5.1 Pamamahagi ng datos
Isaalang-alang natin kung paano ipinamamahagi ang data depende sa susi sa mga cluster node. Pinapayagan ka ni Cassandra na magtakda ng diskarte sa pamamahagi ng data. Ang unang ganoong diskarte ay namamahagi ng data depende sa md5 key value - isang random na partitioner. Ang pangalawa ay isinasaalang-alang ang bit na representasyon ng susi mismo - ang ordinal markup (byte-ordered partitioner).
Ang unang diskarte, para sa karamihan, ay nagbibigay ng higit pang mga pakinabang, dahil hindi mo kailangang mag-alala tungkol sa kahit na pamamahagi ng data sa pagitan ng mga server at tulad ng mga problema. Ang pangalawang diskarte ay ginagamit sa mga bihirang kaso, halimbawa, kung ang mga query sa pagitan (range scan) ay kailangan. Mahalagang tandaan na ang pagpili ng diskarteng ito ay ginawa bago ang paglikha ng cluster at sa katunayan ay hindi mababago nang walang kumpletong pag-reload ng data.
Gumagamit si Cassandra ng pamamaraan na kilala bilang pare-parehong pag-hash upang mamahagi ng data. Binibigyang-daan ka ng diskarteng ito na ipamahagi ang data sa pagitan ng mga node at tiyaking kapag ang isang bagong node ay idinagdag at inalis, ang halaga ng data na inilipat ay maliit. Upang gawin ito, ang bawat node ay itinalaga ng isang label (token), na naghahati sa hanay ng lahat ng md5 key values sa mga bahagi. Dahil ang RandomPartitioner ay ginagamit sa karamihan ng mga kaso, isaalang-alang natin ito.
Tulad ng sinabi ko, kinakalkula ng RandomPartitioner ang isang 128-bit md5 para sa bawat key. Upang matukoy kung aling mga node ang data ay iimbak, dadaan lang ito sa lahat ng mga label ng mga node mula sa pinakamaliit hanggang sa pinakamalaki, at kapag ang halaga ng label ay naging mas malaki kaysa sa halaga ng md5 key, pagkatapos ay ang node na ito, kasama ng isang ang bilang ng mga kasunod na node (sa pagkakasunud-sunod ng mga label) ay pinili para sa imbakan. Ang kabuuang bilang ng mga napiling node ay dapat na katumbas ng replication factor. Ang antas ng pagtitiklop ay nakatakda para sa bawat keyspace at nagbibigay-daan sa iyong isaayos ang redundancy ng data (data redundancy).


Bago maidagdag ang isang node sa cluster, dapat itong bigyan ng label. Ang porsyento ng mga key na sumasaklaw sa agwat sa pagitan ng label na ito at ng susunod ay tumutukoy kung gaano karaming data ang maiimbak sa node. Ang buong hanay ng mga label para sa isang kumpol ay tinatawag na singsing.
Narito ang isang ilustrasyon gamit ang built-in na nodetool utility upang magpakita ng cluster ring ng 6 na node na may mga label na pantay-pantay ang pagitan.

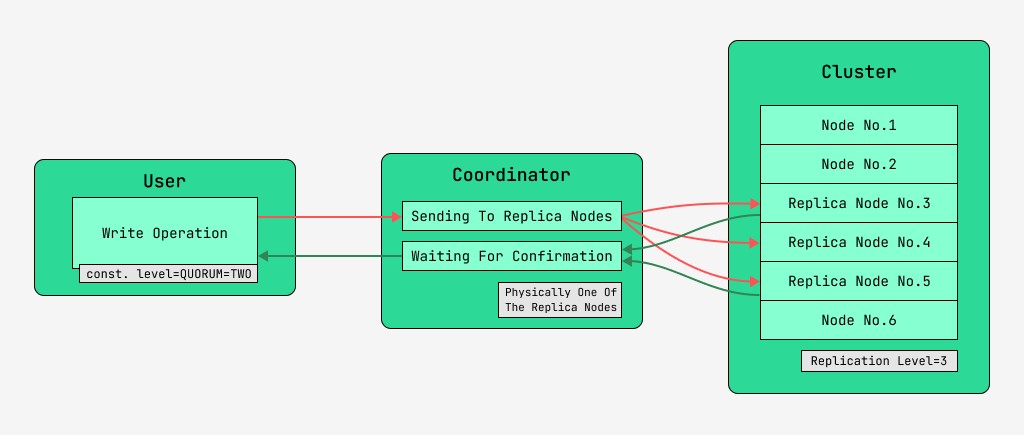
5.2 Consistency ng data kapag nagsusulat
Ang mga node ng kumpol ng Cassandra ay katumbas, at maaaring kumonekta ang mga kliyente sa alinman sa mga ito, kapwa para sa pagsusulat at para sa pagbabasa. Ang mga kahilingan ay dumaan sa yugto ng koordinasyon, kung saan, nang nalaman sa tulong ng susi at ang markup kung saan ang mga node ay dapat na matatagpuan, ang server ay nagpapadala ng mga kahilingan sa mga node na ito. Tatawagin namin ang node na nagsasagawa ng koordinasyon na coordinator , at ang mga node na pinili upang i-save ang record gamit ang ibinigay na key, ang mga replica node. Sa pisikal, ang isa sa mga replica node ay maaaring maging coordinator - depende lang ito sa susi, markup, at mga label.
Para sa bawat kahilingan, kapwa para sa pagbabasa at pagsulat, posibleng itakda ang antas ng pagkakapare-pareho ng data.
Para sa isang pagsulat, ang antas na ito ay makakaapekto sa bilang ng mga replica node na maghihintay para sa kumpirmasyon ng matagumpay na pagkumpleto ng operasyon (nakasulat na data) bago ibalik ang kontrol sa user. Para sa isang tala, mayroong mga antas ng pagkakapare-pareho:
- ONE - ang coordinator ay nagpapadala ng mga kahilingan sa lahat ng mga replica node, ngunit pagkatapos maghintay ng kumpirmasyon mula sa unang node, ibabalik ang kontrol sa user;
- DALAWA - pareho, ngunit ang coordinator ay naghihintay para sa kumpirmasyon mula sa unang dalawang node bago ibalik ang kontrol;
- TATLO - katulad, ngunit ang coordinator ay naghihintay ng kumpirmasyon mula sa unang tatlong node bago ibalik ang kontrol;
- QUORUM - isang korum ay nakolekta: ang coordinator ay naghihintay para sa kumpirmasyon ng talaan mula sa higit sa kalahati ng mga replica node, lalo na round (N / 2) + 1, kung saan ang N ay ang antas ng pagtitiklop;
- LOCAL_QUORUM - Ang coordinator ay naghihintay ng kumpirmasyon mula sa higit sa kalahati ng mga replica node sa parehong data center kung saan matatagpuan ang coordinator (maaaring magkaiba para sa bawat kahilingan). Binibigyang-daan kang alisin ang mga pagkaantala na nauugnay sa pagpapadala ng data sa iba pang mga data center. Ang mga isyu ng pakikipagtulungan sa maraming data center ay isinasaalang-alang sa artikulong ito sa pagpasa;
- EACH_QUORUM - Ang coordinator ay naghihintay ng kumpirmasyon mula sa higit sa kalahati ng mga replica node sa bawat data center, nang nakapag-iisa;
- LAHAT - ang coordinator ay naghihintay para sa kumpirmasyon mula sa lahat ng mga replica node;
- ANUMANG - ginagawang posible na magsulat ng data, kahit na ang lahat ng mga replica node ay hindi tumutugon. Ang coordinator ay naghihintay ng alinman sa unang tugon mula sa isa sa mga replica node, o para sa data na maiimbak gamit ang hinted handoff sa coordinator.
5.3 Consistency ng data kapag nagbabasa
Para sa mga pagbabasa, ang antas ng pagkakapare-pareho ay makakaapekto sa bilang ng mga replica node na babasahin. Para sa pagbabasa, mayroong mga antas ng pagkakapare-pareho:
- ONE - nagpapadala ang coordinator ng mga kahilingan sa pinakamalapit na replica node. Ang iba pang mga replika ay binabasa din para sa read repair na may probabilidad na tinukoy sa configuration ng cassandra;
- Ang DALAWA ay pareho, ngunit ang coordinator ay nagpapadala ng mga kahilingan sa dalawang pinakamalapit na node. Ang halaga na may pinakamalaking timestamp ay pinili;
- TATLO - katulad ng nakaraang opsyon, ngunit may tatlong node;
- QUORUM - isang korum ay nakolekta, iyon ay, ang coordinator ay nagpapadala ng mga kahilingan sa higit sa kalahati ng mga replica node, lalo na round (N / 2) + 1, kung saan ang N ay ang antas ng pagtitiklop;
- LOCAL_QUORUM - isang korum ang kinokolekta sa data center kung saan nagaganap ang koordinasyon, at ang data na may pinakabagong timestamp ay ibinalik;
- EACH_QUORUM - Ang coordinator ay nagbabalik ng data pagkatapos ng pulong ng korum sa bawat isa sa mga data center;
- LAHAT - Ang coordinator ay nagbabalik ng data pagkatapos basahin mula sa lahat ng mga replica node.

Kaya, posible na ayusin ang mga pagkaantala sa oras ng mga operasyon sa pagbasa at pagsulat at ayusin ang pagkakapare-pareho (tune consistency), pati na rin ang availability (availability) ng bawat uri ng operasyon. Sa katunayan, ang kakayahang magamit ay direktang nauugnay sa antas ng pagkakapare-pareho ng mga pagbabasa at pagsusulat, dahil tinutukoy nito kung gaano karaming mga replica node ang maaaring bumaba at makumpirma pa rin.
Kung ang bilang ng mga node kung saan nagmumula ang write acknowledgement, kasama ang bilang ng mga node kung saan ginawa ang read, ay mas malaki kaysa sa replication level, kung gayon mayroon kaming garantiya na ang bagong value ay palaging babasahin pagkatapos ng pagsulat, at ito ay tinatawag na strong consistency (strong consistency). Sa kawalan ng malakas na pagkakapare-pareho, may posibilidad na ang isang read operation ay magbabalik ng lipas na data.
Sa anumang kaso, ang halaga ay sa kalaunan ay magpapalaganap sa pagitan ng mga replika, ngunit pagkatapos lamang matapos ang paghihintay sa koordinasyon. Ang pagpapalaganap na ito ay tinatawag na eventual consistency. Kung hindi lahat ng mga replica node ay magagamit sa oras ng pagsulat, pagkatapos ay maaga o huli ang mga tool sa pagbawi tulad ng remedial reads at anti-entropy node repair ay papasok. Higit pa tungkol dito mamaya.
Kaya, sa antas ng pagkakapare-pareho ng pagbasa at pagsulat ng QUORUM, palaging mapapanatili ang matatag na pagkakapare-pareho, at ito ay magiging balanse sa pagitan ng latency ng pagbasa at pagsulat. Sa LAHAT ng pagsusulat at ISANG pagbabasa magkakaroon ng malakas na pagkakapare-pareho at ang mga pagbabasa ay magiging mas mabilis at mas magagamit, ibig sabihin, ang bilang ng mga nabigong node kung saan ang isang pagbabasa ay makukumpleto pa rin ay maaaring mas malaki kaysa sa QUORUM.
Para sa mga write operation, kakailanganin ang lahat ng replica worker node. Kapag nagsusulat ng ISA, binabasa ang LAHAT, magkakaroon din ng mahigpit na pagkakapare-pareho, at magiging mas mabilis ang mga operasyon sa pagsulat at magiging malaki ang availability ng pagsulat, dahil sapat na ito upang kumpirmahin lamang na ang operasyon ng pagsulat ay naganap sa hindi bababa sa isa sa mga server, habang Ang pagbabasa ay mas mabagal at nangangailangan ng lahat ng mga replica node. Kung ang isang application ay walang kinakailangan para sa mahigpit na pagkakapare-pareho, posible na pabilisin ang parehong mga operasyon sa pagbasa at pagsulat, pati na rin pagbutihin ang kakayahang magamit sa pamamagitan ng pagtatakda ng mas mababang mga antas ng pagkakapare-pareho.
GO TO FULL VERSION