5.1 Dystrybucja danych
Rozważmy, w jaki sposób dane są dystrybuowane w zależności od klucza między węzłami klastra. Cassandra umożliwia ustawienie strategii dystrybucji danych. Pierwsza taka strategia dystrybuuje dane w zależności od wartości klucza md5 - losowego partycjonera. Drugi bierze pod uwagę bitową reprezentację samego klucza - znacznik porządkowy (partycjoner uporządkowany bajtowo).
Pierwsza strategia w większości daje więcej korzyści, ponieważ nie trzeba się martwić o równomierne rozłożenie danych między serwerami i tego typu problemy. Druga strategia jest używana w rzadkich przypadkach, na przykład, gdy potrzebne są zapytania interwałowe (skanowanie zakresu). Należy zauważyć, że wybór tej strategii jest dokonywany przed utworzeniem klastra iw rzeczywistości nie można go zmienić bez całkowitego przeładowania danych.
Cassandra używa techniki znanej jako spójne haszowanie do dystrybucji danych. Takie podejście pozwala na dystrybucję danych między węzłami i upewnienie się, że przy dodawaniu i usuwaniu nowego węzła ilość przesyłanych danych jest niewielka. W tym celu każdemu węzłowi przypisywana jest etykieta (token), która dzieli zbiór wszystkich wartości klucza md5 na części. Ponieważ RandomPartitioner jest używany w większości przypadków, rozważmy to.
Jak powiedziałem, RandomPartitioner oblicza 128-bitowy md5 dla każdego klucza. Aby określić, w których węzłach będą przechowywane dane, po prostu przechodzi przez wszystkie etykiety węzłów od najmniejszego do największego, a gdy wartość etykiety staje się większa niż wartość klucza md5, to ten węzeł wraz z liczba kolejnych węzłów (w kolejności etykiet) jest wybierana do przechowywania. Całkowita liczba wybranych węzłów musi być równa współczynnikowi replikacji. Poziom replikacji jest ustawiany dla każdej przestrzeni klucza i umożliwia dostosowanie redundancji danych (nadmiarowość danych).


Zanim węzeł zostanie dodany do klastra, musi otrzymać etykietę. Procent kluczy, które pokrywają lukę między tą etykietą a następną, określa, ile danych będzie przechowywanych w węźle. Cały zestaw etykiet klastra nazywany jest pierścieniem.
Oto ilustracja wykorzystująca wbudowane narzędzie nodetool do wyświetlenia pierścienia klastra składającego się z 6 węzłów z równomiernie rozmieszczonymi etykietami.

5.2 Spójność danych podczas pisania
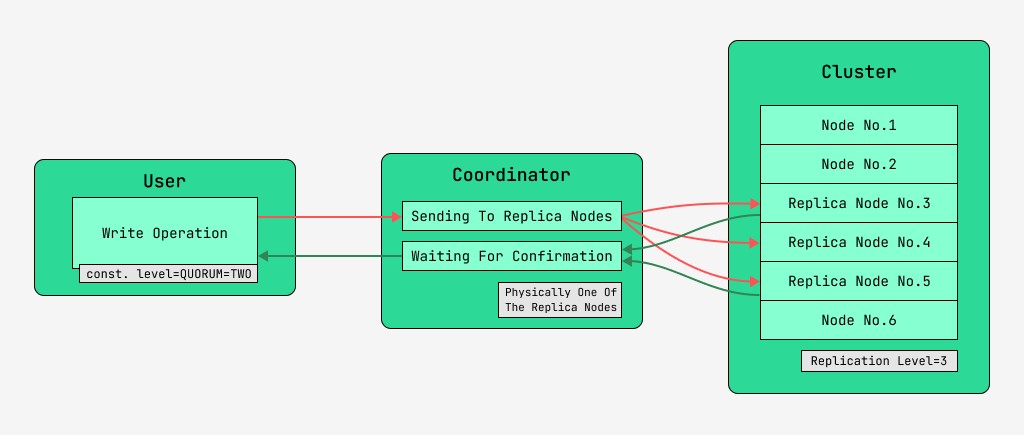
Węzły klastra Cassandra są równoważne, a klienci mogą łączyć się z dowolnymi z nich, zarówno w celu zapisu, jak i odczytu. Żądania przechodzą przez etap koordynacji, podczas którego po ustaleniu za pomocą klucza i znaczników, na których węzłach powinny znajdować się dane, serwer wysyła żądania do tych węzłów. Węzeł, który wykonuje koordynację, będziemy nazywać koordynatorem , a węzły wybrane do zapisania rekordu z danym kluczem - węzłami replik . Fizycznie jeden z węzłów repliki może być koordynatorem - zależy to tylko od klucza, znaczników i etykiet.
Dla każdego żądania, zarówno do odczytu, jak i zapisu, istnieje możliwość ustawienia poziomu spójności danych.
W przypadku zapisu poziom ten wpłynie na liczbę węzłów replik, które będą czekać na potwierdzenie pomyślnego zakończenia operacji (zapisu danych) przed zwróceniem kontroli użytkownikowi. Dla przypomnienia, istnieją następujące poziomy spójności:
- JEDEN - koordynator wysyła żądania do wszystkich węzłów repliki, ale po odczekaniu na potwierdzenie z pierwszego węzła zwraca kontrolę użytkownikowi;
- DWA – to samo, ale koordynator czeka na potwierdzenie z dwóch pierwszych węzłów przed zwróceniem sterowania;
- THREE – podobnie, ale koordynator czeka na potwierdzenie z pierwszych trzech węzłów przed zwróceniem sterowania;
- Quorum – zebrane kworum: koordynator oczekuje na potwierdzenie zapisu z ponad połowy węzłów replik, czyli rundy (N/2)+1, gdzie N to poziom replikacji;
- LOCAL_QUORUM — Koordynator czeka na potwierdzenie z ponad połowy węzłów replik w tym samym centrum danych, w którym znajduje się koordynator (potencjalnie różne dla każdego żądania). Pozwala pozbyć się opóźnień związanych z przesyłaniem danych do innych centrów danych. Kwestie pracy z wieloma centrami danych omówiono w tym artykule mimochodem;
- EACH_QUORUM — Koordynator czeka na potwierdzenie z ponad połowy węzłów replik w każdym centrum danych, niezależnie;
- ALL - koordynator oczekuje na potwierdzenie ze wszystkich węzłów repliki;
- DOWOLNY - umożliwia zapis danych, nawet jeśli wszystkie węzły repliki nie odpowiadają. Koordynator czeka albo na pierwszą odpowiedź z jednego z węzłów repliki, albo na przechowywanie danych za pomocą wskazywanego przekazania na koordynatorze.
5.3 Spójność danych podczas odczytu
W przypadku odczytów poziom spójności wpłynie na liczbę węzłów replik, z których będą odczytywane. Do czytania dostępne są następujące poziomy spójności:
- JEDEN - koordynator wysyła żądania do najbliższego węzła repliki. Reszta replik jest również odczytywana w celu naprawy odczytu z prawdopodobieństwem określonym w konfiguracji kasandry;
- TWO to to samo, ale koordynator wysyła żądania do dwóch najbliższych węzłów. Wybierana jest wartość z największą sygnaturą czasową;
- TRZY - podobnie jak poprzednia opcja, ale z trzema węzłami;
- Quorum – zebrane kworum, czyli koordynator wysyła żądania do ponad połowy węzłów repliki, czyli runda (N/2) + 1, gdzie N to poziom replikacji;
- LOCAL_QUORUM – gromadzone jest kworum w data center, w którym odbywa się koordynacja i zwracane są dane z najnowszym znacznikiem czasu;
- EACH_QUORUM - Koordynator zwraca dane po zebraniu kworum w każdym z centrów danych;
- ALL - Koordynator zwraca dane po odczycie ze wszystkich węzłów repliki.

Dzięki temu możliwe jest dostosowanie opóźnień czasowych operacji odczytu i zapisu oraz dostosowanie spójności (spójności strojenia), a także dostępności (dostępności) każdego typu operacji. W rzeczywistości dostępność jest bezpośrednio związana z poziomem spójności odczytów i zapisów, ponieważ określa, ile węzłów repliki może zostać wyłączonych i nadal być potwierdzonych.
Jeżeli liczba węzłów, z których pochodzi potwierdzenie zapisu, plus liczba węzłów, z których wykonywany jest odczyt, jest większa niż poziom replikacji, to mamy gwarancję, że po zapisie zawsze zostanie odczytana nowa wartość, a to nazywa się silną konsystencją (silną konsystencją). W przypadku braku silnej spójności istnieje możliwość, że operacja odczytu zwróci nieaktualne dane.
W każdym przypadku wartość będzie ostatecznie propagowana między replikami, ale dopiero po zakończeniu oczekiwania na koordynację. Ta propagacja nazywana jest konsystencją ostateczną. Jeśli nie wszystkie węzły repliki są dostępne w momencie zapisu, prędzej czy później w grę wejdą narzędzia odzyskiwania, takie jak odczyty naprawcze i naprawa węzłów anty-entropii. Więcej na ten temat później.
Tak więc przy poziomie spójności odczytu i zapisu KWORUM silna spójność będzie zawsze utrzymywana, co zapewni równowagę między opóźnieniem odczytu i zapisu. Przy WSZYSTKICH zapisach i JEDNYM odczycie zapewniona zostanie duża spójność, a odczyty będą szybsze i bardziej dostępne, tj.
W przypadku operacji zapisu wymagane będą wszystkie węzły procesu roboczego repliki. Przy zapisie JEDEN, odczyt WSZYSTKICH też będzie zachowana ścisła spójność, a operacje zapisu będą szybsze a dostępność zapisu duża, bo wystarczy tylko potwierdzić, że operacja zapisu miała miejsce na przynajmniej jednym z serwerów, natomiast odczyt jest wolniejszy i wymaga wszystkich węzłów repliki. Jeśli aplikacja nie ma wymogu ścisłej spójności, to możliwe jest przyspieszenie operacji odczytu i zapisu, a także poprawienie dostępności poprzez ustawienie niższych poziomów spójności.
GO TO FULL VERSION