5.1 Pengagihan data
Mari kita pertimbangkan cara data diedarkan bergantung pada kunci antara nod kelompok. Cassandra membenarkan anda menetapkan strategi pengedaran data. Strategi pertama sedemikian mengedarkan data bergantung pada nilai kunci md5 - pembahagi rawak. Yang kedua mengambil kira perwakilan bit kunci itu sendiri - penanda ordinal (pembahagi tertib bait).
Strategi pertama, sebahagian besarnya, memberikan lebih banyak kelebihan, kerana anda tidak perlu risau tentang pengagihan data yang sekata antara pelayan dan masalah sedemikian. Strategi kedua digunakan dalam kes yang jarang berlaku, contohnya, jika pertanyaan selang waktu (imbasan julat) diperlukan. Adalah penting untuk ambil perhatian bahawa pilihan strategi ini dibuat sebelum penciptaan kluster dan sebenarnya tidak boleh diubah tanpa muat semula data yang lengkap.
Cassandra menggunakan teknik yang dikenali sebagai pencincangan konsisten untuk mengedarkan data. Pendekatan ini membolehkan anda mengedarkan data antara nod dan memastikan bahawa apabila nod baharu ditambah dan dialih keluar, jumlah data yang dipindahkan adalah kecil. Untuk melakukan ini, setiap nod diberikan label (token), yang membahagikan set semua nilai kunci md5 kepada beberapa bahagian. Oleh kerana RandomPartitioner digunakan dalam kebanyakan kes, mari kita pertimbangkan.
Seperti yang saya katakan, RandomPartitioner mengira md5 128-bit untuk setiap kunci. Untuk menentukan di mana nod data akan disimpan, ia hanya melalui semua label nod daripada terkecil kepada terbesar, dan apabila nilai label menjadi lebih besar daripada nilai kunci md5, maka nod ini, bersama-sama dengan bilangan nod berikutnya (dalam susunan label) dipilih untuk penyimpanan. Jumlah bilangan nod yang dipilih mestilah sama dengan faktor replikasi. Tahap replikasi ditetapkan untuk setiap ruang kekunci dan membolehkan anda melaraskan lebihan data (lebihan data).


Sebelum sesuatu nod boleh ditambah pada kluster, ia mesti diberi label. Peratusan kunci yang menutup jurang antara label ini dan yang seterusnya menentukan jumlah data yang akan disimpan pada nod. Keseluruhan set label untuk gugusan dipanggil cincin.
Berikut ialah ilustrasi menggunakan utiliti alat node terbina dalam untuk memaparkan gelang kelompok 6 nod dengan label jarak sekata.

5.2 Ketekalan data semasa menulis
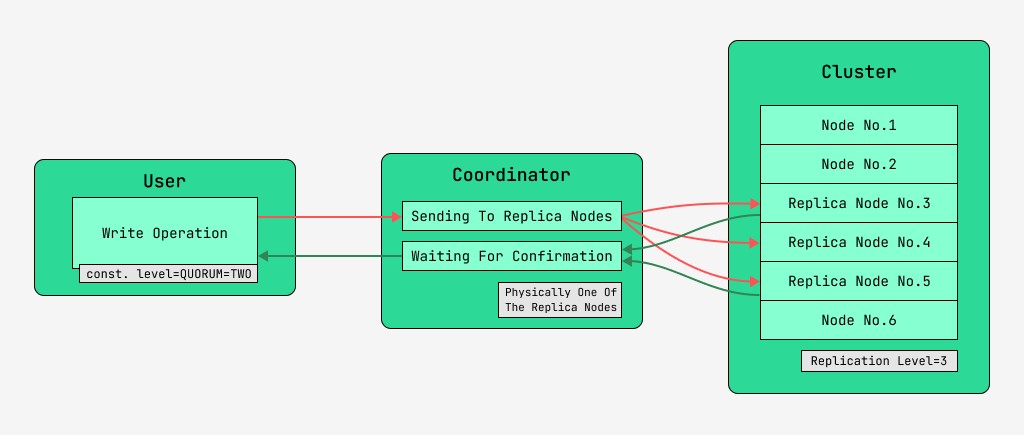
Nod kluster Cassandra adalah setara, dan pelanggan boleh menyambung kepada mana-mana nod, untuk menulis dan untuk membaca. Permintaan melalui peringkat penyelarasan, di mana, setelah mengetahui dengan bantuan kunci dan markup di mana nod data harus ditempatkan, pelayan menghantar permintaan ke nod ini. Kami akan memanggil nod yang melakukan penyelarasan sebagai koordinator , dan nod yang dipilih untuk menyimpan rekod dengan kunci yang diberikan, nod replika . Secara fizikal, salah satu nod replika boleh menjadi penyelaras - ia hanya bergantung pada kunci, penanda dan label.
Untuk setiap permintaan, baik untuk membaca dan menulis, adalah mungkin untuk menetapkan tahap ketekalan data.
Untuk penulisan, tahap ini akan mempengaruhi bilangan nod replika yang akan menunggu pengesahan kejayaan menyelesaikan operasi (data ditulis) sebelum mengembalikan kawalan kepada pengguna. Untuk rekod, terdapat tahap ketekalan ini:
- SATU - penyelaras menghantar permintaan kepada semua nod replika, tetapi selepas menunggu pengesahan dari nod pertama, mengembalikan kawalan kepada pengguna;
- DUA - sama, tetapi penyelaras menunggu pengesahan daripada dua nod pertama sebelum mengembalikan kawalan;
- TIGA - serupa, tetapi penyelaras menunggu pengesahan daripada tiga nod pertama sebelum mengembalikan kawalan;
- KUORUM - kuorum dikumpul: penyelaras sedang menunggu pengesahan rekod daripada lebih separuh daripada nod replika, iaitu bulat (N / 2) + 1, di mana N ialah tahap replikasi;
- LOCAL_QUORUM - Penyelaras sedang menunggu pengesahan daripada lebih separuh daripada nod replika di pusat data yang sama di mana penyelaras berada (berkemungkinan berbeza untuk setiap permintaan). Membolehkan anda menyingkirkan kelewatan yang berkaitan dengan penghantaran data ke pusat data lain. Isu bekerja dengan banyak pusat data dipertimbangkan dalam artikel ini secara terus;
- EACH_QUORUM - Penyelaras sedang menunggu pengesahan daripada lebih separuh daripada nod replika dalam setiap pusat data, secara bebas;
- SEMUA - penyelaras menunggu pengesahan daripada semua nod replika;
- ANY - memungkinkan untuk menulis data, walaupun semua nod replika tidak bertindak balas. Penyelaras menunggu sama ada untuk respons pertama daripada salah satu nod replika, atau untuk data disimpan menggunakan serahan isyarat pada penyelaras.
5.3 Ketekalan data semasa membaca
Untuk bacaan, tahap ketekalan akan mempengaruhi bilangan nod replika yang akan dibaca daripadanya. Untuk membaca, terdapat tahap ketekalan berikut:
- SATU - penyelaras menghantar permintaan ke nod replika terdekat. Selebihnya replika juga dibaca untuk pembaikan dibaca dengan kebarangkalian yang dinyatakan dalam konfigurasi cassandra;
- DUA adalah sama, tetapi penyelaras menghantar permintaan kepada dua nod terdekat. Nilai dengan cap masa terbesar dipilih;
- TIGA - sama dengan pilihan sebelumnya, tetapi dengan tiga nod;
- KUORUM - kuorum dikumpul, iaitu, penyelaras menghantar permintaan kepada lebih separuh daripada nod replika, iaitu bulat (N / 2) + 1, di mana N ialah tahap replikasi;
- LOCAL_QUORUM - kuorum dikumpulkan di pusat data tempat penyelarasan berlaku, dan data dengan cap masa terkini dikembalikan;
- EACH_QUORUM - Penyelaras mengembalikan data selepas mesyuarat kuorum di setiap pusat data;
- SEMUA - Penyelaras mengembalikan data selepas membaca dari semua nod replika.

Oleh itu, adalah mungkin untuk melaraskan kelewatan masa operasi baca dan tulis dan melaraskan konsistensi (konsistensi tala), serta ketersediaan (ketersediaan) setiap jenis operasi. Malah, ketersediaan berkait secara langsung dengan tahap ketekalan baca dan tulis, kerana ia menentukan bilangan nod replika yang boleh turun dan masih disahkan.
Jika bilangan nod dari mana pengakuan tulis datang, ditambah dengan bilangan nod dari mana bacaan dibuat, adalah lebih besar daripada tahap replikasi, maka kami mempunyai jaminan bahawa nilai baharu akan sentiasa dibaca selepas penulisan, dan ini dipanggil ketekalan kuat (strong consistency). Sekiranya tiada konsistensi yang kuat, terdapat kemungkinan operasi baca akan mengembalikan data basi.
Walau apa pun, nilai akhirnya akan disebarkan antara replika, tetapi hanya selepas penantian penyelarasan telah tamat. Penyebaran ini dipanggil konsistensi akhirnya. Jika tidak semua nod replika tersedia pada masa penulisan, maka lambat laun alat pemulihan seperti pembacaan pemulihan dan pembaikan nod anti-entropi akan dimainkan. Lebih lanjut mengenai ini kemudian.
Oleh itu, dengan tahap ketekalan baca dan tulis KUORUM, ketekalan yang kukuh akan sentiasa dikekalkan, dan ini akan menjadi keseimbangan antara kependaman membaca dan menulis. Dengan SEMUA penulisan dan SATU bacaan akan terdapat konsistensi yang kukuh dan bacaan akan menjadi lebih pantas dan lebih tersedia, iaitu bilangan nod yang gagal di mana bacaan masih akan diselesaikan boleh lebih besar daripada dengan QUORUM.
Untuk operasi tulis, semua nod pekerja replika akan diperlukan. Apabila menulis SATU, membaca SEMUA, terdapat juga konsistensi yang ketat, dan operasi tulis akan menjadi lebih pantas dan ketersediaan tulis akan menjadi besar, kerana ia akan mencukupi untuk mengesahkan hanya bahawa operasi tulis berlaku pada sekurang-kurangnya satu pelayan, manakala membaca adalah lebih perlahan dan memerlukan semua nod replika. Jika aplikasi tidak mempunyai keperluan untuk konsistensi yang ketat, maka adalah mungkin untuk mempercepatkan kedua-dua operasi baca dan tulis, serta meningkatkan ketersediaan dengan menetapkan tahap konsistensi yang lebih rendah.
GO TO FULL VERSION