5.1 Datadistribusjon
La oss vurdere hvordan dataene fordeles avhengig av nøkkelen blant klyngenodene. Cassandra lar deg angi en datadistribusjonsstrategi. Den første slike strategien distribuerer data avhengig av md5-nøkkelverdien - en tilfeldig partisjonerer. Den andre tar hensyn til bitrepresentasjonen av selve nøkkelen - den ordinære markeringen (byte-ordnet partisjonerer).
Den første strategien gir for det meste flere fordeler, siden du ikke trenger å bekymre deg for jevn fordeling av data mellom servere og slike problemer. Den andre strategien brukes i sjeldne tilfeller, for eksempel hvis intervallspørringer (rekkeviddeskanning) er nødvendig. Det er viktig å merke seg at valget av denne strategien er gjort før opprettelsen av klyngen og faktisk ikke kan endres uten en fullstendig omlasting av dataene.
Cassandra bruker en teknikk kjent som konsekvent hashing for å distribuere data. Denne tilnærmingen lar deg distribuere data mellom noder og sørge for at når en ny node legges til og fjernes, er mengden data som overføres liten. For å gjøre dette tildeles hver node en etikett (token), som deler settet med alle md5-nøkkelverdier i deler. Siden RandomPartitioner brukes i de fleste tilfeller, la oss vurdere det.
Som jeg sa, RandomPartitioner beregner en 128-bit md5 for hver nøkkel. For å bestemme i hvilke noder dataene skal lagres, går den ganske enkelt gjennom alle etikettene til nodene fra minste til største, og når verdien av etiketten blir større enn verdien til md5-nøkkelen, så går denne noden sammen med en antall påfølgende noder (i rekkefølgen av etiketter) velges for lagring. Det totale antallet valgte noder må være lik replikasjonsfaktoren. Replikeringsnivået angis for hvert nøkkelområde og lar deg justere redundansen til data (dataredundans).


Før en node kan legges til klyngen, må den gis en etikett. Prosentandelen av nøkler som dekker gapet mellom denne etiketten og den neste bestemmer hvor mye data som skal lagres på noden. Hele settet med etiketter for en klynge kalles en ring.
Her er en illustrasjon som bruker det innebygde nodetool-verktøyet for å vise en klyngering med 6 noder med jevnt fordelte etiketter.

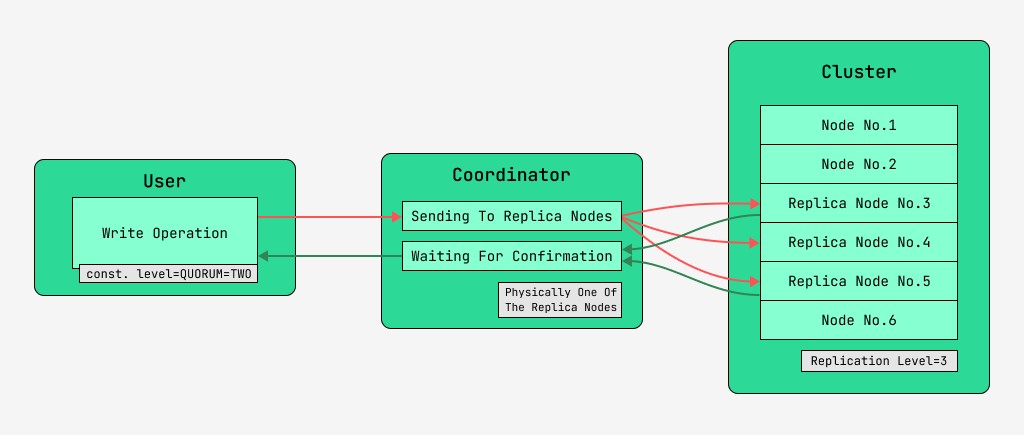
5.2 Datakonsistens ved skriving
Cassandra cluster noder er likeverdige, og klienter kan koble seg til hvilken som helst av dem, både for skriving og lesing. Forespørsler går gjennom koordineringsstadiet, der serveren, etter å ha funnet ut ved hjelp av nøkkelen og markeringen på hvilke noder dataene skal være, sender forespørsler til disse nodene. Vi vil kalle noden som utfører koordineringen for koordinatoren , og nodene som er valgt for å lagre posten med den gitte nøkkelen, replika - nodene. Fysisk kan en av replika-nodene være koordinator - det avhenger bare av nøkkel, markering og etiketter.
For hver forespørsel, både for lesing og skriving, er det mulig å angi nivået for datakonsistens.
For en skriving vil dette nivået påvirke antall replikanoder som vil vente på bekreftelse på vellykket fullføring av operasjonen (data skrevet) før kontrollen returneres til brukeren. For en ordens skyld er det disse konsistensnivåene:
- EN - koordinatoren sender forespørsler til alle replikanoder, men etter å ha ventet på bekreftelse fra den første noden, returnerer kontrollen til brukeren;
- TO - det samme, men koordinatoren venter på bekreftelse fra de to første nodene før han returnerer kontrollen;
- TRE - lignende, men koordinatoren venter på bekreftelse fra de tre første nodene før han returnerer kontrollen;
- KVORUM - et quorum er samlet: koordinatoren venter på bekreftelse av posten fra mer enn halvparten av replikaknutene, nemlig runde (N / 2) + 1, hvor N er replikasjonsnivået;
- LOCAL_QUORUM - Koordinatoren venter på bekreftelse fra mer enn halvparten av replika-nodene i samme datasenter der koordinatoren befinner seg (potensielt forskjellig for hver forespørsel). Lar deg bli kvitt forsinkelsene knyttet til sending av data til andre datasentre. Problemene med å jobbe med mange datasentre vurderes i denne artikkelen i forbifarten;
- EACH_QUORUM - Koordinatoren venter på bekreftelse fra mer enn halvparten av replika-nodene i hvert datasenter, uavhengig av hverandre;
- ALL - koordinatoren venter på bekreftelse fra alle replikaknutene;
- ANY - gjør det mulig å skrive data, selv om alle replikanoder ikke svarer. Koordinatoren venter enten på det første svaret fra en av replika-nodene, eller på at dataene skal lagres ved å bruke en antydet overlevering på koordinatoren.
5.3 Datakonsistens ved lesing
For avlesninger vil konsistensnivået påvirke antallet replikanoder som skal leses fra. For lesing er det disse konsistensnivåene:
- EN - koordinatoren sender forespørsler til nærmeste replikanode. Resten av kopiene leses også for lesreparasjon med sannsynligheten spesifisert i cassandra-konfigurasjonen;
- TO er like, men koordinatoren sender forespørsler til de to nærmeste nodene. Verdien med det største tidsstemplet er valgt;
- TRE - lik det forrige alternativet, men med tre noder;
- KVORUM - et quorum er samlet, det vil si at koordinatoren sender forespørsler til mer enn halvparten av replika-nodene, nemlig runde (N / 2) + 1, hvor N er replikasjonsnivået;
- LOCAL_QUORUM - et quorum samles inn i datasenteret der koordinering finner sted, og dataene med siste tidsstempel returneres;
- EACH_QUORUM - Koordinatoren returnerer data etter møtet med beslutningsdyktigheten i hvert av datasentrene;
- ALL - Koordinatoren returnerer data etter lesing fra alle replikaknutene.

Dermed er det mulig å justere tidsforsinkelsene for lese- og skriveoperasjoner og justere konsistensen (tune-konsistensen), samt tilgjengeligheten (tilgjengeligheten) for hver type operasjon. Faktisk er tilgjengelighet direkte relatert til konsistensnivået for lesing og skriving, da det bestemmer hvor mange replika-noder som kan gå ned og fortsatt bekreftes.
Hvis antall noder som skrivebekreftelsen kommer fra, pluss antall noder som lesingen er gjort fra, er større enn replikeringsnivået, så har vi en garanti for at den nye verdien alltid vil bli lest etter skrivingen, og dette kalles sterk konsistens (sterk konsistens). I fravær av sterk konsistens er det en mulighet for at en leseoperasjon vil returnere foreldede data.
Uansett vil verdien etter hvert forplante seg mellom replikaer, men først etter at koordinasjonsventingen er avsluttet. Denne forplantningen kalles eventuell konsistens. Hvis ikke alle replika-noder er tilgjengelige på tidspunktet for skrivingen, vil før eller senere gjenopprettingsverktøy som avhjelpende avlesninger og anti-entropi-node-reparasjon komme inn i bildet. Mer om dette senere.
Med et lese- og skrivekonsistensnivå i QUORUM vil sterk konsistens alltid opprettholdes, og dette vil være en balanse mellom lese- og skrivelatens. Med ALL skriving og EN lesing vil det være sterk konsistens og lesninger vil være raskere og mer tilgjengelige, dvs. antallet mislykkede noder der en lesing fortsatt vil bli fullført kan være større enn med KVORUM.
For skriveoperasjoner vil alle replika-arbeidernoder være nødvendige. Når man skriver ONE, leser ALLE, vil det også være streng konsistens, og skriveoperasjonene vil være raskere og skrivetilgjengeligheten vil være stor, fordi det vil være nok til kun å bekrefte at skriveoperasjonen fant sted på minst én av serverne, mens lesing er tregere og krever alle replikanoder. Hvis en applikasjon ikke har et krav om streng konsistens, er det mulig å fremskynde både lese- og skriveoperasjoner, samt forbedre tilgjengeligheten ved å sette lavere konsistensnivåer.
GO TO FULL VERSION