5.1 數據分佈
讓我們考慮如何根據集群節點之間的鍵分佈數據。Cassandra 允許您設置數據分發策略。第一個這樣的策略根據 md5 鍵值分配數據 - 隨機分區程序。第二個考慮了密鑰本身的位表示 - 序號標記(字節順序分區程序)。
在大多數情況下,第一種策略具有更多優勢,因為您無需擔心服務器之間數據的均勻分佈等問題。第二種策略在極少數情況下使用,例如,如果需要間隔查詢(範圍掃描)。重要的是要注意,此策略的選擇是在創建集群之前做出的,事實上,如果不完全重新加載數據,就無法更改。
Cassandra 使用一種稱為一致性哈希的技術來分發數據。這種方法允許您在節點之間分發數據,並確保在添加和刪除新節點時,傳輸的數據量很小。為此,每個節點都分配了一個標籤(令牌),它將所有 md5 鍵值的集合分成幾部分。由於大多數情況下使用RandomPartitioner,所以我們考慮一下。
正如我所說,RandomPartitioner 為每個鍵計算一個 128 位的 md5。要確定數據將存儲在哪些節點中,它只需從小到大遍歷所有節點的標籤,當標籤的值變得大於 md5 鍵的值時,則該節點連同一個選擇存儲後續節點的數量(按標籤的順序)。所選節點的總數必須等於復制因子。為每個鍵空間設置複製級別,並允許您調整數據的冗餘(數據冗餘)。


在一個節點可以被添加到集群之前,它必須被賦予一個標籤。覆蓋此標籤和下一個標籤之間的間隙的鍵的百分比決定了將在節點上存儲多少數據。集群的整個標籤集稱為環。
下面是使用內置 nodetool 實用程序顯示 6 個節點的群集環的插圖,這些節點具有均勻間隔的標籤。

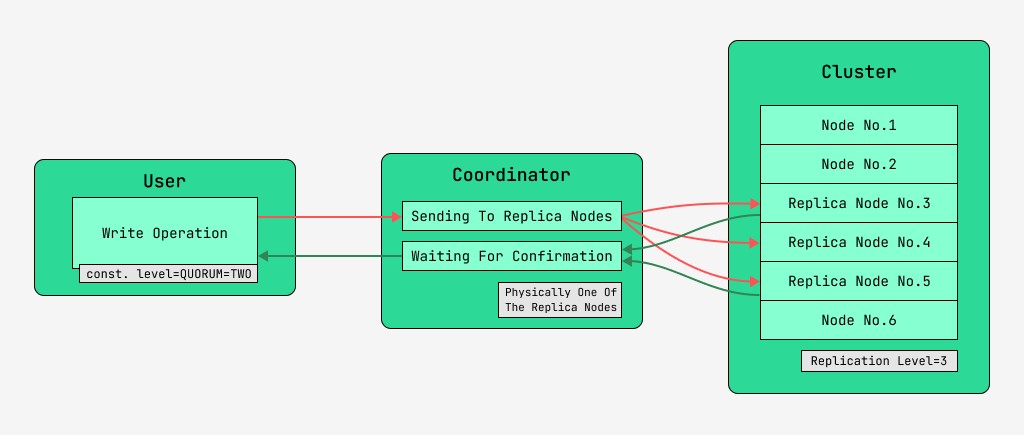
5.2 寫入時的數據一致性
Cassandra 集群節點是等價的,客戶端可以連接到其中任何一個,既可以寫入也可以讀取。請求經過協調階段,在此期間,服務器借助鍵和標記找出數據應位於哪些節點上,然後向這些節點發送請求。我們將執行協調的節點稱為coordinator,將被選中以使用給定鍵保存記錄的節點稱為副本節點。從物理上講,其中一個副本節點可以是協調器——它僅取決於鍵、標記和標籤。
對於每個讀取和寫入請求,都可以設置數據一致性級別。
對於寫入,此級別將影響在將控制權返回給用戶之前等待確認操作(寫入的數據)成功完成的副本節點的數量。作為記錄,有以下一致性級別:
- ONE——協調器向所有副本節點發送請求,但在等待第一個節點的確認後,將控制權返回給用戶;
- TWO - 相同,但協調器在返回控制之前等待前兩個節點的確認;
- 三- 類似,但協調器在返回控制之前等待前三個節點的確認;
- QUORUM - 收集了一個法定人數:協調者正在等待來自超過一半的副本節點的記錄確認,即第(N / 2)+ 1輪,其中N是複制級別;
- LOCAL_QUORUM - 協調器正在等待協調器所在的同一數據中心中超過一半的副本節點的確認(每個請求可能不同)。允許您擺脫與將數據發送到其他數據中心相關的延遲。本文順便考慮了與多個數據中心合作的問題;
- EACH_QUORUM - 協調器獨立地等待每個數據中心中超過一半的副本節點的確認;
- ALL - 協調器等待所有副本節點的確認;
- ANY - 即使所有副本節點都沒有響應,也可以寫入數據。協調器等待來自其中一個副本節點的第一個響應,或者等待使用協調器上的暗示切換來存儲數據。
5.3 讀取數據一致性
對於讀取,一致性級別將影響將從中讀取的副本節點的數量。對於閱讀,有以下一致性級別:
- ONE - 協調器將請求發送到最近的副本節點。其余副本也以cassandra配置中指定的概率進行讀取修復;
- TWO是一樣的,但是協調器向最近的兩個節點發送請求。選擇具有最大時間戳的值;
- 三- 與之前的選項類似,但具有三個節點;
- QUORUM——收集一個quorum,即協調器向超過一半的副本節點發送請求,即round (N / 2) + 1,其中N為複制級別;
- LOCAL_QUORUM - 在發生協調的數據中心收集一個法定人數,並返回具有最新時間戳的數據;
- EACH_QUORUM - 協調器在每個數據中心的法定人數會議後返回數據;
- ALL - 協調器從所有副本節點讀取後返回數據。

因此,可以調整讀寫操作的時間延遲和調整一致性(tune consistency),以及每種操作的可用性(availability)。事實上,可用性與讀寫的一致性水平直接相關,因為它決定了有多少副本節點可以下降並仍然得到確認。
如果寫入確認來自的節點數加上進行讀取的節點數大於復制級別,那麼我們可以保證在寫入後始終讀取新值,並且這稱為強一致性(strong consistency)。在沒有強一致性的情況下,讀取操作可能會返回陳舊的數據。
在任何情況下,該值最終都會在副本之間傳播,但只有在協調等待結束後才會傳播。這種傳播稱為最終一致性。如果在寫入時並非所有副本節點都可用,那麼遲早會使用補救讀取和反熵節點修復等恢復工具。稍後會詳細介紹。
這樣,有了QUORUM讀寫一致性級別,就會一直保持強一致性,這就是讀寫延遲的平衡。使用 ALL 寫入和 ONE 讀取將具有很強的一致性,並且讀取將更快且更可用,即仍然可以完成讀取的故障節點數量可能大於 QUORUM。
對於寫入操作,將需要所有副本工作節點。當寫ONE,讀ALL時,也會有嚴格的一致性,寫操作會更快,寫可用性會大,因為只確認寫操作發生在至少一台服務器上就足夠了,而讀取速度較慢並且需要所有副本節點。如果應用程序沒有嚴格的一致性要求,那麼可以通過設置較低的一致性級別來加快讀寫操作,並提高可用性。
GO TO FULL VERSION