5.1 Distribusi data
Mari pertimbangkan bagaimana data didistribusikan tergantung pada kunci di antara node cluster. Cassandra memungkinkan Anda mengatur strategi distribusi data. Strategi pertama mendistribusikan data tergantung pada nilai kunci md5 - partisi acak. Yang kedua memperhitungkan representasi bit dari kunci itu sendiri - markup ordinal (partisi yang dipesan byte).
Strategi pertama, sebagian besar, memberikan lebih banyak keuntungan, karena Anda tidak perlu khawatir tentang pemerataan data antar server dan masalah semacam itu. Strategi kedua digunakan dalam kasus yang jarang terjadi, misalnya, jika permintaan interval (pemindaian rentang) diperlukan. Penting untuk dicatat bahwa pilihan strategi ini dibuat sebelum pembuatan cluster dan pada kenyataannya tidak dapat diubah tanpa memuat ulang data secara lengkap.
Cassandra menggunakan teknik yang dikenal sebagai hashing yang konsisten untuk mendistribusikan data. Pendekatan ini memungkinkan Anda untuk mendistribusikan data antar node dan memastikan bahwa ketika node baru ditambahkan dan dihapus, jumlah data yang ditransfer kecil. Untuk melakukan ini, setiap node diberi label (token), yang membagi set semua nilai kunci md5 menjadi beberapa bagian. Karena RandomPartitioner digunakan dalam banyak kasus, mari kita pertimbangkan.
Seperti yang saya katakan, RandomPartitioner menghitung md5 128-bit untuk setiap kunci. Untuk menentukan di node mana data akan disimpan, itu hanya melewati semua label node dari yang terkecil hingga terbesar, dan ketika nilai label menjadi lebih besar dari nilai kunci md5, maka node ini, bersama dengan a jumlah node berikutnya (dalam urutan label) dipilih untuk penyimpanan. Jumlah total node yang dipilih harus sama dengan faktor replikasi. Tingkat replikasi diatur untuk setiap ruang kunci dan memungkinkan Anda menyesuaikan redundansi data (redundansi data).


Sebelum node dapat ditambahkan ke cluster, harus diberi label. Persentase kunci yang menutupi celah antara label ini dan label berikutnya menentukan berapa banyak data yang akan disimpan di node. Seluruh set label untuk sebuah cluster disebut ring.
Berikut adalah ilustrasi menggunakan utilitas nodetool bawaan untuk menampilkan cincin cluster dari 6 node dengan label dengan jarak yang sama.

5.2 Konsistensi data saat penulisan
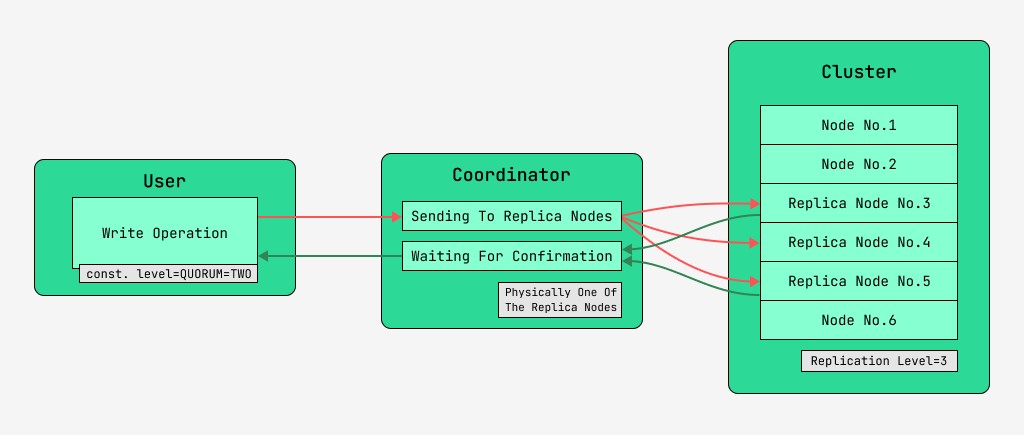
Node cluster Cassandra setara, dan klien dapat terhubung ke salah satunya, baik untuk menulis maupun membaca. Permintaan melewati tahap koordinasi, di mana, setelah mengetahui dengan bantuan kunci dan markup di mana node data harus ditempatkan, server mengirimkan permintaan ke node ini. Kita akan memanggil node yang melakukan koordinasi sebagai coordinator , dan node yang dipilih untuk menyimpan record dengan kunci yang diberikan, node replika . Secara fisik, salah satu simpul replika dapat menjadi koordinator - hanya bergantung pada kunci, markup, dan label.
Untuk setiap permintaan, baik untuk membaca maupun menulis, dimungkinkan untuk mengatur tingkat konsistensi data.
Untuk penulisan, level ini akan memengaruhi jumlah node replika yang akan menunggu konfirmasi keberhasilan penyelesaian operasi (data tertulis) sebelum mengembalikan kontrol ke pengguna. Sebagai catatan, ada tingkat konsistensi ini:
- SATU - koordinator mengirimkan permintaan ke semua node replika, tetapi setelah menunggu konfirmasi dari node pertama, mengembalikan kontrol ke pengguna;
- DUA - sama, tetapi koordinator menunggu konfirmasi dari dua node pertama sebelum mengembalikan kontrol;
- TIGA - serupa, tetapi koordinator menunggu konfirmasi dari tiga node pertama sebelum mengembalikan kontrol;
- KUORUM - kuorum dikumpulkan: koordinator sedang menunggu konfirmasi catatan dari lebih dari setengah node replika, yaitu putaran (N / 2) + 1, di mana N adalah tingkat replikasi;
- LOCAL_QUORUM - Koordinator sedang menunggu konfirmasi dari lebih dari setengah node replika di pusat data yang sama tempat koordinator berada (berpotensi berbeda untuk setiap permintaan). Memungkinkan Anda menghilangkan penundaan yang terkait dengan pengiriman data ke pusat data lain. Masalah bekerja dengan banyak pusat data dibahas dalam artikel ini secara sepintas;
- EACH_QUORUM - Koordinator sedang menunggu konfirmasi dari lebih dari setengah node replika di setiap pusat data, secara mandiri;
- ALL - koordinator menunggu konfirmasi dari semua node replika;
- APAPUN - memungkinkan untuk menulis data, meskipun semua node replika tidak merespons. Koordinator menunggu respons pertama dari salah satu node replika, atau data disimpan menggunakan handoff yang diisyaratkan pada koordinator.
5.3 Konsistensi data saat membaca
Untuk pembacaan, tingkat konsistensi akan memengaruhi jumlah simpul replika yang akan dibaca. Untuk membaca, ada tingkat konsistensi berikut:
- SATU - koordinator mengirimkan permintaan ke node replika terdekat. Replika lainnya juga dibaca untuk perbaikan baca dengan probabilitas yang ditentukan dalam konfigurasi cassandra;
- DUA sama, tetapi koordinator mengirimkan permintaan ke dua node terdekat. Nilai dengan stempel waktu terbesar dipilih;
- TIGA - mirip dengan opsi sebelumnya, tetapi dengan tiga node;
- KUORUM - kuorum dikumpulkan, yaitu koordinator mengirimkan permintaan ke lebih dari setengah node replika, yaitu putaran (N / 2) + 1, di mana N adalah tingkat replikasi;
- LOCAL_QUORUM - kuorum dikumpulkan di pusat data tempat koordinasi berlangsung, dan data dengan stempel waktu terakhir dikembalikan;
- EACH_QUORUM - Koordinator mengembalikan data setelah pertemuan kuorum di setiap pusat data;
- ALL - Koordinator mengembalikan data setelah membaca dari semua node replika.

Dengan demikian, dimungkinkan untuk menyesuaikan waktu tunda operasi baca dan tulis dan menyesuaikan konsistensi (konsistensi nada), serta ketersediaan (availability) dari setiap jenis operasi. Faktanya, ketersediaan berhubungan langsung dengan tingkat konsistensi baca dan tulis, karena menentukan berapa banyak node replika yang dapat turun dan masih dapat dikonfirmasi.
Jika jumlah node dari mana pengakuan tulis berasal, ditambah jumlah node dari mana pembacaan dilakukan, lebih besar dari tingkat replikasi, maka kami memiliki jaminan bahwa nilai baru akan selalu dibaca setelah penulisan, dan ini disebut konsistensi yang kuat (strong konsistensi). Dengan tidak adanya konsistensi yang kuat, ada kemungkinan operasi baca akan mengembalikan data yang basi.
Bagaimanapun, nilai pada akhirnya akan menyebar di antara replika, tetapi hanya setelah penantian koordinasi berakhir. Penyebaran ini disebut konsistensi akhirnya. Jika tidak semua node replika tersedia pada saat penulisan, maka cepat atau lambat alat pemulihan seperti pembacaan perbaikan dan perbaikan node anti-entropi akan ikut berperan. Lebih lanjut tentang ini nanti.
Dengan demikian, dengan tingkat konsistensi baca tulis KUORUM, konsistensi yang kuat akan selalu terjaga, dan ini akan menjadi keseimbangan antara latensi baca dan tulis. Dengan SEMUA penulisan dan SATU pembacaan akan ada konsistensi yang kuat dan pembacaan akan lebih cepat dan lebih banyak tersedia, yaitu jumlah node yang gagal di mana pembacaan masih dapat diselesaikan dapat lebih besar dibandingkan dengan QUORUM.
Untuk operasi tulis, semua node pekerja replika akan diperlukan. Saat menulis SATU, membaca SEMUA, juga akan ada konsistensi yang ketat, dan operasi tulis akan lebih cepat dan ketersediaan tulis akan besar, karena cukup untuk mengonfirmasi hanya bahwa operasi tulis dilakukan pada setidaknya satu server, sementara membaca lebih lambat dan membutuhkan semua node replika. Jika aplikasi tidak memiliki persyaratan untuk konsistensi yang ketat, maka dimungkinkan untuk mempercepat operasi baca dan tulis, serta meningkatkan ketersediaan dengan mengatur tingkat konsistensi yang lebih rendah.
GO TO FULL VERSION