kunde inte ta mer än ett par minuter! Låt oss upprepa vår algoritm: "Om du vill överföra information i form av filer över ett avstånd på 5000 miles, bör du skicka data via Internet". Excellent. Låt oss nu analysera det. Klarar den vår uppgift?Jo, det gör det. Men vad kan vi säga om dess komplexitet? Hmm, nu börjar det bli mer intressant. Faktum är att vår algoritm är väldigt beroende av indata, nämligen storleken på filerna. Om vi har 10 megabyte är allt bra. Men vad händer om vi behöver skicka 500 megabyte? 20 gigabyte? 500 terabyte? 30 petabyte? Kommer vår algoritm att sluta fungera? Nej, alla dessa mängder data kan verkligen överföras. Kommer det att ta längre tid? Ja det kommer det! Nu vet vi en viktig funktion i vår algoritm: ju större mängd data som ska skickas, desto längre tid tar det att köra algoritmen. Men vi skulle vilja ha en mer exakt förståelse för detta förhållande (mellan storleken på indatadata och den tid som krävs för att skicka den). I vårt fall är den algoritmiska komplexiteten linjär . "Linjär" betyder att när mängden indata ökar, kommer tiden det tar att skicka den att öka ungefär proportionellt. Om mängden data fördubblas kommer tiden som krävs för att skicka den att vara dubbelt så lång. Om data ökar med 10 gånger kommer överföringstiden att öka 10 gånger. Med hjälp av stor O-notation uttrycks komplexiteten i vår algoritm som O(n). Du bör komma ihåg denna notation för framtiden - den används alltid för algoritmer med linjär komplexitet. Observera att vi inte pratar om flera saker som kan variera här: Internethastighet, vår dators beräkningskraft och så vidare. När man bedömer komplexiteten hos en algoritm är det helt enkelt inte meningsfullt att överväga dessa faktorer – i alla händelser ligger de utanför vår kontroll. Big O-notation uttrycker komplexiteten i själva algoritmen, inte "miljön" som den körs i. Låt oss fortsätta med vårt exempel. Anta att vi till slut lär oss att vi behöver skicka filer på totalt 800 terabyte. Vi kan naturligtvis utföra vår uppgift genom att skicka dem över Internet. Det finns bara ett problem: vid vanliga hushållsdataöverföringshastigheter (100 megabit per sekund) tar det cirka 708 dagar. Snart 2 år! :O Vår algoritm passar uppenbarligen inte bra här. Vi behöver någon annan lösning! Oväntat kommer IT-jätten Amazon till vår räddning! Amazons snöskotertjänst låter oss ladda upp en stor mängd data till mobil lagring och sedan leverera den till önskad adress med lastbil!  Så vi har en ny algoritm! "Om du vill överföra information i form av filer över ett avstånd på 5000 miles och att göra det skulle ta mer än 14 dagar att skicka via Internet, bör du skicka data på en Amazon-lastbil." Vi valde 14 dagar godtyckligt här. Låt oss säga att det här är den längsta perioden vi kan vänta. Låt oss analysera vår algoritm. Hur är det med dess hastighet? Även om lastbilen färdas i endast 50 mph, kommer den att klara 5000 miles på bara 100 timmar. Det här är lite över fyra dagar! Detta är mycket bättre än alternativet att skicka data över Internet. Och hur är det med komplexiteten i denna algoritm? Är det också linjärt, dvs O(n)? Nej det är det inte. Lastbilen bryr sig trots allt inte hur tungt du lastar den – den kommer fortfarande att köra i ungefär samma hastighet och komma fram i tid. Oavsett om vi har 800 terabyte, eller 10 gånger så, kommer lastbilen fortfarande att nå sin destination inom 5 dagar. Med andra ord har den lastbilsbaserade dataöverföringsalgoritmen konstant komplexitet. Här betyder "konstant" att det inte beror på indatastorleken. Sätt i en 1GB flash-enhet i lastbilen, den kommer inom 5 dagar. Sätt i diskar som innehåller 800 terabyte data, den kommer inom 5 dagar. När du använder big O-notation betecknas konstant komplexitet med O(1) . Vi har blivit bekanta med O(n) och O(1) , så låt oss nu titta på fler exempel i programmeringsvärlden :) Anta att du får en array med 100 nummer, och uppgiften är att visa vart och ett av dem på konsolen. Du skriver en vanlig
Så vi har en ny algoritm! "Om du vill överföra information i form av filer över ett avstånd på 5000 miles och att göra det skulle ta mer än 14 dagar att skicka via Internet, bör du skicka data på en Amazon-lastbil." Vi valde 14 dagar godtyckligt här. Låt oss säga att det här är den längsta perioden vi kan vänta. Låt oss analysera vår algoritm. Hur är det med dess hastighet? Även om lastbilen färdas i endast 50 mph, kommer den att klara 5000 miles på bara 100 timmar. Det här är lite över fyra dagar! Detta är mycket bättre än alternativet att skicka data över Internet. Och hur är det med komplexiteten i denna algoritm? Är det också linjärt, dvs O(n)? Nej det är det inte. Lastbilen bryr sig trots allt inte hur tungt du lastar den – den kommer fortfarande att köra i ungefär samma hastighet och komma fram i tid. Oavsett om vi har 800 terabyte, eller 10 gånger så, kommer lastbilen fortfarande att nå sin destination inom 5 dagar. Med andra ord har den lastbilsbaserade dataöverföringsalgoritmen konstant komplexitet. Här betyder "konstant" att det inte beror på indatastorleken. Sätt i en 1GB flash-enhet i lastbilen, den kommer inom 5 dagar. Sätt i diskar som innehåller 800 terabyte data, den kommer inom 5 dagar. När du använder big O-notation betecknas konstant komplexitet med O(1) . Vi har blivit bekanta med O(n) och O(1) , så låt oss nu titta på fler exempel i programmeringsvärlden :) Anta att du får en array med 100 nummer, och uppgiften är att visa vart och ett av dem på konsolen. Du skriver en vanlig 
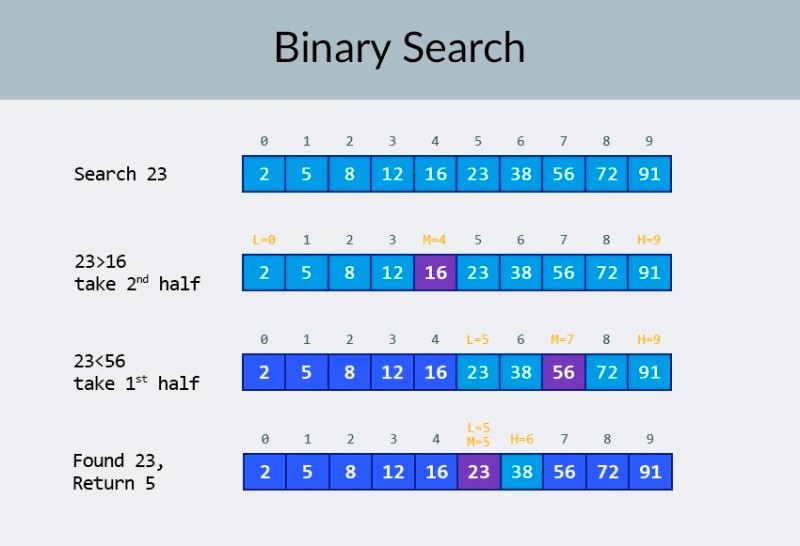 I den översta raden i bilden ser vi en sorterad array. Vi måste hitta siffran 23 i den. Istället för att iterera över siffrorna delar vi helt enkelt arrayen i 2 delar och kontrollerar mittnumret i arrayen. Hitta numret som finns i cell 4 och kontrollera det (andra raden i bilden). Detta nummer är 16, och vi letar efter 23. Det nuvarande antalet är mindre än vad vi letar efter. Vad betyder det? Det betyder attalla tidigare siffror (de som ligger före siffran 16) behöver inte kontrolleras : de är garanterat mindre än det vi letar efter, eftersom vår array är sorterad! Vi fortsätter sökandet bland de återstående 5 elementen. Notera:vi har bara gjort en jämförelse, men vi har redan eliminerat hälften av de möjliga alternativen. Vi har bara 5 element kvar. Vi kommer att upprepa vårt föregående steg genom att återigen dela den återstående delmatrisen på mitten och återigen ta mittelementet (den tredje raden i bilden). Siffran är 56, och den är större än den vi letar efter. Vad betyder det? Det betyder att vi har eliminerat ytterligare 3 möjligheter: själva talet 56 samt de två siffrorna efter det (eftersom de garanterat är större än 23, eftersom arrayen är sorterad). Vi har bara 2 siffror kvar att kontrollera (den sista raden i bilden) — talen med arrayindex 5 och 6. Vi kontrollerar det första av dem och hittar det vi letade efter — talet 23! Dess index är 5! Låt oss titta på resultaten av vår algoritm, och sedan ska analysera dess komplexitet. Förresten, nu förstår du varför detta kallas binär sökning: det är beroende av att upprepade gånger dela data på hälften. Resultatet är imponerande! Om vi använde en linjär sökning för att leta efter numret skulle vi behöva upp till 10 jämförelser, men med en binär sökning klarade vi uppgiften med bara 3! I värsta fall skulle det bli 4 jämförelser (om numret vi ville ha i det sista steget var det andra av de återstående möjligheterna, snarare än det första. Så hur är det med dess komplexitet? Detta är en mycket intressant punkt :) Den binära sökalgoritmen är mycket mindre beroende av antalet element i arrayen än den linjära sökalgoritmen (det vill säga enkel iteration). Med 10 element i arrayen kommer en linjär sökning att behöva maximalt 10 jämförelser, men en binär sökning kommer att behöva maximalt 4 jämförelser. Det är en skillnad med en faktor 2,5. Men för en array med 1000 element kommer en linjär sökning att behöva upp till 1000 jämförelser, men en binär sökning skulle bara kräva 10 ! Skillnaden är nu 100 gånger! Notera:antalet element i arrayen har ökat 100 gånger (från 10 till 1000), men antalet jämförelser som krävs för en binär sökning har ökat med en faktor på endast 2,5 (från 4 till 10). Om vi kommer till 10 000 element blir skillnaden ännu mer imponerande: 10 000 jämförelser för linjär sökning, och totalt 14 jämförelser för binär sökning. Och igen, om antalet element ökar med 1000 gånger (från 10 till 10000), ökar antalet jämförelser med en faktor på endast 3,5 (från 4 till 14). Komplexiteten hos den binära sökalgoritmen är logaritmisk , eller, om vi använder stor O-notation, O(log n). Varför heter det så? Logaritmen är som motsatsen till exponentiering. Den binära logaritmen är den potens till vilken talet 2 måste höjas för att få ett tal. Till exempel har vi 10 000 element som vi behöver söka med den binära sökalgoritmen.
I den översta raden i bilden ser vi en sorterad array. Vi måste hitta siffran 23 i den. Istället för att iterera över siffrorna delar vi helt enkelt arrayen i 2 delar och kontrollerar mittnumret i arrayen. Hitta numret som finns i cell 4 och kontrollera det (andra raden i bilden). Detta nummer är 16, och vi letar efter 23. Det nuvarande antalet är mindre än vad vi letar efter. Vad betyder det? Det betyder attalla tidigare siffror (de som ligger före siffran 16) behöver inte kontrolleras : de är garanterat mindre än det vi letar efter, eftersom vår array är sorterad! Vi fortsätter sökandet bland de återstående 5 elementen. Notera:vi har bara gjort en jämförelse, men vi har redan eliminerat hälften av de möjliga alternativen. Vi har bara 5 element kvar. Vi kommer att upprepa vårt föregående steg genom att återigen dela den återstående delmatrisen på mitten och återigen ta mittelementet (den tredje raden i bilden). Siffran är 56, och den är större än den vi letar efter. Vad betyder det? Det betyder att vi har eliminerat ytterligare 3 möjligheter: själva talet 56 samt de två siffrorna efter det (eftersom de garanterat är större än 23, eftersom arrayen är sorterad). Vi har bara 2 siffror kvar att kontrollera (den sista raden i bilden) — talen med arrayindex 5 och 6. Vi kontrollerar det första av dem och hittar det vi letade efter — talet 23! Dess index är 5! Låt oss titta på resultaten av vår algoritm, och sedan ska analysera dess komplexitet. Förresten, nu förstår du varför detta kallas binär sökning: det är beroende av att upprepade gånger dela data på hälften. Resultatet är imponerande! Om vi använde en linjär sökning för att leta efter numret skulle vi behöva upp till 10 jämförelser, men med en binär sökning klarade vi uppgiften med bara 3! I värsta fall skulle det bli 4 jämförelser (om numret vi ville ha i det sista steget var det andra av de återstående möjligheterna, snarare än det första. Så hur är det med dess komplexitet? Detta är en mycket intressant punkt :) Den binära sökalgoritmen är mycket mindre beroende av antalet element i arrayen än den linjära sökalgoritmen (det vill säga enkel iteration). Med 10 element i arrayen kommer en linjär sökning att behöva maximalt 10 jämförelser, men en binär sökning kommer att behöva maximalt 4 jämförelser. Det är en skillnad med en faktor 2,5. Men för en array med 1000 element kommer en linjär sökning att behöva upp till 1000 jämförelser, men en binär sökning skulle bara kräva 10 ! Skillnaden är nu 100 gånger! Notera:antalet element i arrayen har ökat 100 gånger (från 10 till 1000), men antalet jämförelser som krävs för en binär sökning har ökat med en faktor på endast 2,5 (från 4 till 10). Om vi kommer till 10 000 element blir skillnaden ännu mer imponerande: 10 000 jämförelser för linjär sökning, och totalt 14 jämförelser för binär sökning. Och igen, om antalet element ökar med 1000 gånger (från 10 till 10000), ökar antalet jämförelser med en faktor på endast 3,5 (från 4 till 14). Komplexiteten hos den binära sökalgoritmen är logaritmisk , eller, om vi använder stor O-notation, O(log n). Varför heter det så? Logaritmen är som motsatsen till exponentiering. Den binära logaritmen är den potens till vilken talet 2 måste höjas för att få ett tal. Till exempel har vi 10 000 element som vi behöver söka med den binära sökalgoritmen. 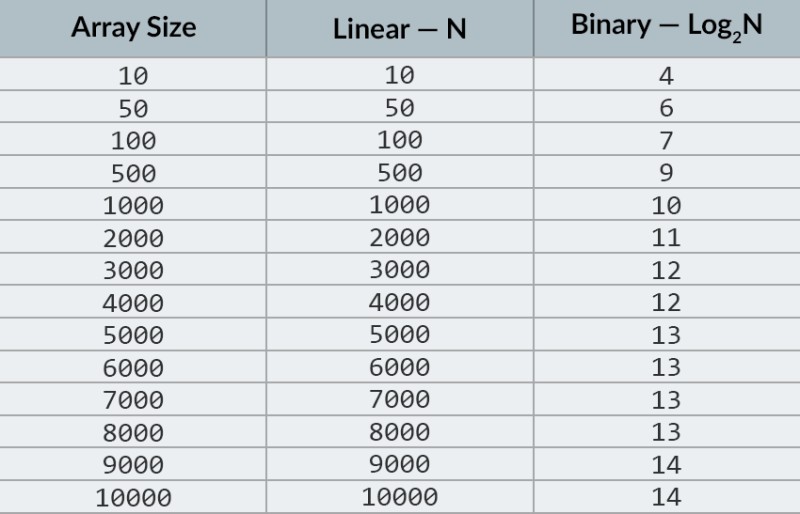 För närvarande kan du titta på värdetabellen för att veta att detta kommer att kräva maximalt 14 jämförelser. Men vad händer om ingen har tillhandahållit en sådan tabell och du behöver beräkna det exakta maximala antalet jämförelser? Du behöver bara svara på en enkel fråga: till vilken kraft behöver du höja siffran 2 så att resultatet är större än eller lika med antalet element som ska kontrolleras? För 10 000 är det den 14:e potensen. 2 till 13:e potensen är för liten (8192), men 2 till 14:e potensen = 16384, och detta nummer uppfyller vårt villkor (det är större än eller lika med antalet element i arrayen). Vi hittade logaritmen: 14. Så många jämförelser kan vi behöva! :) Algoritmer och algoritmisk komplexitet är ett för brett ämne för att passa in i en lektion. Men att veta det är mycket viktigt: många anställningsintervjuer kommer att involvera frågor som involverar algoritmer. För teorin kan jag rekommendera några böcker för dig. Du kan börja med " Grokking Algorithms ". Exemplen i den här boken är skrivna i Python, men boken använder mycket enkelt språk och exempel. Det är det bästa alternativet för en nybörjare och dessutom är det inte särskilt stort. Bland mer seriös läsning har vi böcker av Robert Lafore och Robert Sedgewick. Båda är skrivna i Java, vilket kommer att göra inlärningen lite lättare för dig. Du är trots allt ganska bekant med detta språk! :) För elever med goda matematikkunskaper är det bästa alternativet Thomas Cormens bok . Men enbart teori kommer inte att fylla din mage! Kunskap != Förmåga . Du kan träna på att lösa problem som involverar algoritmer på HackerRank och LeetCode . Uppgifter från dessa webbplatser används ofta även under intervjuer på Google och Facebook, så du kommer definitivt inte att bli uttråkad :) För att förstärka detta lektionsmaterial rekommenderar jag att du tittar på denna utmärkta video om big O-notation på YouTube. Vi ses på nästa lektion! :)
För närvarande kan du titta på värdetabellen för att veta att detta kommer att kräva maximalt 14 jämförelser. Men vad händer om ingen har tillhandahållit en sådan tabell och du behöver beräkna det exakta maximala antalet jämförelser? Du behöver bara svara på en enkel fråga: till vilken kraft behöver du höja siffran 2 så att resultatet är större än eller lika med antalet element som ska kontrolleras? För 10 000 är det den 14:e potensen. 2 till 13:e potensen är för liten (8192), men 2 till 14:e potensen = 16384, och detta nummer uppfyller vårt villkor (det är större än eller lika med antalet element i arrayen). Vi hittade logaritmen: 14. Så många jämförelser kan vi behöva! :) Algoritmer och algoritmisk komplexitet är ett för brett ämne för att passa in i en lektion. Men att veta det är mycket viktigt: många anställningsintervjuer kommer att involvera frågor som involverar algoritmer. För teorin kan jag rekommendera några böcker för dig. Du kan börja med " Grokking Algorithms ". Exemplen i den här boken är skrivna i Python, men boken använder mycket enkelt språk och exempel. Det är det bästa alternativet för en nybörjare och dessutom är det inte särskilt stort. Bland mer seriös läsning har vi böcker av Robert Lafore och Robert Sedgewick. Båda är skrivna i Java, vilket kommer att göra inlärningen lite lättare för dig. Du är trots allt ganska bekant med detta språk! :) För elever med goda matematikkunskaper är det bästa alternativet Thomas Cormens bok . Men enbart teori kommer inte att fylla din mage! Kunskap != Förmåga . Du kan träna på att lösa problem som involverar algoritmer på HackerRank och LeetCode . Uppgifter från dessa webbplatser används ofta även under intervjuer på Google och Facebook, så du kommer definitivt inte att bli uttråkad :) För att förstärka detta lektionsmaterial rekommenderar jag att du tittar på denna utmärkta video om big O-notation på YouTube. Vi ses på nästa lektion! :)

GO TO FULL VERSION