
Какво е регулярен израз (regex)?
Всъщност регулярният израз е модел за намиране на низ в текст. В Java оригиналното представяне на този модел винаги е низ, т.е. обект от класаString. Въпреки това, не всеки низ може да бъде компorран в регулярен израз — само низове, които отговарят на правилата за създаване на регулярни изрази. Синтаксисът е дефиниран в спецификацията на езика. Регулярните изрази се записват с помощта на букви и цифри, Howто и метасимволи, които са знаци, които имат специално meaning в синтаксиса на регулярните изрази. Например:
String regex = "java"; // The pattern is "java";
String regex = "\\d{3}"; // The pattern is three digits;
Създаване на регулярни изрази в Java
Създаването на регулярен израз в Java включва две прости стъпки:- напишете го като низ, който отговаря на синтаксиса на регулярния израз;
- компorрайте низа в регулярен израз;
Patternобект. За да направим това, трябва да извикаме един от двата статични метода на класа: compile. Първият метод приема един аргумент — низов литерал, съдържащ регулярния израз, докато вторият приема допълнителен аргумент, който определя настройките за съвпадение на шаблони:
public static Pattern compile (String literal)
public static Pattern compile (String literal, int flags)
flagsпараметъра е дефиниран в Patternклас и е достъпен за нас като статични променливи на класа. Например:
Pattern pattern = Pattern.compile("java", Pattern.CASE_INSENSITIVE); // Pattern-matching will be case insensitive.
Patternкласът е конструктор за регулярни изрази. Под капака, compileметодът извиква Patternчастния конструктор на класа, за да създаде компorрано представяне. Този механизъм за създаване на обекти е реализиран по този начин, за да създава неизменни обекти. Когато се създава регулярен израз, неговият синтаксис се проверява. Ако низът съдържа грешки, тогава PatternSyntaxExceptionсе генерира a.
Синтаксис на регулярен израз
Синтаксисът на регулярния израз разчита на<([{\^-=$!|]})?*+.>знаците, които могат да се комбинират с букви. В зависимост от ролята си те могат да бъдат разделени на няколко групи:
| Метазнак | Описание |
|---|---|
| ^ | начало на ред |
| $ | край на ред |
| \b | граница на думата |
| \Б | граница без думи |
| \A | началото на входа |
| \G | край на предишния мач |
| \Z | край на входа |
| \z | край на входа |
| Метазнак | Описание |
|---|---|
| \д | цифра |
| \Д | нецифрен |
| \с | празен знак |
| \С | знак без интервал |
| \w | буквено-цифров знак or долна черта |
| \W | всеки знак с изключение на букви, цифри и долна черта |
| . | произволен характер |

| Метазнак | Описание |
|---|---|
| \T | табулатор |
| \н | знак за нов ред |
| \r | връщане на каретка |
| \f | знак за подаване на ред |
| \u0085 | знак на следващия ред |
| \u2028 | разделител на редове |
| \u2029 | разделител на параграфи |
| Метазнак | Описание |
|---|---|
| [abc] | някой от изброените знаци (a, b or c) |
| [^abc] | всеки знак, различен от изброените (не a, b or c) |
| [a-zA-Z] | обединени диапазони (латински букви от a до z, без meaning за малки и големи букви) |
| [реклама[mp]] | обединение на знаци (от a до d и от m до p) |
| [az&&[def]] | пресичане на знаци (d, e, f) |
| [az&&[^bc]] | изваждане на знаци (a, dz) |
| Метазнак | Описание |
|---|---|
| ? | един or нито един |
| * | нула or повече пъти |
| + | един or повече пъти |
| {н} | n пъти |
| {н,} | n or повече пъти |
| {n,m} | поне n пъти и не повече от m пъти |
Алчни квантификатори
Едно нещо, което трябва да знаете за кванторите е, че те се предлагат в три различни разновидности: алчни, притежателни и неохотни. Вие правите квантор притежателен, като добавите+знак " " след квантора. Правите го неохотно, като добавите „ ?“. Например:
"A.+a" // greedy
"A.++a" // possessive
"A.+?a" // reluctant
public static void main(String[] args) {
String text = "Fred Anna Alexander";
Pattern pattern = Pattern.compile("A.+a");
Matcher matcher = pattern.matcher(text);
while (matcher.find()) {
System.out.println(text.substring(matcher.start(), matcher.end()));
}
}
Anna Alexa
A.+a" съпоставянето на образец се извършва, Howто следва:
-
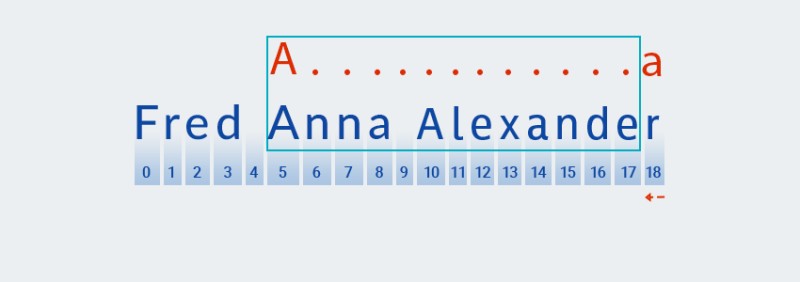
Първият знак в посочения модел е латинската буква
A.Matcherсравнява го с всеки знак от текста, започвайки от индекс нула. ЗнакътFе с индекс нула в нашия текст, така чеMatcherпреминава през знаците, докато съвпадне с шаблона. В нашия пример този символ се намира под индекс 5.![Регулярни изрази в Java - 2]()
-
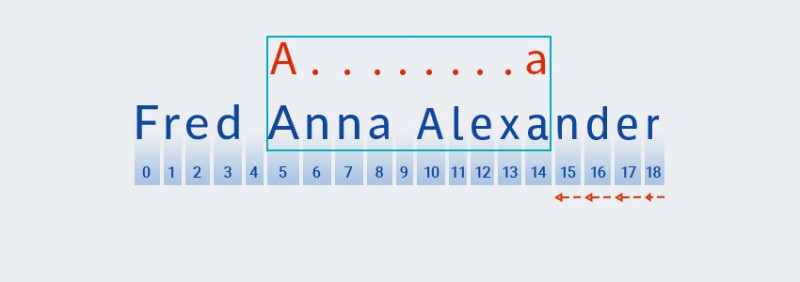
След като бъде намерено съвпадение с първия символ на шаблона,
Matcherтърси съвпадение с втория символ. В нашия случай това е.знакът " ", който означава произволен знак.![Регулярни изрази в Java - 3]()
Героят
nе на шеста позиция. Със сигурност се квалифицира като съвпадение за "всеки герой". -
Matcherпродължава да проверява следващия знак от модела. В нашия модел той е включен в квантора, който се прилага към предходния знак: ".+". Тъй като броят на повторенията на „всеки знак“ в нашия шаблон е един or повече пъти,Matcherмногократно взема следващия знак от низа и го сравнява с шаблона, стига да съвпада с „всеки знак“. В нашия пример — до края на низа (от индекс 7 до индекс 18).![Регулярни изрази в Java - 4]()
По принцип
Matcherизяжда низа до края — точно това се има предвид под „алчен“. -
След като Matcher достигне края на текста и завърши проверката за
A.+частта „ “ от шаблона, той започва проверка за останалата част от шаблона:a. Няма повече текст напред, така че проверката продължава чрез „отстъпване“, започвайки от последния знак:![Регулярни изрази в Java - 5]()
-
Matcher"помни" броя на повторенията в.+частта " " на модела. В този момент той намалява броя на повторенията с едно и проверява по-големия шаблон спрямо текста, докато се намери съвпадение:![Регулярни изрази в Java - 6]()



Притежателни квантори
Притежаващите квантификатори са много подобни на алчните. Разликата е, че когато текстът е уловен до края на низа, няма съвпадение на шаблони, докато се "отдръпва". С други думи, първите три етапа са същите като за алчните квантори. След улавяне на целия низ, съвпадащият добавя останалата част от шаблона към това, което обмисля, и го сравнява с уловения низ. В нашия пример, използвайки регулярния израз "A.++a", основният метод не намира съвпадение. 
Неохотни квантори
-
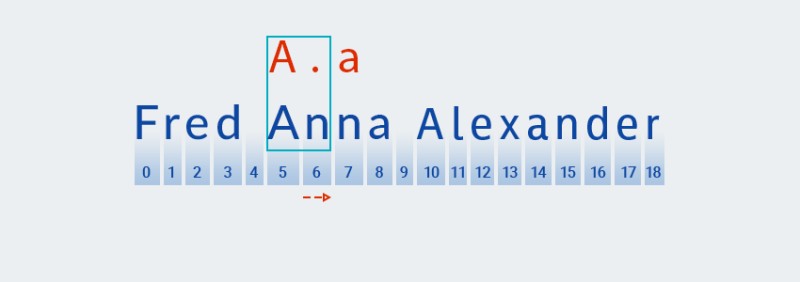
За тези квантификатори, Howто и при алчното разнообразие, codeът търси съвпадение въз основа на първия знак от модела:
![Регулярни изрази в Java - 8]()
-
След това търси съвпадение със следващия символ на шаблона (всеки знак):
![Регулярни изрази в Java - 9]()
-
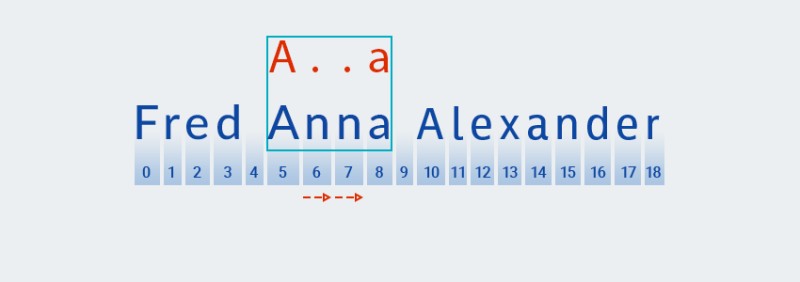
За разлика от алчното съпоставяне на шаблони, най-краткото съвпадение се търси при неохотно съпоставяне на шаблони. Това означава, че след намиране на съвпадение с втория символ на шаблона (точка, която съответства на знака на позиция 6 в текста,
Matcherпроверява дали текстът съвпада с останалата част от шаблона — знака "a"![Регулярни изрази в Java - 10]()
-
Текстът не съответства на модела (т.е. съдържа знака "
n" при индекс 7), така чеMatcherдобавя още един "всеки знак", тъй като кванторът показва един or повече. След това отново сравнява шаблона с текста в позиции от 5 до 8:![Регулярни изрази в Java - 11]()


В нашия случай е намерено съвпадение, но все още не сме стигнали до края на текста. Следователно, съпоставянето на модела започва отново от позиция 9, т.е. първият символ на модела се търси с помощта на подобен алгоритъм и това се повтаря до края на текста.

mainметодът получава следния резултат при използване на шаблона " A.+?a": Anna Alexa Както можете да видите от нашия пример, различните типове квантори произвеждат различни резултати за един и същ шаблон. Така че имайте това предвид и изберете правилния сорт въз основа на това, което търсите.
Екраниране на знаци в регулярни изрази
Тъй като регулярен израз в Java, or по-скоро неговото оригинално представяне, е низов литерал, трябва да отчетем правилата на Java относно низовите литерали. По-специално, символът обратна наклонена черта "\" в низови литерали в изходния code на Java се интерпретира като контролен знак, който казва на компилатора, че следващият знак е специален и трябва да се интерпретира по специален начин. Например:
String s = "The root directory is \nWindows"; // Move "Windows" to a new line
String s = "The root directory is \u00A7Windows"; // Insert a paragraph symbol before "Windows"
\знаци " " (т.е. за указване на метасимволи), трябва да повтарят обратните наклонени черти, за да гарантират, че компилаторът на Java byte code няма да интерпретира погрешно низа. Например:
String regex = "\\s"; // Pattern for matching a whitespace character
String regex = "\"Windows\""; // Pattern for matching "Windows"
String regex = "How\\?"; // Pattern for matching "How?"
Методи на класа Pattern
КласътPatternима други методи за работа с регулярни изрази:
-
String pattern()‒ връща оригиналното низово представяне на регулярния израз, използвано за създаване наPatternобекта:Pattern pattern = Pattern.compile("abc"); System.out.println(pattern.pattern()); // "abc" -
static boolean matches(String regex, CharSequence input)– позволява ви да проверите регулярния израз, предаден като regex спрямо текста, предаден катоinput. Се завръща:true – ако текстът отговаря на модела;
невярно – ако не;Например:
System.out.println(Pattern.matches("A.+a","Anna")); // true System.out.println(Pattern.matches("A.+a","Fred Anna Alexander")); // false -
int flags()‒ връща стойността наflagsнабора от параметри на шаблона, когато моделът е създаден, or 0, ако параметърът не е зададен. Например:Pattern pattern = Pattern.compile("abc"); System.out.println(pattern.flags()); // 0 Pattern pattern = Pattern.compile("abc",Pattern.CASE_INSENSITIVE); System.out.println(pattern.flags()); // 2 -
String[] split(CharSequence text, int limit)– разделя подавания текст вStringмасив. Параметърътlimitпоказва максималния брой търсени съвпадения в текста:- ако
limit > 0‒limit-1съвпада; - ако
limit < 0‒ всички съвпадения в текста - ако
limit = 0‒ всички съвпадения в текста, празните низове в края на масива се отхвърлят;
Например:
public static void main(String[] args) { String text = "Fred Anna Alexa"; Pattern pattern = Pattern.compile("\\s"); String[] strings = pattern.split(text,2); for (String s : strings) { System.out.println(s); } System.out.println("---------"); String[] strings1 = pattern.split(text); for (String s : strings1) { System.out.println(s); } }Конзолен изход:
Fred Anna Alexa --------- Fred Anna AlexaПо-долу ще разгледаме друг метод на класа, използван за създаване на
Matcherобект. - ако
Методи на класа Matcher
Екземплярите наMatcherкласа се създават за извършване на съпоставяне на шаблони. Matcherе "търсачката" за регулярни изрази. За да извършим търсене, трябва да му дадем две неща: модел и начален индекс. За да създадете Matcherобект, Patternкласът предоставя следния метод: рublic Matcher matcher(CharSequence input) Методът взема последователност от знаци, която ще бъде претърсена. Това е екземпляр на клас, който имплементира CharSequenceинтерфейса. Можете да подадете не само String, но и StringBuffer, StringBuilder, Segmentor CharBuffer. Шаблонът е Patternобект, върху който matcherсе извиква методът. Пример за създаване на съвпадение:
Pattern p = Pattern.compile("a*b"); // Create a compiled representation of the regular expression
Matcher m = p.matcher("aaaaab"); // Create a "search engine" to search the text "aaaaab" for the pattern "a*b"

boolean find()търси следващото съвпадение в текста. Можем да използваме този метод и оператор за цикъл, за да анализираме цял текст като част от модел на събитие. С други думи, можем да извършим необходимите операции, когато настъпи събитие, т.е. когато намерим съвпадение в текста. Например, можем да използваме този клас int start()и int end()методи, за да определим позицията на съвпадение в текста. И можем да използваме методите String replaceFirst(String replacement)и String replaceAll(String replacement)за замяна на съвпадения със стойността на заместващия параметър. Например:
public static void main(String[] args) {
String text = "Fred Anna Alexa";
Pattern pattern = Pattern.compile("A.+?a");
Matcher matcher = pattern.matcher(text);
while (matcher.find()) {
int start=matcher.start();
int end=matcher.end();
System.out.println("Match found: " + text.substring(start, end) + " from index "+ start + " through " + (end-1));
}
System.out.println(matcher.replaceFirst("Ira"));
System.out.println(matcher.replaceAll("Mary"));
System.out.println(text);
}
Match found: Anna from index 5 through 8
Match found: Alexa from index 10 through 14
Fred Ira Alexa
Fred Mary Mary
Fred Anna Alexa
replaceFirstand replaceAllсъздават нов Stringобект — низ, в който съвпаденията на шаблона в оригиналния текст се заменят с текста, предаден на метода като аргумент. Освен това replaceFirstметодът замества само първото съвпадение, но replaceAllметодът замества всички съвпадения в текста. Оригиналният текст остава непроменен. Най-честите операции с регулярни изрази на класовете Patternи са вградени направо в класа. Това са методи като , , и . Но под капака тези методи използват класовете и . Така че, ако искате да замените текст or да сравните низове в програма, без да пишете допълнителен code, използвайте методите наMatcherStringsplitmatchesreplaceFirstreplaceAllPatternMatcherStringклас. Ако имате нужда от по-разширени функции, запомнете класовете Patternи Matcher.
Заключение
В програма на Java регулярен израз се дефинира от низ, който се подчинява на специфични правила за съвпадение на шаблони. Когато изпълнява code, Java машината компorра този низ вPatternобект и използва Matcherобект, за да намери съвпадения в текста. Както казах в началото, хората често отлагат регулярните изрази за по-късно, смятайки ги за трудна тема. Но ако разбирате основния синтаксис, метасимволите и екранирането на знаци и изучавате примери за регулярни изрази, тогава ще откриете, че те са много по-прости, отколкото изглеждат на пръв поглед.
|
Още четене: |
|---|
GO TO FULL VERSION