5.1 Adatelosztás
Nézzük meg, hogyan oszlanak meg az adatok a kulcstól függően a fürt csomópontjai között. A Cassandra lehetővé teszi az adatelosztási stratégia beállítását. Az első ilyen stratégia az md5 kulcsértéktől függően osztja el az adatokat - egy véletlenszerű particionáló. A második figyelembe veszi magának a kulcsnak a bitreprezentációját - az ordinális jelölést (byte-ordered particioner).
Az első stratégia többnyire több előnnyel jár, mivel nem kell aggódnia a szerverek közötti egyenletes adatelosztás és az ilyen problémák miatt. A második stratégiát ritka esetekben használják, például ha intervallum lekérdezésekre (tartomány lekérdezésre) van szükség. Fontos megjegyezni, hogy ezt a stratégiát a klaszter létrehozása előtt választják meg, és valójában nem változtatható meg az adatok teljes újratöltése nélkül.
A Cassandra egy konzisztens kivonatolásként ismert technikát alkalmaz az adatok elosztására. Ez a megközelítés lehetővé teszi az adatok elosztását a csomópontok között, és győződjön meg arról, hogy új csomópont hozzáadásakor és eltávolításakor az átvitt adatmennyiség kicsi. Ehhez minden csomóponthoz egy címke (token) van hozzárendelve, amely az összes md5 kulcsérték készletét részekre osztja. Mivel a legtöbb esetben a RandomPartitioner-t használják, nézzük meg.
Mint mondtam, a RandomPartitioner minden kulcshoz 128 bites md5-öt számít ki. Annak meghatározásához, hogy mely csomópontokban lesznek tárolva az adatok, egyszerűen átmegy a csomópontok összes címkéjén a legkisebbtől a legnagyobbig, és amikor a címke értéke nagyobb lesz, mint az md5 kulcs értéke, akkor ez a csomópont, valamint egy a következő csomópontok száma (a címkék sorrendjében) van kiválasztva tárolásra. A kiválasztott csomópontok teljes számának meg kell egyeznie a replikációs tényezővel. A replikációs szint minden kulcstérhez be van állítva, és lehetővé teszi az adatok redundanciájának (adatredundancia) beállítását.


Mielőtt egy csomópontot hozzá lehetne adni a fürthöz, címkével kell ellátni. Az ezen címke és a következő címke közötti rést lefedő kulcsok százalékos aránya határozza meg, hogy mennyi adatot tárol a csomópont. A fürt teljes címkekészletét gyűrűnek nevezzük.
Íme egy illusztráció a beépített nodetool segédprogram használatával, amely egy 6 csomópontból álló fürtgyűrűt jelenít meg, egyenletesen elosztott címkékkel.

5.2 Adatkonzisztencia írás közben
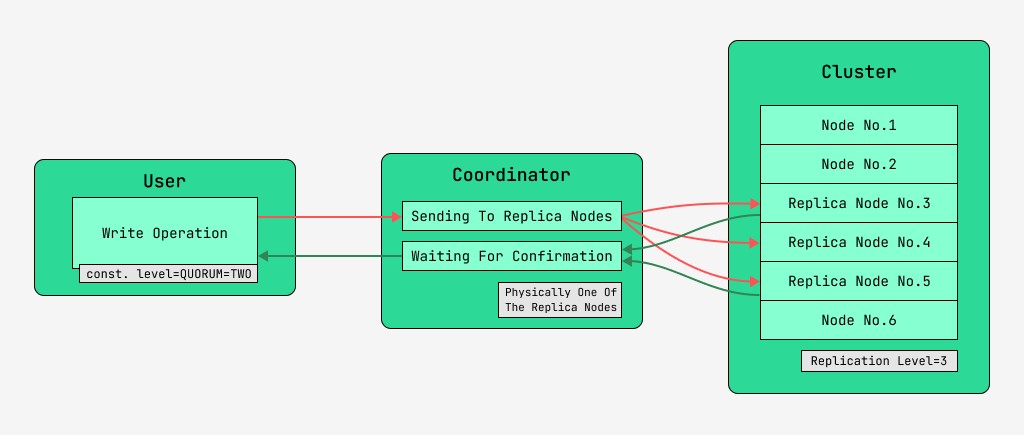
A Cassandra-fürt csomópontjai egyenértékűek, és az ügyfelek bármelyikhez kapcsolódhatnak, írás és olvasás céljából egyaránt. A kérések a koordináció szakaszán mennek keresztül, melynek során a szerver, miután a kulcs és a jelölés segítségével kiderítette, hogy melyik csomóponton kell elhelyezni az adatokat, kéréseket küld ezeknek a csomópontoknak. A koordinációt végző csomópontot hívjuk koordinátornak , a rekordot az adott kulccsal történő mentésre kiválasztott csomópontokat pedig replika csomópontoknak. Fizikailag az egyik replika csomópont lehet a koordinátor – ez csak a kulcstól, a jelöléstől és a címkéktől függ.
Minden kéréshez, mind az olvasáshoz, mind az íráshoz, beállítható az adatkonzisztencia szintje.
Írásnál ez a szint befolyásolja azon replika csomópontok számát, amelyek megvárják a művelet sikeres befejezésének megerősítését (az adatok írása), mielőtt visszaadják a vezérlést a felhasználónak. Emlékeztetőül a következő konzisztencia szintek vannak:
- EGY – a koordinátor kéréseket küld az összes replika csomópontnak, de miután az első csomóponttól megerősítést vár, visszaadja a vezérlést a felhasználónak;
- KETTŐ - ugyanaz, de a koordinátor megerősítést vár az első két csomóponttól, mielőtt visszaadná az irányítást;
- HÁROM – hasonló, de a koordinátor megerősítést vár az első három csomóponttól, mielőtt visszaadná a vezérlést;
- MEGHATÁROZOTTSÁG - A határozatképesség összegyűjtése megtörténik: a koordinátor a rekord megerősítését várja a replika csomópontok több mint felétől, nevezetesen kerek (N / 2) + 1, ahol N a replikációs szint;
- LOCAL_QUORUM – A koordinátor megerősítést vár a replika csomópontok több mint felétől ugyanabban az adatközpontban, ahol a koordinátor található (potenciálisan minden kérésnél eltérő). Lehetővé teszi, hogy megszabaduljon az adatok más adatközpontokba való küldésével kapcsolatos késésektől. Ez a cikk csak futólag tárgyalja a sok adatközponttal való együttműködés kérdéseit;
- EACH_QUORUM – A koordinátor megerősítést vár az egyes adatközpontokban lévő replika csomópontok több mint felétől függetlenül;
- ALL - a koordinátor megerősítést vár az összes replika csomóponttól;
- ANY - lehetővé teszi az adatok írását, még akkor is, ha az összes replika csomópont nem válaszol. A koordinátor vagy az első válaszra vár az egyik replika csomóponttól, vagy az adatok tárolására a koordinátoron található utalásos átadás segítségével.
5.3 Adatkonzisztencia olvasás közben
Az olvasások esetében a konzisztencia szintje befolyásolja a replika csomópontok számát, amelyekből kiolvassák. Az olvasáshoz a következő konzisztenciaszintek vannak:
- EGY – a koordinátor kéréseket küld a legközelebbi replika csomópontnak. A többi replika is beolvasásra kerül az olvasás javításához a cassandra konfigurációban megadott valószínűséggel;
- A TWO ugyanaz, de a koordinátor kéréseket küld a két legközelebbi csomópontnak. A legnagyobb időbélyeggel rendelkező érték kerül kiválasztásra;
- HÁROM - hasonló az előző opcióhoz, de három csomóponttal;
- KORUM - a kvórum összegyűlik, vagyis a koordinátor kéréseket küld a replika csomópontok több mint felének, nevezetesen kerek (N / 2) + 1, ahol N a replikációs szint;
- LOCAL_QUORUM - az adatközpontban, amelyben a koordináció megtörténik, a határozatképesség összegyűjtésre kerül, és a legutóbbi időbélyeggel rendelkező adatok kerülnek visszaadásra;
- EACH_QUORUM – A koordinátor visszaküldi az adatokat az egyes adatközpontok határozatképességének összejövetele után;
- ALL – A koordinátor visszaadja az adatokat az összes replika csomópontból történő beolvasás után.

Így lehetőség van az olvasási és írási műveletek időkésleltetésének beállítására, valamint az egyes művelettípusok konzisztenciájának (hangolási konzisztenciájának), valamint elérhetőségének (rendelkezésre állásának) beállítására. Valójában a rendelkezésre állás közvetlenül összefügg az olvasási és írási konzisztencia szintjével, mivel ez határozza meg, hogy hány replikacsomópont szállhat le, és mennyit lehet még megerősíteni.
Ha azoknak a csomópontoknak a száma, ahonnan az írási nyugtázás jön, plusz azon csomópontok száma, amelyekből az olvasás történik, nagyobb, mint a replikációs szint, akkor garanciát vállalunk arra, hogy az írás után mindig beolvasásra kerül az új érték, és ez erős konzisztenciának (erős konzisztenciának) nevezik. Erős konzisztencia hiányában előfordulhat, hogy egy olvasási művelet elavult adatokat ad vissza.
Mindenesetre az érték végül továbbterjed a replikák között, de csak azután, hogy a koordinációs várakozás véget ért. Ezt a terjedést végső konzisztenciának nevezzük. Ha nem minden replika csomópont áll rendelkezésre az írás idején, akkor előbb-utóbb a helyreállítási eszközök, például a javító olvasások és az entrópia-csomópont-javítás lépnek életbe. Erről később.
Így a QUORUM olvasási és írási konzisztencia szintjével az erős konzisztencia mindig megmarad, és ez egyensúlyt teremt az olvasási és írási késleltetés között. Az ÖSSZES írás és az EGY olvasás esetén erős lesz a konzisztencia, az olvasás pedig gyorsabb és elérhetőbb lesz, azaz a hibás csomópontok száma, amelyeknél az olvasás még befejeződik, nagyobb lehet, mint a QUORUM esetén.
Az írási műveletekhez minden replika-munkavégző csomópontra szükség lesz. A ONE írásakor, az ÖSSZES olvasásakor is szigorú konzisztencia lesz, és gyorsabbak lesznek az írási műveletek és nagy lesz az írási elérhetőség, mert elég lesz csak megerősíteni, hogy az írási művelet legalább az egyik szerveren megtörtént, míg Az olvasás lassabb, és minden replika csomópontot igényel. Ha egy alkalmazás nem követeli meg a szigorú konzisztenciát, akkor az olvasási és írási műveletek felgyorsítása, valamint az elérhetőség javítása alacsonyabb konzisztenciaszintek beállításával lehetséges.
GO TO FULL VERSION