5.1 数据分布
让我们考虑如何根据集群节点之间的键分布数据。Cassandra 允许您设置数据分发策略。第一个这样的策略根据 md5 键值分配数据 - 随机分区程序。第二个考虑了密钥本身的位表示 - 序号标记(字节顺序分区程序)。
在大多数情况下,第一种策略具有更多优势,因为您无需担心服务器之间数据的均匀分布等问题。第二种策略在极少数情况下使用,例如,如果需要间隔查询(范围扫描)。重要的是要注意,此策略的选择是在创建集群之前做出的,实际上如果不完全重新加载数据就无法更改。
Cassandra 使用一种称为一致性哈希的技术来分发数据。这种方法允许您在节点之间分发数据,并确保在添加和删除新节点时,传输的数据量很小。为此,每个节点都分配了一个标签(令牌),它将所有 md5 键值的集合分成几部分。由于大多数情况下使用RandomPartitioner,所以我们考虑一下。
正如我所说,RandomPartitioner 为每个键计算一个 128 位的 md5。要确定数据将存储在哪些节点中,它只需从小到大遍历所有节点的标签,当标签的值变得大于 md5 键的值时,则该节点连同一个选择存储后续节点的数量(按标签的顺序)。所选节点的总数必须等于复制因子。为每个键空间设置复制级别,并允许您调整数据的冗余(数据冗余)。


在一个节点可以被添加到集群之前,它必须被赋予一个标签。覆盖此标签和下一个标签之间的间隙的键的百分比决定了将在节点上存储多少数据。集群的整个标签集称为环。
下面是使用内置 nodetool 实用程序显示 6 个节点的群集环的插图,这些节点具有均匀间隔的标签。

5.2 写入时的数据一致性
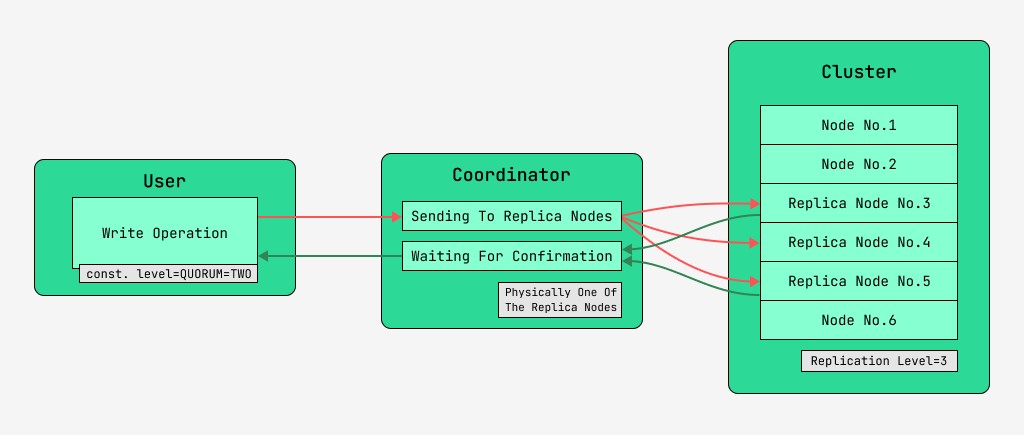
Cassandra 集群节点是等价的,客户端可以连接到其中任何一个,既可以写入也可以读取。请求经过协调阶段,在此期间,服务器借助键和标记找出数据应位于哪些节点上,然后向这些节点发送请求。我们将执行协调的节点称为coordinator,将被选中以使用给定键保存记录的节点称为副本节点。从物理上讲,其中一个副本节点可以是协调器——它仅取决于键、标记和标签。
对于每个读取和写入请求,都可以设置数据一致性级别。
对于写入,此级别将影响在将控制权返回给用户之前等待确认操作(写入的数据)成功完成的副本节点的数量。作为记录,有以下一致性级别:
- ONE——协调器向所有副本节点发送请求,但在等待第一个节点的确认后,将控制权返回给用户;
- TWO - 相同,但协调器在返回控制之前等待前两个节点的确认;
- 三- 类似,但协调器在返回控制之前等待前三个节点的确认;
- QUORUM - 收集了一个法定人数:协调者正在等待来自超过一半的副本节点的记录确认,即第(N / 2)+ 1轮,其中N是复制级别;
- LOCAL_QUORUM - 协调器正在等待协调器所在的同一数据中心中超过一半的副本节点的确认(每个请求可能不同)。允许您摆脱与将数据发送到其他数据中心相关的延迟。本文顺便考虑了与多个数据中心合作的问题;
- EACH_QUORUM - 协调器独立地等待来自每个数据中心中超过一半的副本节点的确认;
- ALL - 协调器等待所有副本节点的确认;
- ANY - 即使所有副本节点都没有响应,也可以写入数据。协调器等待来自其中一个副本节点的第一个响应,或者等待使用协调器上的暗示切换来存储数据。
5.3 读取数据一致性
对于读取,一致性级别将影响将从中读取的副本节点的数量。对于阅读,有以下一致性级别:
- ONE - 协调器将请求发送到最近的副本节点。其余副本也以cassandra配置中指定的概率进行读取修复;
- TWO是一样的,但是协调器向最近的两个节点发送请求。选择具有最大时间戳的值;
- 三- 与之前的选项类似,但具有三个节点;
- QUORUM——收集一个quorum,即协调器向超过一半的副本节点发送请求,即round (N / 2) + 1,其中N为复制级别;
- LOCAL_QUORUM - 在发生协调的数据中心收集一个法定人数,并返回具有最新时间戳的数据;
- EACH_QUORUM - 协调器在每个数据中心达到法定人数后返回数据;
- ALL - 协调器从所有副本节点读取后返回数据。

因此,可以调整读写操作的时间延迟和调整一致性(tune consistency),以及每种操作的可用性(availability)。事实上,可用性与读写的一致性水平直接相关,因为它决定了有多少副本节点可以下降并仍然得到确认。
如果写入确认来自的节点数加上进行读取的节点数大于复制级别,那么我们就可以保证在写入后始终读取新值,并且这称为强一致性(strong consistency)。在没有强一致性的情况下,读取操作可能会返回陈旧的数据。
在任何情况下,该值最终都会在副本之间传播,但只有在协调等待结束后才会传播。这种传播称为最终一致性。如果在写入时并非所有副本节点都可用,那么迟早会使用补救读取和反熵节点修复等恢复工具。稍后会详细介绍。
这样,有了QUORUM读写一致性级别,就会一直保持强一致性,这就是读写延迟的平衡。使用 ALL 写入和 ONE 读取将具有很强的一致性,并且读取将更快且更可用,即仍然可以完成读取的故障节点数量可能大于 QUORUM。
对于写入操作,将需要所有副本工作节点。当写ONE,读ALL时,也会有严格的一致性,写操作会更快,写可用性会大,因为只确认写操作发生在至少一台服务器上就足够了,而读取速度较慢并且需要所有副本节点。如果应用程序没有严格的一致性要求,那么可以通过设置较低的一致性级别来加快读写操作,并提高可用性。
GO TO FULL VERSION