5.1 Distribuția datelor
Să luăm în considerare modul în care datele sunt distribuite în funcție de cheia dintre nodurile clusterului. Cassandra vă permite să setați o strategie de distribuție a datelor. Prima astfel de strategie distribuie date în funcție de valoarea cheii md5 - un partitioner aleatoriu. Al doilea ia în considerare reprezentarea pe biți a cheii în sine - marcajul ordinal (partiționer ordonat pe octeți).
Prima strategie, în cea mai mare parte, oferă mai multe avantaje, deoarece nu trebuie să vă faceți griji cu privire la distribuirea uniformă a datelor între servere și astfel de probleme. A doua strategie este utilizată în cazuri rare, de exemplu, dacă sunt necesare interogări cu intervale (scanarea intervalului). Este important de menționat că alegerea acestei strategii se face înainte de crearea clusterului și, de fapt, nu poate fi schimbată fără o reîncărcare completă a datelor.
Cassandra folosește o tehnică cunoscută sub numele de hashing consistent pentru a distribui datele. Această abordare vă permite să distribuiți datele între noduri și să vă asigurați că atunci când un nou nod este adăugat și eliminat, cantitatea de date transferată este mică. Pentru a face acest lucru, fiecărui nod i se atribuie o etichetă (token), care împarte setul tuturor valorilor cheii md5 în părți. Deoarece RandomPartitioner este folosit în cele mai multe cazuri, să-l luăm în considerare.
După cum am spus, RandomPartitioner calculează un md5 de 128 de biți pentru fiecare cheie. Pentru a determina în ce noduri vor fi stocate datele, pur și simplu parcurge toate etichetele nodurilor de la cel mai mic la cel mai mare, iar când valoarea etichetei devine mai mare decât valoarea cheii md5, atunci acest nod, împreună cu un numărul de noduri ulterioare (în ordinea etichetelor) este selectat pentru stocare. Numărul total de noduri selectate trebuie să fie egal cu factorul de replicare. Nivelul de replicare este setat pentru fiecare keyspace și vă permite să ajustați redundanța datelor (redundanța datelor).


Înainte ca un nod să poată fi adăugat la cluster, trebuie să i se dea o etichetă. Procentul de chei care acoperă decalajul dintre această etichetă și următoarea determină câte date vor fi stocate pe nod. Întregul set de etichete pentru un cluster se numește inel.
Iată o ilustrare folosind utilitarul nodetool încorporat pentru a afișa un inel de cluster de 6 noduri cu etichete uniform distanțate.

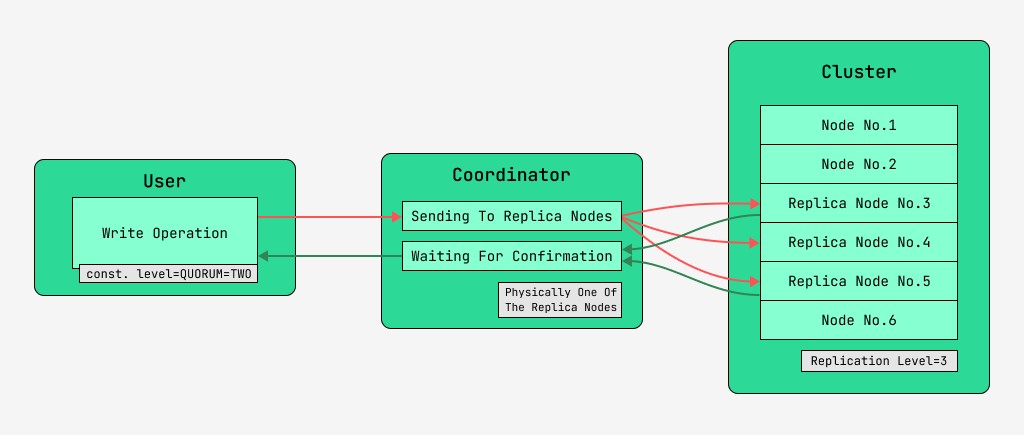
5.2 Consecvența datelor la scriere
Nodurile clusterului Cassandra sunt echivalente, iar clienții se pot conecta la oricare dintre ele, atât pentru scriere, cât și pentru citire. Cererile trec prin etapa de coordonare, timp în care, după ce a aflat cu ajutorul cheii și al marcajului pe care noduri ar trebui să fie localizate datele, serverul trimite cereri către aceste noduri. Vom numi nodul care realizează coordonarea coordonatorul , iar nodurile care sunt selectate pentru a salva înregistrarea cu cheia dată, nodurile replică . Din punct de vedere fizic, unul dintre nodurile replica poate fi coordonatorul - depinde doar de cheie, marcaj și etichete.
Pentru fiecare cerere, atât pentru citire, cât și pentru scriere, este posibil să se stabilească nivelul de consistență a datelor.
Pentru o scriere, acest nivel va afecta numărul de noduri replici care vor aștepta confirmarea finalizării cu succes a operațiunii (date scrise) înainte de a returna controlul utilizatorului. Pentru o înregistrare, există aceste niveluri de consistență:
- UNU - coordonatorul trimite cereri către toate nodurile replica, dar după ce așteaptă confirmarea de la primul nod, returnează controlul utilizatorului;
- DOUA - la fel, dar coordonatorul așteaptă confirmarea de la primele două noduri înainte de a reveni controlul;
- TREI - similar, dar coordonatorul așteaptă confirmarea de la primele trei noduri înainte de a reveni controlul;
- QUORUM - se strânge un cvorum: coordonatorul așteaptă confirmarea înregistrării de la mai mult de jumătate din nodurile replici, și anume rotund (N/2) + 1, unde N este nivelul de replicare;
- LOCAL_QUORUM - Coordonatorul așteaptă confirmarea de la mai mult de jumătate dintre nodurile replici din același centru de date în care se află coordonatorul (potențial diferit pentru fiecare cerere). Vă permite să scăpați de întârzierile asociate cu trimiterea datelor către alte centre de date. Problemele de lucru cu multe centre de date sunt luate în considerare în acest articol în trecere;
- EACH_QUORUM - Coordonatorul așteaptă confirmarea de la mai mult de jumătate din nodurile replici din fiecare centru de date, în mod independent;
- ALL - coordonatorul așteaptă confirmarea de la toate nodurile replica;
- ANY - face posibilă scrierea datelor, chiar dacă toate nodurile replica nu răspund. Coordonatorul așteaptă fie primul răspuns de la unul dintre nodurile replică, fie ca datele să fie stocate utilizând un transfer indicat pe coordonator.
5.3 Consecvența datelor la citire
Pentru citiri, nivelul de consistență va afecta numărul de noduri replici din care vor fi citite. Pentru citire, există aceste niveluri de consistență:
- ONE - coordonatorul trimite cereri la cel mai apropiat nod replica. Restul replicilor sunt citite și pentru reparație de citire cu probabilitatea specificată în configurația Cassandra;
- TWO este același, dar coordonatorul trimite cereri către cele mai apropiate două noduri. Este aleasă valoarea cu cea mai mare marcaj de timp;
- TREI - similar cu varianta anterioară, dar cu trei noduri;
- QUORUM - se adună un cvorum, adică coordonatorul trimite cereri către mai mult de jumătate din nodurile replici, și anume rotund (N/2) + 1, unde N este nivelul de replicare;
- LOCAL_QUORUM - se colectează un cvorum în centrul de date în care are loc coordonarea și se returnează datele cu cel mai recent marcaj de timp;
- EACH_QUORUM - Coordonatorul returnează date după întrunirea cvorumului în fiecare dintre centrele de date;
- ALL - Coordonatorul returnează date după citirea de la toate nodurile replica.

Astfel, este posibil să se ajusteze întârzierile operațiilor de citire și scriere și să se ajusteze consistența (consistența acordului), precum și disponibilitatea (disponibilitatea) fiecărui tip de operație. De fapt, disponibilitatea este direct legată de nivelul de consistență al citirilor și scrierilor, deoarece determină câte noduri de replică pot să cadă și totuși să fie confirmate.
Dacă numărul de noduri de la care provine confirmarea de scriere, plus numărul de noduri din care se face citirea, este mai mare decât nivelul de replicare, atunci avem garanția că noua valoare va fi întotdeauna citită după scriere și aceasta se numește consistență puternică (consistență puternică). În absența unei coerențe puternice, există posibilitatea ca o operație de citire să returneze date învechite.
În orice caz, valoarea se va propaga în cele din urmă între replici, dar numai după ce așteptarea de coordonare s-a încheiat. Această propagare se numește consistență eventuală. Dacă nu toate nodurile replici sunt disponibile în momentul scrierii, atunci mai devreme sau mai târziu instrumentele de recuperare, cum ar fi citirile de remediere și repararea nodurilor anti-entropie, vor intra în joc. Mai multe despre asta mai târziu.
Astfel, cu un nivel de consistență de citire și scriere QUORUM, o consistență puternică va fi întotdeauna menținută, iar acesta va fi un echilibru între latența de citire și scriere. Cu TOATE scrierile și ONE citirile va exista o consecvență puternică și citirile vor fi mai rapide și mai disponibile, adică numărul de noduri eșuate la care o citire va fi în continuare finalizată poate fi mai mare decât cu QUORUM.
Pentru operațiunile de scriere, vor fi necesare toate nodurile de lucru replica. La scrierea UNUI, citirea TOATE, va exista și o consecvență strictă, iar operațiunile de scriere vor fi mai rapide și disponibilitatea de scriere va fi mare, deoarece va fi suficient să se confirme doar că operația de scriere a avut loc pe cel puțin unul dintre servere, în timp ce citirea este mai lentă și necesită toate nodurile replica. Dacă o aplicație nu are o cerință de consistență strictă, atunci este posibil să se accelereze atât operațiunile de citire, cât și de scriere, precum și să se îmbunătățească disponibilitatea prin stabilirea unor niveluri de consistență mai scăzute.
GO TO FULL VERSION