你好!今天的課程與其他課程略有不同。它的不同之處在於它僅與 Java 間接相關。 ![算法複雜度 - 1]() 也就是說,這個主題對每個程序員都非常重要。我們將討論算法。什麼是算法?簡而言之,它是為達到預期結果而必須完成的一些動作序列。我們在日常生活中經常使用算法。例如,每天早上您都有一項特定任務:去上學或上班,同時:
也就是說,這個主題對每個程序員都非常重要。我們將討論算法。什麼是算法?簡而言之,它是為達到預期結果而必須完成的一些動作序列。我們在日常生活中經常使用算法。例如,每天早上您都有一項特定任務:去上學或上班,同時:
![算法複雜度 - 2]() 在這種情況下,最有效的算法是通過 Internet 發送文件。不會超過幾分鐘!讓我們重述一下我們的算法: “如果你想在 5000 英里的距離內以文件形式傳輸信息,你應該通過 Internet 發送數據”。 出色的。現在我們來分析一下。 它完成我們的任務了嗎?嗯,是的,確實如此。但是關於它的複雜性我們能說什麼呢?嗯,現在事情變得越來越有趣了。事實上,我們的算法非常依賴於輸入數據,即文件的大小。如果我們有 10 兆字節,那麼一切都很好。但是如果我們需要發送 500 兆字節呢?20GB?500TB?30 PB?我們的算法會停止工作嗎?不,確實可以傳輸所有這些數據量。 會花更長的時間嗎?是的,它會的!現在我們知道了我們算法的一個重要特徵:發送的數據量越大,運行算法所需的時間就越長. 但我們希望更準確地了解這種關係(輸入數據大小與發送所需時間之間的關係)。在我們的例子中,算法複雜度是線性的。“線性”意味著隨著輸入數據量的增加,發送它所花費的時間將大致成比例地增加。如果數據量翻倍,那麼發送它所需的時間也會翻倍。如果數據增加10倍,那麼傳輸時間就會增加10倍。使用大 O 表示法,我們算法的複雜度表示為O(n). 你應該記住這個符號以備將來使用——它總是用於具有線性複雜度的算法。請注意,我們在這裡不是在談論可能會有所不同的幾件事:互聯網速度、我們計算機的計算能力等等。在評估算法的複雜性時,考慮這些因素根本沒有意義——無論如何,它們不在我們的控制範圍內。大 O 符號表示算法本身的複雜性,而不是它運行的“環境”。 讓我們繼續我們的例子。假設我們最終了解到我們需要發送總計 800 TB 的文件。當然,我們可以通過 Internet 發送它們來完成我們的任務。只有一個問題:以標準的家庭數據傳輸速率(每秒 100 兆位),大約需要 708 天。 快2年了!:O 我們的算法顯然不適合這裡。我們需要一些其他的解決方案!沒想到,IT巨頭亞馬遜來救我們了!亞馬遜的 Snowmobile 服務讓我們可以將大量數據上傳到移動存儲,然後通過卡車將其運送到所需地址!
在這種情況下,最有效的算法是通過 Internet 發送文件。不會超過幾分鐘!讓我們重述一下我們的算法: “如果你想在 5000 英里的距離內以文件形式傳輸信息,你應該通過 Internet 發送數據”。 出色的。現在我們來分析一下。 它完成我們的任務了嗎?嗯,是的,確實如此。但是關於它的複雜性我們能說什麼呢?嗯,現在事情變得越來越有趣了。事實上,我們的算法非常依賴於輸入數據,即文件的大小。如果我們有 10 兆字節,那麼一切都很好。但是如果我們需要發送 500 兆字節呢?20GB?500TB?30 PB?我們的算法會停止工作嗎?不,確實可以傳輸所有這些數據量。 會花更長的時間嗎?是的,它會的!現在我們知道了我們算法的一個重要特徵:發送的數據量越大,運行算法所需的時間就越長. 但我們希望更準確地了解這種關係(輸入數據大小與發送所需時間之間的關係)。在我們的例子中,算法複雜度是線性的。“線性”意味著隨著輸入數據量的增加,發送它所花費的時間將大致成比例地增加。如果數據量翻倍,那麼發送它所需的時間也會翻倍。如果數據增加10倍,那麼傳輸時間就會增加10倍。使用大 O 表示法,我們算法的複雜度表示為O(n). 你應該記住這個符號以備將來使用——它總是用於具有線性複雜度的算法。請注意,我們在這裡不是在談論可能會有所不同的幾件事:互聯網速度、我們計算機的計算能力等等。在評估算法的複雜性時,考慮這些因素根本沒有意義——無論如何,它們不在我們的控制範圍內。大 O 符號表示算法本身的複雜性,而不是它運行的“環境”。 讓我們繼續我們的例子。假設我們最終了解到我們需要發送總計 800 TB 的文件。當然,我們可以通過 Internet 發送它們來完成我們的任務。只有一個問題:以標準的家庭數據傳輸速率(每秒 100 兆位),大約需要 708 天。 快2年了!:O 我們的算法顯然不適合這裡。我們需要一些其他的解決方案!沒想到,IT巨頭亞馬遜來救我們了!亞馬遜的 Snowmobile 服務讓我們可以將大量數據上傳到移動存儲,然後通過卡車將其運送到所需地址! ![算法複雜度 - 3]() 所以,我們有一個新的算法! “如果你想在 5000 英里的距離內以文件的形式傳輸信息,並且這樣做需要超過 14 天才能通過互聯網發送,你應該用亞馬遜卡車發送數據。” 我們在這裡隨意選擇了14天。假設這是我們可以等待的最長期限。讓我們分析一下我們的算法。它的速度怎麼樣?即使卡車僅以 50 英里/小時的速度行駛,它也能在 100 小時內行駛 5000 英里。這才四天多一點!這比通過 Internet 發送數據的選擇要好得多。這個算法的複雜度如何?它也是線性的,即O(n)嗎?不它不是。畢竟,卡車不在乎你裝載它的重量——它仍然會以大致相同的速度行駛並準時到達。無論我們有 800 TB 還是 10 倍,卡車仍將在 5 天內到達目的地。換句話說,基於卡車的數據傳輸算法具有恆定的複雜度. 這裡,“恆定”意味著它不依賴於輸入數據的大小。在卡車上放一個 1GB 的閃存盤,它會在 5 天內到達。放入包含 800 TB 數據的磁盤,它會在 5 天內到達。使用大 O 表示法時,常數複雜度由O(1)表示。我們已經熟悉了O(n)和O(1),所以現在讓我們看一下編程世界中的更多示例 :) 假設給定一個包含 100 個數字的數組,任務是將每個數字顯示在控制台。
所以,我們有一個新的算法! “如果你想在 5000 英里的距離內以文件的形式傳輸信息,並且這樣做需要超過 14 天才能通過互聯網發送,你應該用亞馬遜卡車發送數據。” 我們在這裡隨意選擇了14天。假設這是我們可以等待的最長期限。讓我們分析一下我們的算法。它的速度怎麼樣?即使卡車僅以 50 英里/小時的速度行駛,它也能在 100 小時內行駛 5000 英里。這才四天多一點!這比通過 Internet 發送數據的選擇要好得多。這個算法的複雜度如何?它也是線性的,即O(n)嗎?不它不是。畢竟,卡車不在乎你裝載它的重量——它仍然會以大致相同的速度行駛並準時到達。無論我們有 800 TB 還是 10 倍,卡車仍將在 5 天內到達目的地。換句話說,基於卡車的數據傳輸算法具有恆定的複雜度. 這裡,“恆定”意味著它不依賴於輸入數據的大小。在卡車上放一個 1GB 的閃存盤,它會在 5 天內到達。放入包含 800 TB 數據的磁盤,它會在 5 天內到達。使用大 O 表示法時,常數複雜度由O(1)表示。我們已經熟悉了O(n)和O(1),所以現在讓我們看一下編程世界中的更多示例 :) 假設給定一個包含 100 個數字的數組,任務是將每個數字顯示在控制台。
![Java university]()
![算法複雜度 - 5]() 在圖像的頂行,我們看到一個排序數組。我們需要找到其中的數字 23。我們沒有遍歷數字,而是簡單地將數組分成兩部分並檢查數組中的中間數字。找到位於單元格 4 中的數字並檢查它(圖像中的第二行)。這個數字是 16,我們正在尋找 23。當前的數字小於我們正在尋找的數字。這意味著什麼?代表著不需要檢查所有前面的數字(位於數字 16 之前的數字):它們保證小於我們要查找的數字,因為我們的數組已排序!我們繼續在剩餘的 5 個元素中搜索。 筆記:我們只進行了一次比較,但我們已經排除了一半的可能選項。我們只剩下 5 個元素。我們將重複我們之前的步驟,再次將剩餘的子數組分成兩半,並再次取中間元素(圖像中的第 3 行)。這個數字是 56,它比我們要找的那個大。這意味著什麼?這意味著我們已經排除了另外 3 種可能性:數字 56 本身以及它後面的兩個數字(因為它們保證大於 23,因為數組已排序)。我們只剩下 2 個數字要檢查(圖像中的最後一行)——數組索引為 5 和 6 的數字。我們檢查其中的第一個,然後找到我們要找的東西——數字 23!它的指數是5!讓我們看看我們的算法的結果,然後我們' 我們將分析其複雜性。順便說一下,現在你明白為什麼這被稱為二分查找了:它依賴於重複地將數據分成兩半。結果令人印象深刻!如果我們使用線性搜索來尋找數字,我們將需要多達 10 次比較,但是使用二分搜索,我們只需要 3 次就完成了任務!在最壞的情況下,會有 4 次比較(如果在最後一步中我們想要的數字是剩餘可能性中的第二種,而不是第一種。那麼它的複雜性呢?這是一個非常有趣的點:) 與線性搜索算法(即簡單迭代)相比,二分搜索算法對數組中元素數量的依賴要小得多。 數組中有10 個元素時,線性搜索最多需要 10 次比較,而二分搜索最多需要 4 次比較。這是 2.5 倍的差異。但是對於1000 個元素的數組,線性搜索將需要多達 1000 次比較,而二分搜索只需要10 次!現在相差100倍! 筆記:數組中的元素數量增加了 100 倍(從 10 到 1000),但是二分查找所需的比較次數只增加了 2.5 倍(從 4 到 10)。如果我們達到10,000 個元素,差異將更加可觀:線性搜索有 10,000 次比較,二分搜索總共有 14 次比較。同樣,如果元素數量增加 1000 倍(從 10 到 10000),則比較次數僅增加 3.5 倍(從 4 到 14)。 二分搜索算法的複雜度是對數的,或者,如果我們使用大 O 表示法,則為O(log n). 為什麼叫它?對數就像求冪的反面。二進制對數是數字 2 必須提高到的冪才能獲得一個數字。例如,我們有 10,000 個元素需要使用二分查找算法進行查找。
在圖像的頂行,我們看到一個排序數組。我們需要找到其中的數字 23。我們沒有遍歷數字,而是簡單地將數組分成兩部分並檢查數組中的中間數字。找到位於單元格 4 中的數字並檢查它(圖像中的第二行)。這個數字是 16,我們正在尋找 23。當前的數字小於我們正在尋找的數字。這意味著什麼?代表著不需要檢查所有前面的數字(位於數字 16 之前的數字):它們保證小於我們要查找的數字,因為我們的數組已排序!我們繼續在剩餘的 5 個元素中搜索。 筆記:我們只進行了一次比較,但我們已經排除了一半的可能選項。我們只剩下 5 個元素。我們將重複我們之前的步驟,再次將剩餘的子數組分成兩半,並再次取中間元素(圖像中的第 3 行)。這個數字是 56,它比我們要找的那個大。這意味著什麼?這意味著我們已經排除了另外 3 種可能性:數字 56 本身以及它後面的兩個數字(因為它們保證大於 23,因為數組已排序)。我們只剩下 2 個數字要檢查(圖像中的最後一行)——數組索引為 5 和 6 的數字。我們檢查其中的第一個,然後找到我們要找的東西——數字 23!它的指數是5!讓我們看看我們的算法的結果,然後我們' 我們將分析其複雜性。順便說一下,現在你明白為什麼這被稱為二分查找了:它依賴於重複地將數據分成兩半。結果令人印象深刻!如果我們使用線性搜索來尋找數字,我們將需要多達 10 次比較,但是使用二分搜索,我們只需要 3 次就完成了任務!在最壞的情況下,會有 4 次比較(如果在最後一步中我們想要的數字是剩餘可能性中的第二種,而不是第一種。那麼它的複雜性呢?這是一個非常有趣的點:) 與線性搜索算法(即簡單迭代)相比,二分搜索算法對數組中元素數量的依賴要小得多。 數組中有10 個元素時,線性搜索最多需要 10 次比較,而二分搜索最多需要 4 次比較。這是 2.5 倍的差異。但是對於1000 個元素的數組,線性搜索將需要多達 1000 次比較,而二分搜索只需要10 次!現在相差100倍! 筆記:數組中的元素數量增加了 100 倍(從 10 到 1000),但是二分查找所需的比較次數只增加了 2.5 倍(從 4 到 10)。如果我們達到10,000 個元素,差異將更加可觀:線性搜索有 10,000 次比較,二分搜索總共有 14 次比較。同樣,如果元素數量增加 1000 倍(從 10 到 10000),則比較次數僅增加 3.5 倍(從 4 到 14)。 二分搜索算法的複雜度是對數的,或者,如果我們使用大 O 表示法,則為O(log n). 為什麼叫它?對數就像求冪的反面。二進制對數是數字 2 必須提高到的冪才能獲得一個數字。例如,我們有 10,000 個元素需要使用二分查找算法進行查找。 ![算法複雜度 - 6]() 目前,您可以查看值表就知道這樣做最多需要 14 次比較。但是,如果沒有人提供這樣的表格並且您需要計算確切的最大比較次數怎麼辦?你只需要回答一個簡單的問題:你需要將數字 2 提高到多少次方才能使結果大於或等於要檢查的元素數? 對於 10,000,它是 14 次方。2的13次方太小了(8192),但是2的14次方=16384,並且這個數字滿足我們的條件(它大於或等於數組中元素的數量)。我們找到了對數:14。這就是我們可能需要的比較次數!:) 算法和算法的複雜性是一個太寬泛的話題,一節課都講不完。但知道這一點非常重要:許多求職面試都會涉及涉及算法的問題。對於理論,我可以為您推荐一些書籍。您可以從“ Grokking 算法”開始。本書中的示例是用 Python 編寫的,但本書使用的語言和示例非常簡單。這是初學者的最佳選擇,而且,它不是很大。在更嚴肅的閱讀中,我們有Robert Lafore和Robert Sedgewick的書. 兩者都是用 Java 編寫的,這將使您的學習更容易一些。畢竟,您對這門語言相當熟悉!:) 對於具有良好數學技能的學生,最好的選擇是Thomas Cormen 的書。但是光靠理論是填不飽肚子的! 知識!=能力。您可以在HackerRank和LeetCode上練習解決涉及算法的問題。這些網站的任務甚至在谷歌和 Facebook 的面試中也經常使用,所以你絕對不會覺得無聊:) 為了強化本課程材料,我建議你在 YouTube 上觀看這個關於大 O 符號的優秀視頻。下節課見!:)
目前,您可以查看值表就知道這樣做最多需要 14 次比較。但是,如果沒有人提供這樣的表格並且您需要計算確切的最大比較次數怎麼辦?你只需要回答一個簡單的問題:你需要將數字 2 提高到多少次方才能使結果大於或等於要檢查的元素數? 對於 10,000,它是 14 次方。2的13次方太小了(8192),但是2的14次方=16384,並且這個數字滿足我們的條件(它大於或等於數組中元素的數量)。我們找到了對數:14。這就是我們可能需要的比較次數!:) 算法和算法的複雜性是一個太寬泛的話題,一節課都講不完。但知道這一點非常重要:許多求職面試都會涉及涉及算法的問題。對於理論,我可以為您推荐一些書籍。您可以從“ Grokking 算法”開始。本書中的示例是用 Python 編寫的,但本書使用的語言和示例非常簡單。這是初學者的最佳選擇,而且,它不是很大。在更嚴肅的閱讀中,我們有Robert Lafore和Robert Sedgewick的書. 兩者都是用 Java 編寫的,這將使您的學習更容易一些。畢竟,您對這門語言相當熟悉!:) 對於具有良好數學技能的學生,最好的選擇是Thomas Cormen 的書。但是光靠理論是填不飽肚子的! 知識!=能力。您可以在HackerRank和LeetCode上練習解決涉及算法的問題。這些網站的任務甚至在谷歌和 Facebook 的面試中也經常使用,所以你絕對不會覺得無聊:) 為了強化本課程材料,我建議你在 YouTube 上觀看這個關於大 O 符號的優秀視頻。下節課見!:)
![Java webinar]()
 也就是說,這個主題對每個程序員都非常重要。我們將討論算法。什麼是算法?簡而言之,它是為達到預期結果而必須完成的一些動作序列。我們在日常生活中經常使用算法。例如,每天早上您都有一項特定任務:去上學或上班,同時:
也就是說,這個主題對每個程序員都非常重要。我們將討論算法。什麼是算法?簡而言之,它是為達到預期結果而必須完成的一些動作序列。我們在日常生活中經常使用算法。例如,每天早上您都有一項特定任務:去上學或上班,同時:
- 穿著衣服
- 乾淨的
- 美聯儲
- 使用鬧鐘叫醒。
- 衝個澡,把自己洗乾淨。
- 做早餐和一些咖啡或茶。
- 吃。
- 如果你前一天晚上沒有熨衣服,那就熨吧。
- 穿上衣服。
- 離開這房子。
- 購買或下載 1961 年版的韋氏第三版新國際詞典。
- 在這本詞典中找到我們列表中的每個名字。
- 在一張紙上,寫下名字所在的字典頁碼。
- 用紙片對名字進行排序。
 在這種情況下,最有效的算法是通過 Internet 發送文件。不會超過幾分鐘!讓我們重述一下我們的算法: “如果你想在 5000 英里的距離內以文件形式傳輸信息,你應該通過 Internet 發送數據”。 出色的。現在我們來分析一下。 它完成我們的任務了嗎?嗯,是的,確實如此。但是關於它的複雜性我們能說什麼呢?嗯,現在事情變得越來越有趣了。事實上,我們的算法非常依賴於輸入數據,即文件的大小。如果我們有 10 兆字節,那麼一切都很好。但是如果我們需要發送 500 兆字節呢?20GB?500TB?30 PB?我們的算法會停止工作嗎?不,確實可以傳輸所有這些數據量。 會花更長的時間嗎?是的,它會的!現在我們知道了我們算法的一個重要特徵:發送的數據量越大,運行算法所需的時間就越長. 但我們希望更準確地了解這種關係(輸入數據大小與發送所需時間之間的關係)。在我們的例子中,算法複雜度是線性的。“線性”意味著隨著輸入數據量的增加,發送它所花費的時間將大致成比例地增加。如果數據量翻倍,那麼發送它所需的時間也會翻倍。如果數據增加10倍,那麼傳輸時間就會增加10倍。使用大 O 表示法,我們算法的複雜度表示為O(n). 你應該記住這個符號以備將來使用——它總是用於具有線性複雜度的算法。請注意,我們在這裡不是在談論可能會有所不同的幾件事:互聯網速度、我們計算機的計算能力等等。在評估算法的複雜性時,考慮這些因素根本沒有意義——無論如何,它們不在我們的控制範圍內。大 O 符號表示算法本身的複雜性,而不是它運行的“環境”。 讓我們繼續我們的例子。假設我們最終了解到我們需要發送總計 800 TB 的文件。當然,我們可以通過 Internet 發送它們來完成我們的任務。只有一個問題:以標準的家庭數據傳輸速率(每秒 100 兆位),大約需要 708 天。 快2年了!:O 我們的算法顯然不適合這裡。我們需要一些其他的解決方案!沒想到,IT巨頭亞馬遜來救我們了!亞馬遜的 Snowmobile 服務讓我們可以將大量數據上傳到移動存儲,然後通過卡車將其運送到所需地址!
在這種情況下,最有效的算法是通過 Internet 發送文件。不會超過幾分鐘!讓我們重述一下我們的算法: “如果你想在 5000 英里的距離內以文件形式傳輸信息,你應該通過 Internet 發送數據”。 出色的。現在我們來分析一下。 它完成我們的任務了嗎?嗯,是的,確實如此。但是關於它的複雜性我們能說什麼呢?嗯,現在事情變得越來越有趣了。事實上,我們的算法非常依賴於輸入數據,即文件的大小。如果我們有 10 兆字節,那麼一切都很好。但是如果我們需要發送 500 兆字節呢?20GB?500TB?30 PB?我們的算法會停止工作嗎?不,確實可以傳輸所有這些數據量。 會花更長的時間嗎?是的,它會的!現在我們知道了我們算法的一個重要特徵:發送的數據量越大,運行算法所需的時間就越長. 但我們希望更準確地了解這種關係(輸入數據大小與發送所需時間之間的關係)。在我們的例子中,算法複雜度是線性的。“線性”意味著隨著輸入數據量的增加,發送它所花費的時間將大致成比例地增加。如果數據量翻倍,那麼發送它所需的時間也會翻倍。如果數據增加10倍,那麼傳輸時間就會增加10倍。使用大 O 表示法,我們算法的複雜度表示為O(n). 你應該記住這個符號以備將來使用——它總是用於具有線性複雜度的算法。請注意,我們在這裡不是在談論可能會有所不同的幾件事:互聯網速度、我們計算機的計算能力等等。在評估算法的複雜性時,考慮這些因素根本沒有意義——無論如何,它們不在我們的控制範圍內。大 O 符號表示算法本身的複雜性,而不是它運行的“環境”。 讓我們繼續我們的例子。假設我們最終了解到我們需要發送總計 800 TB 的文件。當然,我們可以通過 Internet 發送它們來完成我們的任務。只有一個問題:以標準的家庭數據傳輸速率(每秒 100 兆位),大約需要 708 天。 快2年了!:O 我們的算法顯然不適合這裡。我們需要一些其他的解決方案!沒想到,IT巨頭亞馬遜來救我們了!亞馬遜的 Snowmobile 服務讓我們可以將大量數據上傳到移動存儲,然後通過卡車將其運送到所需地址!  所以,我們有一個新的算法! “如果你想在 5000 英里的距離內以文件的形式傳輸信息,並且這樣做需要超過 14 天才能通過互聯網發送,你應該用亞馬遜卡車發送數據。” 我們在這裡隨意選擇了14天。假設這是我們可以等待的最長期限。讓我們分析一下我們的算法。它的速度怎麼樣?即使卡車僅以 50 英里/小時的速度行駛,它也能在 100 小時內行駛 5000 英里。這才四天多一點!這比通過 Internet 發送數據的選擇要好得多。這個算法的複雜度如何?它也是線性的,即O(n)嗎?不它不是。畢竟,卡車不在乎你裝載它的重量——它仍然會以大致相同的速度行駛並準時到達。無論我們有 800 TB 還是 10 倍,卡車仍將在 5 天內到達目的地。換句話說,基於卡車的數據傳輸算法具有恆定的複雜度. 這裡,“恆定”意味著它不依賴於輸入數據的大小。在卡車上放一個 1GB 的閃存盤,它會在 5 天內到達。放入包含 800 TB 數據的磁盤,它會在 5 天內到達。使用大 O 表示法時,常數複雜度由O(1)表示。我們已經熟悉了O(n)和O(1),所以現在讓我們看一下編程世界中的更多示例 :) 假設給定一個包含 100 個數字的數組,任務是將每個數字顯示在控制台。
所以,我們有一個新的算法! “如果你想在 5000 英里的距離內以文件的形式傳輸信息,並且這樣做需要超過 14 天才能通過互聯網發送,你應該用亞馬遜卡車發送數據。” 我們在這裡隨意選擇了14天。假設這是我們可以等待的最長期限。讓我們分析一下我們的算法。它的速度怎麼樣?即使卡車僅以 50 英里/小時的速度行駛,它也能在 100 小時內行駛 5000 英里。這才四天多一點!這比通過 Internet 發送數據的選擇要好得多。這個算法的複雜度如何?它也是線性的,即O(n)嗎?不它不是。畢竟,卡車不在乎你裝載它的重量——它仍然會以大致相同的速度行駛並準時到達。無論我們有 800 TB 還是 10 倍,卡車仍將在 5 天內到達目的地。換句話說,基於卡車的數據傳輸算法具有恆定的複雜度. 這裡,“恆定”意味著它不依賴於輸入數據的大小。在卡車上放一個 1GB 的閃存盤,它會在 5 天內到達。放入包含 800 TB 數據的磁盤,它會在 5 天內到達。使用大 O 表示法時,常數複雜度由O(1)表示。我們已經熟悉了O(n)和O(1),所以現在讓我們看一下編程世界中的更多示例 :) 假設給定一個包含 100 個數字的數組,任務是將每個數字顯示在控制台。for您編寫一個執行此任務的 普通循環

int[] numbers = new int[100];
// ...fill the array with numbers
for (int i: numbers) {
System.out.println(i);
}
public static void main(String[] args) {
LinkedList<Integer> numbers = new LinkedList<>();
numbers.add(0, 20202);
numbers.add(0, 123);
numbers.add(0, 8283);
}
LinkedList,我們在其中插入幾個數字。在我們的示例中,我們需要評估將單個數字插入到的算法複雜性LinkedList,以及它如何取決於列表中元素的數量。答案是O(1),即復雜度不變。為什麼?請注意,我們在列表的開頭插入了每個數字。此外,您會記得,當您向 a 中插入一個數字時LinkedList,元素不會移動到任何地方。鏈接(或引用)已更新(如果您忘記了 LinkedList 的工作原理,請查看我們的舊課程之一)。如果我們列表中的第一個數字是x,並且我們在列表的前面插入數字 y ,那麼我們需要做的就是:
x.previous = y;
y.previous = null;
y.next = x;
LinkedList,無論是一還是十億。算法的複雜度是常數,即O(1)。
對數複雜度
不要恐慌!:) 如果“對數”這個詞讓您想結束本課並停止閱讀,請堅持幾分鐘。這裡不會有任何瘋狂的數學(在其他地方有很多類似的解釋),我們將挑選每個例子。想像一下,您的任務是在 100 個數字的數組中找到一個特定的數字。更準確地說,您需要檢查它是否存在。一旦找到所需的數字,搜索就會結束,您會在控制台中顯示以下內容:“找到所需的數字!它在數組中的索引 = ...”。您將如何完成此任務?這裡的解決方案很明顯:您需要一個一個地遍歷數組的元素,從第一個(或最後一個)開始,並檢查當前數字是否與您要查找的數字匹配。因此,動作的數量直接取決於數組中元素的數量。如果我們有 100 個數字,那麼我們可能需要轉到下一個元素 100 次並執行 100 次比較。如果有 1000 個數字,那麼可能會有 1000 次比較。這顯然是線性複雜度,即O(n)。現在我們將對我們的示例添加一個改進:您需要查找數字的數組按升序排序。這對我們的任務有什麼改變嗎?我們仍然可以對所需的數字執行暴力搜索。但或者,我們可以使用眾所周知的二進制搜索算法。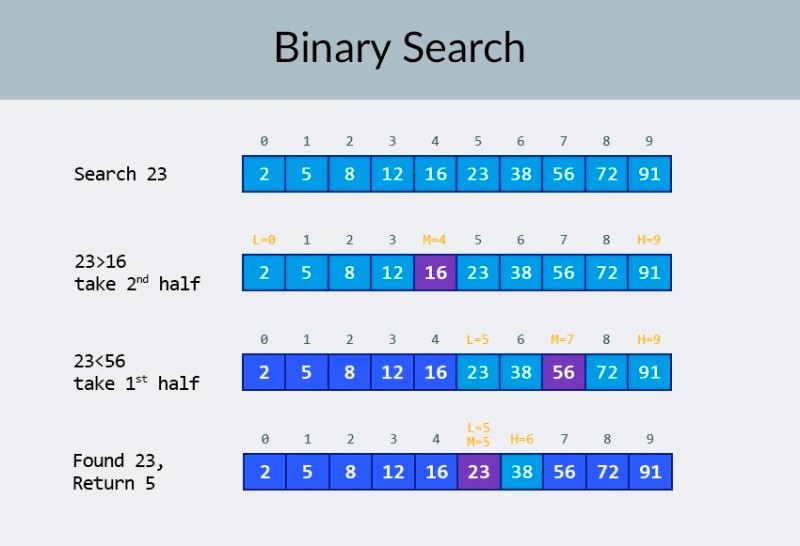 在圖像的頂行,我們看到一個排序數組。我們需要找到其中的數字 23。我們沒有遍歷數字,而是簡單地將數組分成兩部分並檢查數組中的中間數字。找到位於單元格 4 中的數字並檢查它(圖像中的第二行)。這個數字是 16,我們正在尋找 23。當前的數字小於我們正在尋找的數字。這意味著什麼?代表著不需要檢查所有前面的數字(位於數字 16 之前的數字):它們保證小於我們要查找的數字,因為我們的數組已排序!我們繼續在剩餘的 5 個元素中搜索。 筆記:我們只進行了一次比較,但我們已經排除了一半的可能選項。我們只剩下 5 個元素。我們將重複我們之前的步驟,再次將剩餘的子數組分成兩半,並再次取中間元素(圖像中的第 3 行)。這個數字是 56,它比我們要找的那個大。這意味著什麼?這意味著我們已經排除了另外 3 種可能性:數字 56 本身以及它後面的兩個數字(因為它們保證大於 23,因為數組已排序)。我們只剩下 2 個數字要檢查(圖像中的最後一行)——數組索引為 5 和 6 的數字。我們檢查其中的第一個,然後找到我們要找的東西——數字 23!它的指數是5!讓我們看看我們的算法的結果,然後我們' 我們將分析其複雜性。順便說一下,現在你明白為什麼這被稱為二分查找了:它依賴於重複地將數據分成兩半。結果令人印象深刻!如果我們使用線性搜索來尋找數字,我們將需要多達 10 次比較,但是使用二分搜索,我們只需要 3 次就完成了任務!在最壞的情況下,會有 4 次比較(如果在最後一步中我們想要的數字是剩餘可能性中的第二種,而不是第一種。那麼它的複雜性呢?這是一個非常有趣的點:) 與線性搜索算法(即簡單迭代)相比,二分搜索算法對數組中元素數量的依賴要小得多。 數組中有10 個元素時,線性搜索最多需要 10 次比較,而二分搜索最多需要 4 次比較。這是 2.5 倍的差異。但是對於1000 個元素的數組,線性搜索將需要多達 1000 次比較,而二分搜索只需要10 次!現在相差100倍! 筆記:數組中的元素數量增加了 100 倍(從 10 到 1000),但是二分查找所需的比較次數只增加了 2.5 倍(從 4 到 10)。如果我們達到10,000 個元素,差異將更加可觀:線性搜索有 10,000 次比較,二分搜索總共有 14 次比較。同樣,如果元素數量增加 1000 倍(從 10 到 10000),則比較次數僅增加 3.5 倍(從 4 到 14)。 二分搜索算法的複雜度是對數的,或者,如果我們使用大 O 表示法,則為O(log n). 為什麼叫它?對數就像求冪的反面。二進制對數是數字 2 必須提高到的冪才能獲得一個數字。例如,我們有 10,000 個元素需要使用二分查找算法進行查找。
在圖像的頂行,我們看到一個排序數組。我們需要找到其中的數字 23。我們沒有遍歷數字,而是簡單地將數組分成兩部分並檢查數組中的中間數字。找到位於單元格 4 中的數字並檢查它(圖像中的第二行)。這個數字是 16,我們正在尋找 23。當前的數字小於我們正在尋找的數字。這意味著什麼?代表著不需要檢查所有前面的數字(位於數字 16 之前的數字):它們保證小於我們要查找的數字,因為我們的數組已排序!我們繼續在剩餘的 5 個元素中搜索。 筆記:我們只進行了一次比較,但我們已經排除了一半的可能選項。我們只剩下 5 個元素。我們將重複我們之前的步驟,再次將剩餘的子數組分成兩半,並再次取中間元素(圖像中的第 3 行)。這個數字是 56,它比我們要找的那個大。這意味著什麼?這意味著我們已經排除了另外 3 種可能性:數字 56 本身以及它後面的兩個數字(因為它們保證大於 23,因為數組已排序)。我們只剩下 2 個數字要檢查(圖像中的最後一行)——數組索引為 5 和 6 的數字。我們檢查其中的第一個,然後找到我們要找的東西——數字 23!它的指數是5!讓我們看看我們的算法的結果,然後我們' 我們將分析其複雜性。順便說一下,現在你明白為什麼這被稱為二分查找了:它依賴於重複地將數據分成兩半。結果令人印象深刻!如果我們使用線性搜索來尋找數字,我們將需要多達 10 次比較,但是使用二分搜索,我們只需要 3 次就完成了任務!在最壞的情況下,會有 4 次比較(如果在最後一步中我們想要的數字是剩餘可能性中的第二種,而不是第一種。那麼它的複雜性呢?這是一個非常有趣的點:) 與線性搜索算法(即簡單迭代)相比,二分搜索算法對數組中元素數量的依賴要小得多。 數組中有10 個元素時,線性搜索最多需要 10 次比較,而二分搜索最多需要 4 次比較。這是 2.5 倍的差異。但是對於1000 個元素的數組,線性搜索將需要多達 1000 次比較,而二分搜索只需要10 次!現在相差100倍! 筆記:數組中的元素數量增加了 100 倍(從 10 到 1000),但是二分查找所需的比較次數只增加了 2.5 倍(從 4 到 10)。如果我們達到10,000 個元素,差異將更加可觀:線性搜索有 10,000 次比較,二分搜索總共有 14 次比較。同樣,如果元素數量增加 1000 倍(從 10 到 10000),則比較次數僅增加 3.5 倍(從 4 到 14)。 二分搜索算法的複雜度是對數的,或者,如果我們使用大 O 表示法,則為O(log n). 為什麼叫它?對數就像求冪的反面。二進制對數是數字 2 必須提高到的冪才能獲得一個數字。例如,我們有 10,000 個元素需要使用二分查找算法進行查找。 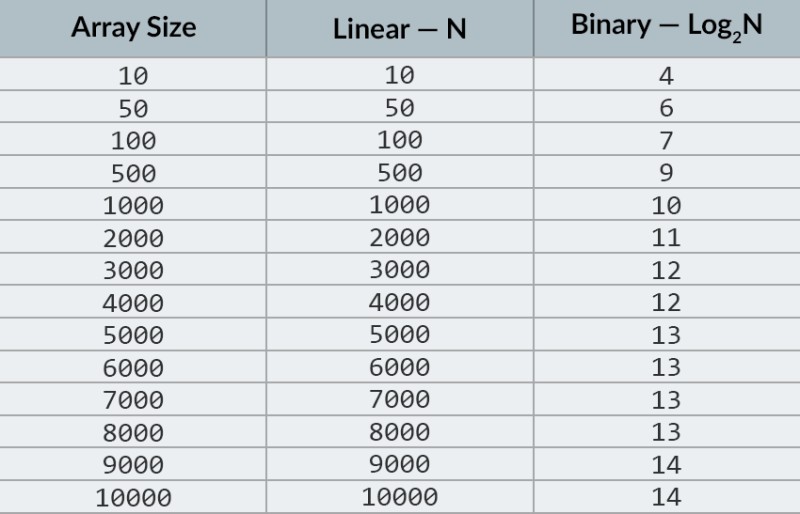 目前,您可以查看值表就知道這樣做最多需要 14 次比較。但是,如果沒有人提供這樣的表格並且您需要計算確切的最大比較次數怎麼辦?你只需要回答一個簡單的問題:你需要將數字 2 提高到多少次方才能使結果大於或等於要檢查的元素數? 對於 10,000,它是 14 次方。2的13次方太小了(8192),但是2的14次方=16384,並且這個數字滿足我們的條件(它大於或等於數組中元素的數量)。我們找到了對數:14。這就是我們可能需要的比較次數!:) 算法和算法的複雜性是一個太寬泛的話題,一節課都講不完。但知道這一點非常重要:許多求職面試都會涉及涉及算法的問題。對於理論,我可以為您推荐一些書籍。您可以從“ Grokking 算法”開始。本書中的示例是用 Python 編寫的,但本書使用的語言和示例非常簡單。這是初學者的最佳選擇,而且,它不是很大。在更嚴肅的閱讀中,我們有Robert Lafore和Robert Sedgewick的書. 兩者都是用 Java 編寫的,這將使您的學習更容易一些。畢竟,您對這門語言相當熟悉!:) 對於具有良好數學技能的學生,最好的選擇是Thomas Cormen 的書。但是光靠理論是填不飽肚子的! 知識!=能力。您可以在HackerRank和LeetCode上練習解決涉及算法的問題。這些網站的任務甚至在谷歌和 Facebook 的面試中也經常使用,所以你絕對不會覺得無聊:) 為了強化本課程材料,我建議你在 YouTube 上觀看這個關於大 O 符號的優秀視頻。下節課見!:)
目前,您可以查看值表就知道這樣做最多需要 14 次比較。但是,如果沒有人提供這樣的表格並且您需要計算確切的最大比較次數怎麼辦?你只需要回答一個簡單的問題:你需要將數字 2 提高到多少次方才能使結果大於或等於要檢查的元素數? 對於 10,000,它是 14 次方。2的13次方太小了(8192),但是2的14次方=16384,並且這個數字滿足我們的條件(它大於或等於數組中元素的數量)。我們找到了對數:14。這就是我們可能需要的比較次數!:) 算法和算法的複雜性是一個太寬泛的話題,一節課都講不完。但知道這一點非常重要:許多求職面試都會涉及涉及算法的問題。對於理論,我可以為您推荐一些書籍。您可以從“ Grokking 算法”開始。本書中的示例是用 Python 編寫的,但本書使用的語言和示例非常簡單。這是初學者的最佳選擇,而且,它不是很大。在更嚴肅的閱讀中,我們有Robert Lafore和Robert Sedgewick的書. 兩者都是用 Java 編寫的,這將使您的學習更容易一些。畢竟,您對這門語言相當熟悉!:) 對於具有良好數學技能的學生,最好的選擇是Thomas Cormen 的書。但是光靠理論是填不飽肚子的! 知識!=能力。您可以在HackerRank和LeetCode上練習解決涉及算法的問題。這些網站的任務甚至在谷歌和 Facebook 的面試中也經常使用,所以你絕對不會覺得無聊:) 為了強化本課程材料,我建議你在 YouTube 上觀看這個關於大 O 符號的優秀視頻。下節課見!:)

GO TO FULL VERSION