
นิพจน์ทั่วไป (regex) คืออะไร
ในความเป็นจริง นิพจน์ทั่วไปเป็นรูปแบบสำหรับการค้นหาสตริงในข้อความ ใน Java การแสดงดั้งเดิมของรูปแบบนี้จะเป็นสตริงเสมอ นั่นคือออบเจกต์ของStringคลาส อย่างไรก็ตาม ไม่ใช่สตริงที่สามารถรวบรวมเป็นนิพจน์ทั่วไปได้ — เฉพาะสตริงที่สอดคล้องกับกฎสำหรับการสร้างนิพจน์ทั่วไป ไวยากรณ์ถูกกำหนดไว้ในข้อกำหนดภาษา นิพจน์ทั่วไปเขียนโดยใช้ตัวอักษรและตัวเลข รวมถึงอักขระเมตา ซึ่งเป็นอักขระที่มีความหมายพิเศษในไวยากรณ์ของนิพจน์ทั่วไป ตัวอย่างเช่น:
String regex = "java"; // The pattern is "java";
String regex = "\\d{3}"; // The pattern is three digits;
การสร้าง Regular Expression ใน Java
การสร้าง Regular Expression ใน Java มีขั้นตอนง่ายๆ สองขั้นตอน:- เขียนเป็นสตริงที่สอดคล้องกับไวยากรณ์ของนิพจน์ทั่วไป
- รวบรวมสตริงเป็นนิพจน์ทั่วไป
Patternวัตถุ ในการทำเช่นนี้เราต้องเรียกหนึ่งในสองวิธีแบบคงที่ของคลาสcompile: วิธีแรกรับหนึ่งอาร์กิวเมนต์ — สตริงลิเทอรัลที่มีนิพจน์ทั่วไป ในขณะที่วิธีที่สองรับอาร์กิวเมนต์เพิ่มเติมที่กำหนดการตั้งค่าการจับคู่รูปแบบ:
public static Pattern compile (String literal)
public static Pattern compile (String literal, int flags)
flagsพารามิเตอร์ถูกกำหนดในPatternคลาสและพร้อมใช้งานสำหรับเราในฐานะตัวแปรคลาสแบบคงที่ ตัวอย่างเช่น:
Pattern pattern = Pattern.compile("java", Pattern.CASE_INSENSITIVE); // Pattern-matching will be case insensitive.
Patternคลาสคือตัวสร้างสำหรับนิพจน์ทั่วไป ภายใต้ประทุน เมธอดcompileเรียกPatternตัวสร้างส่วนตัวของคลาสเพื่อสร้างตัวแทนที่คอมไพล์แล้ว กลไกการสร้างวัตถุนี้ถูกนำมาใช้ในลักษณะนี้เพื่อสร้างวัตถุที่ไม่เปลี่ยนรูป เมื่อสร้างนิพจน์ทั่วไป ไวยากรณ์จะถูกตรวจสอบ หากสตริงมีข้อผิดพลาด ระบบPatternSyntaxExceptionจะสร้าง a
ไวยากรณ์นิพจน์ทั่วไป
ไวยากรณ์ของนิพจน์ทั่วไปขึ้นอยู่กับ<([{\^-=$!|]})?*+.>อักขระ ซึ่งสามารถรวมเข้ากับตัวอักษรได้ ขึ้นอยู่กับบทบาทของพวกเขา พวกเขาสามารถแบ่งออกเป็นหลายกลุ่ม:
| เมตาอักขระ | คำอธิบาย |
|---|---|
| ^ | จุดเริ่มต้นของบรรทัด |
| $ | สิ้นสุดบรรทัด |
| \b | ขอบเขตของคำ |
| \B | ขอบเขตที่ไม่ใช่คำ |
| \เอ | จุดเริ่มต้นของอินพุต |
| \G | สิ้นสุดการแข่งขันนัดที่แล้ว |
| \Z | สิ้นสุดการป้อนข้อมูล |
| \z | สิ้นสุดการป้อนข้อมูล |
| เมตาอักขระ | คำอธิบาย |
|---|---|
| \d | หลัก |
| \D | ไม่ใช่ตัวเลข |
| \s | อักขระช่องว่าง |
| \S | อักขระที่ไม่ใช่ช่องว่าง |
| \w | อักขระที่เป็นตัวอักษรและตัวเลขคละกันหรือขีดล่าง |
| \ว | อักขระใดๆ ยกเว้นตัวอักษร ตัวเลข และเครื่องหมายขีดล่าง |
| . | อักขระใดก็ได้ |

| เมตาอักขระ | คำอธิบาย |
|---|---|
| \t | อักขระแท็บ |
| \n | ตัวละครขึ้นบรรทัดใหม่ |
| \r | การกลับรถ |
| \f | อักขระป้อนบรรทัด |
| \u0085 | อักขระบรรทัดถัดไป |
| \u2028 | ตัวคั่นบรรทัด |
| \u2029 | ตัวคั่นย่อหน้า |
| เมตาอักขระ | คำอธิบาย |
|---|---|
| [เอบีซี] | อักขระใด ๆ ในรายการ (a, b หรือ c) |
| [^เอบีซี] | อักขระใดๆ นอกเหนือจากที่ระบุไว้ (ไม่ใช่ a, b หรือ c) |
| [a-zA-Z] | ช่วงที่ผสาน (อักขระละตินจาก a ถึง z ไม่คำนึงถึงขนาดตัวพิมพ์) |
| [โฆษณา[mp]] | การรวมกันของอักขระ (จาก a ถึง d และจาก m ถึง p) |
| [อัซ&&[def]] | การตัดกันของอักขระ (d, e, f) |
| [อัซ&&[^bc]] | การลบอักขระ (a, dz) |
| เมตาอักขระ | คำอธิบาย |
|---|---|
| ? | อย่างใดอย่างหนึ่งหรือไม่มีเลย |
| * | ศูนย์หรือมากกว่านั้น |
| + | หนึ่งครั้งหรือหลายครั้ง |
| {n} | n ครั้ง |
| {n,} | n ครั้งขึ้นไป |
| {n,m} | อย่างน้อย n ครั้งและไม่เกิน m ครั้ง |
ปริมาณโลภ
สิ่งหนึ่งที่คุณควรรู้เกี่ยวกับตัววัดปริมาณคือพวกมันมีสามแบบที่แตกต่างกัน: โลภ หวงแหน และลังเลใจ คุณสร้างตัวระบุเชิงปริมาณโดยเพิ่ม+อักขระ " " หลังตัวระบุเชิงปริมาณ คุณทำให้มันลังเลโดยการเพิ่ม " ?" ตัวอย่างเช่น:
"A.+a" // greedy
"A.++a" // possessive
"A.+?a" // reluctant
public static void main(String[] args) {
String text = "Fred Anna Alexander";
Pattern pattern = Pattern.compile("A.+a");
Matcher matcher = pattern.matcher(text);
while (matcher.find()) {
System.out.println(text.substring(matcher.start(), matcher.end()));
}
}
Anna Alexa
A.+a" การจับคู่รูปแบบจะดำเนินการดังนี้:
-
อักขระตัวแรกในรูปแบบที่ระบุคืออักษร
AละตินMatcherเปรียบเทียบกับอักขระแต่ละตัวของข้อความโดยเริ่มจากดัชนีศูนย์ อักขระFอยู่ที่ดัชนีศูนย์ในข้อความของเรา ดังนั้นMatcherให้วนซ้ำอักขระจนกว่าจะตรงกับรูปแบบ ในตัวอย่างของเรา อักขระนี้อยู่ที่ดัชนี 5![นิพจน์ทั่วไปใน Java - 2]()
-
เมื่อพบการจับคู่กับอักขระตัวแรกของรูปแบบ ให้
Matcherค้นหาการจับคู่กับอักขระตัวที่สอง ในกรณีของเรา มันคือ.อักขระ " " ซึ่งย่อมาจากอักขระใดๆ![นิพจน์ทั่วไปใน Java - 3]()
ตัวละคร
nอยู่ในตำแหน่งที่หก มันมีคุณสมบัติตรงกับ "ตัวละครใดก็ได้" อย่างแน่นอน -
Matcherดำเนินการตรวจสอบอักขระต่อไปของรูปแบบ ในรูปแบบของเรา จะรวมอยู่ในตัวบอกปริมาณที่ใช้กับอักขระนำหน้า: ".+" เนื่องจากจำนวนการทำซ้ำของ "อักขระใดๆ" ในรูปแบบของเราคือ 1 ครั้งขึ้นไปMatcherให้นำอักขระถัดไปจากสตริงซ้ำๆ และตรวจสอบกับรูปแบบตราบเท่าที่ตรงกับ "อักขระใดๆ" ในตัวอย่างของเรา — จนถึงจุดสิ้นสุดของสตริง (จากดัชนี 7 ถึงดัชนี 18)![นิพจน์ทั่วไปใน Java - 4]()
โดยพื้นฐานแล้ว
Matcherกลืนสายไปจนสุด — นี่คือความหมายที่แท้จริงของคำว่า "โลภ" -
หลังจาก Matcher ถึงจุดสิ้นสุดของข้อความและตรวจสอบ
A.+ส่วน " " ของรูปแบบเสร็จแล้ว โปรแกรมจะเริ่มตรวจสอบส่วนที่เหลือของรูปแบบa: ไม่มีการส่งต่อข้อความอีกต่อไป ดังนั้นการตรวจสอบจะดำเนินการโดย "ถอยกลับ" โดยเริ่มจากอักขระตัวสุดท้าย:![นิพจน์ทั่วไปใน Java - 5]()
-
Matcher"จำ" จำนวนการทำซ้ำใน.+ส่วน " " ของรูปแบบ ณ จุดนี้ จะลดจำนวนการทำซ้ำลงหนึ่งรายการและตรวจสอบรูปแบบที่ใหญ่กว่ากับข้อความจนกว่าจะพบรายการที่ตรงกัน:![นิพจน์ทั่วไปใน Java - 6]()



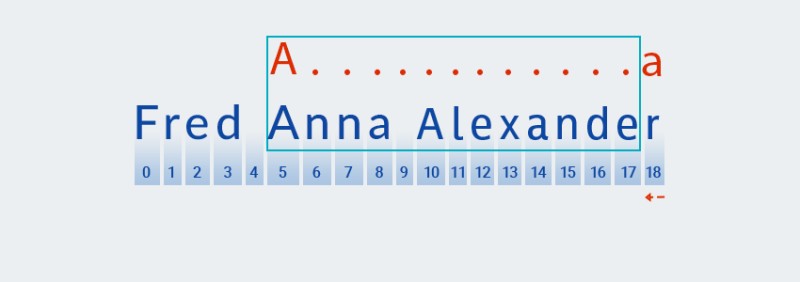
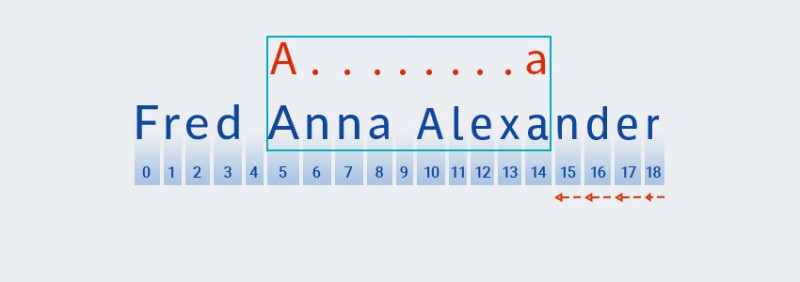
ปริมาณที่เป็นเจ้าของ
ปริมาณที่มีความเป็นเจ้าของนั้นเหมือนกับคนโลภมาก ความแตกต่างคือเมื่อข้อความถูกจับไปที่ส่วนท้ายของสตริง จะไม่มีการจับคู่รูปแบบในขณะที่ "ถอยกลับ" กล่าวอีกนัยหนึ่ง สามขั้นแรกจะเหมือนกับการวัดปริมาณแบบละโมบ หลังจากจับสตริงทั้งหมดแล้ว ตัวจับคู่จะเพิ่มรูปแบบที่เหลือให้กับสิ่งที่กำลังพิจารณาและเปรียบเทียบกับสตริงที่จับได้ ในตัวอย่างของเรา การใช้นิพจน์ทั่วไป "A.++a" เมธอดหลักไม่พบค่าที่ตรงกัน 
ปริมาณที่ไม่เต็มใจ
-
สำหรับปริมาณเหล่านี้ เช่นเดียวกับความหลากหลายโลภ โค้ดจะค้นหาการจับคู่ตามอักขระตัวแรกของรูปแบบ:
![นิพจน์ทั่วไปใน Java - 8]()
-
จากนั้นจะค้นหาการจับคู่กับอักขระถัดไปของรูปแบบ (อักขระใดก็ได้):
![นิพจน์ทั่วไปใน Java - 9]()
-
ซึ่งแตกต่างจากการจับคู่รูปแบบโลภ การจับคู่ที่สั้นที่สุดจะถูกค้นหาในการจับคู่รูปแบบที่ไม่เต็มใจ ซึ่งหมายความว่าหลังจากพบการจับคู่กับอักขระตัวที่สองของรูปแบบแล้ว (จุดซึ่งตรงกับอักขระที่ตำแหน่ง 6 ในข้อความ ให้
Matcherตรวจสอบว่าข้อความตรงกับอักขระที่เหลือของรูปแบบหรือไม่ — อักขระ "a"![นิพจน์ทั่วไปใน Java - 10]()
-
ข้อความไม่ตรงกับรูปแบบ (เช่น มีอักขระ "
n" ที่ดัชนี 7) ดังนั้นMatcherให้เพิ่ม "อักขระใดก็ได้" อีก 1 ตัว เนื่องจากตัวระบุจะระบุอย่างน้อยหนึ่งตัว จากนั้นจะเปรียบเทียบรูปแบบกับข้อความในตำแหน่งที่ 5 ถึง 8 อีกครั้ง:![นิพจน์ทั่วไปใน Java - 11]()


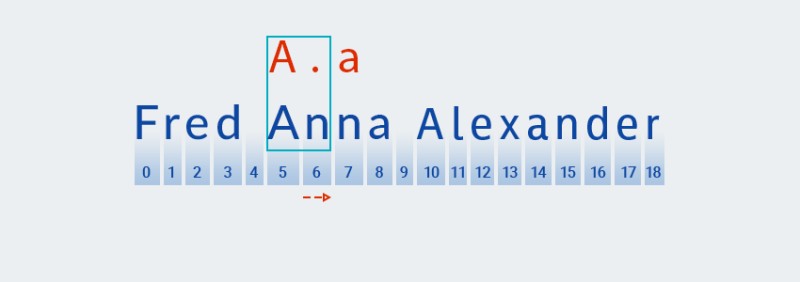
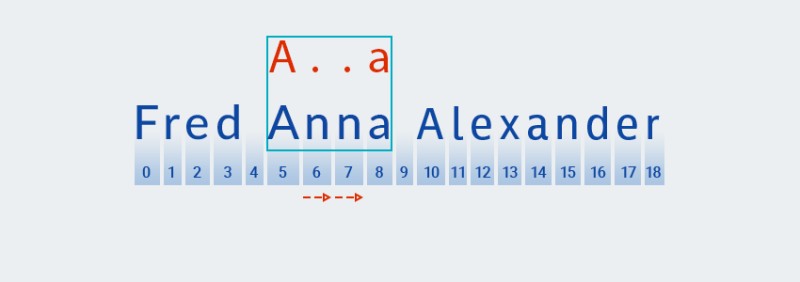
ในกรณีของเรา พบข้อมูลที่ตรงกัน แต่เรายังไม่ถึงจุดสิ้นสุดของข้อความ ดังนั้น การจับคู่รูปแบบจะเริ่มต้นใหม่จากตำแหน่งที่ 9 กล่าวคือ อักขระตัวแรกของรูปแบบจะถูกค้นหาโดยใช้อัลกอริทึมที่คล้ายคลึงกัน และจะทำซ้ำจนกว่าจะสิ้นสุดข้อความ

mainวิธีการจะได้ผลลัพธ์ต่อไปนี้เมื่อใช้รูปแบบ " A.+?a": Anna Alexa ดังที่คุณเห็นจากตัวอย่างของเรา quantifiers ประเภทต่างๆ ให้ผลลัพธ์ที่แตกต่างกันสำหรับรูปแบบเดียวกัน ดังนั้นจำไว้และเลือกพันธุ์ที่เหมาะสมตามสิ่งที่คุณกำลังมองหา
การหลบหนีอักขระในนิพจน์ทั่วไป
เนื่องจากนิพจน์ทั่วไปใน Java หรือมากกว่านั้น เป็นตัวแทนดั้งเดิม เป็นสตริงลิเทอรัล เราจำเป็นต้องคำนึงถึงกฎของจาวาเกี่ยวกับสตริงลิเทอรัล โดยเฉพาะอย่างยิ่ง อักขระแบ็กสแลช "\" ในตัวอักษรสตริงในซอร์สโค้ด Java ถูกตีความเป็นอักขระควบคุมที่บอกคอมไพเลอร์ว่าอักขระถัดไปเป็นอักขระพิเศษ และต้องตีความในลักษณะพิเศษ ตัวอย่างเช่น:
String s = "The root directory is \nWindows"; // Move "Windows" to a new line
String s = "The root directory is \u00A7Windows"; // Insert a paragraph symbol before "Windows"
\อักขระ " " (เช่น เพื่อระบุอักขระเมตา) ต้องใส่แบ็กสแลชซ้ำเพื่อให้แน่ใจว่าคอมไพเลอร์ Java bytecode จะไม่ตีความสตริงผิด ตัวอย่างเช่น:
String regex = "\\s"; // Pattern for matching a whitespace character
String regex = "\"Windows\""; // Pattern for matching "Windows"
String regex = "How\\?"; // Pattern for matching "How?"
เมธอดของคลาส Pattern
ชั้นPatternเรียนมีวิธีการอื่นสำหรับการทำงานกับนิพจน์ทั่วไป:
-
String pattern()‒ ส่งคืนการแสดงสตริงดั้งเดิมของนิพจน์ทั่วไปที่ใช้สร้างPatternวัตถุ:Pattern pattern = Pattern.compile("abc"); System.out.println(pattern.pattern()); // "abc" -
static boolean matches(String regex, CharSequence input)– ให้คุณตรวจสอบนิพจน์ทั่วไปที่ส่งเป็น regex กับข้อความที่ส่งเป็นinput. ผลตอบแทน:จริง – ถ้าข้อความตรงกับรูปแบบ
เท็จ – ถ้าไม่ใช่;ตัวอย่างเช่น:
System.out.println(Pattern.matches("A.+a","Anna")); // true System.out.println(Pattern.matches("A.+a","Fred Anna Alexander")); // false -
int flags()‒ ส่งกลับค่าของflagsชุดพารามิเตอร์ของรูปแบบเมื่อสร้างรูปแบบหรือ 0 หากไม่ได้ตั้งค่าพารามิเตอร์ ตัวอย่างเช่น:Pattern pattern = Pattern.compile("abc"); System.out.println(pattern.flags()); // 0 Pattern pattern = Pattern.compile("abc",Pattern.CASE_INSENSITIVE); System.out.println(pattern.flags()); // 2 -
String[] split(CharSequence text, int limit)– แยกข้อความที่ส่งผ่านเป็นStringอาร์เรย์ พารามิเตอร์limitระบุจำนวนสูงสุดของการจับคู่ที่ค้นหาในข้อความ:- ถ้า
limit > 0‒limit-1ตรงกัน; - ถ้า
limit < 0‒ ตรงกับข้อความทั้งหมด - ถ้า
limit = 0‒ ตรงกับข้อความทั้งหมด สตริงว่างที่ส่วนท้ายของอาร์เรย์จะถูกยกเลิก
ตัวอย่างเช่น:
public static void main(String[] args) { String text = "Fred Anna Alexa"; Pattern pattern = Pattern.compile("\\s"); String[] strings = pattern.split(text,2); for (String s : strings) { System.out.println(s); } System.out.println("---------"); String[] strings1 = pattern.split(text); for (String s : strings1) { System.out.println(s); } }เอาต์พุตคอนโซล:
Fred Anna Alexa --------- Fred Anna Alexaด้านล่างนี้เราจะพิจารณาวิธีการของคลาสอื่นที่ใช้ในการสร้าง
Matcherวัตถุ - ถ้า
เมธอดของคลาส Matcher
อินสแตนซ์ของMatcherคลาสถูกสร้างขึ้นเพื่อทำการจับคู่รูปแบบ Matcherเป็น "เครื่องมือค้นหา" สำหรับนิพจน์ทั่วไป ในการค้นหา เราต้องระบุสองสิ่ง: รูปแบบและดัชนีเริ่มต้น ในการสร้างMatcherออบเจกPatternต์ คลาสจัดเตรียมเมธอดต่อไปนี้ рublic Matcher matcher(CharSequence input) เมธอดใช้ลำดับอักขระ ซึ่งจะถูกค้นหา นี่คืออินสแตนซ์ของคลาสที่ใช้CharSequenceอินเทอร์เฟซ คุณสามารถผ่านได้ไม่เพียงแค่ a Stringแต่ยังรวมถึง a StringBuffer, StringBuilder, Segment, CharBufferหรือ รูปแบบเป็นPatternวัตถุที่matcherเรียกใช้เมธอด ตัวอย่างการสร้างการจับคู่:
Pattern p = Pattern.compile("a*b"); // Create a compiled representation of the regular expression
Matcher m = p.matcher("aaaaab"); // Create a "search engine" to search the text "aaaaab" for the pattern "a*b"

boolean find()การค้นหาการจับคู่ถัดไปในข้อความ เราสามารถใช้วิธีนี้และคำสั่งวนซ้ำเพื่อวิเคราะห์ข้อความทั้งหมดโดยเป็นส่วนหนึ่งของแบบจำลองเหตุการณ์ กล่าวอีกนัยหนึ่ง เราสามารถดำเนินการที่จำเป็นเมื่อมีเหตุการณ์เกิดขึ้น เช่น เมื่อเราพบข้อความที่ตรงกัน ตัวอย่างเช่น เราสามารถใช้คลาสint start()และint end()เมธอดนี้เพื่อกำหนดตำแหน่งการจับคู่ในข้อความ และเราสามารถใช้String replaceFirst(String replacement)and String replaceAll(String replacement)วิธีการแทนที่การจับคู่ด้วยค่าของพารามิเตอร์การแทนที่ ตัวอย่างเช่น:
public static void main(String[] args) {
String text = "Fred Anna Alexa";
Pattern pattern = Pattern.compile("A.+?a");
Matcher matcher = pattern.matcher(text);
while (matcher.find()) {
int start=matcher.start();
int end=matcher.end();
System.out.println("Match found: " + text.substring(start, end) + " from index "+ start + " through " + (end-1));
}
System.out.println(matcher.replaceFirst("Ira"));
System.out.println(matcher.replaceAll("Mary"));
System.out.println(text);
}
Match found: Anna from index 5 through 8
Match found: Alexa from index 10 through 14
Fred Ira Alexa
Fred Mary Mary
Fred Anna Alexa
replaceFirstand replaceAllสร้างStringวัตถุใหม่ — สตริงที่รูปแบบตรงกับข้อความต้นฉบับจะถูกแทนที่ด้วยข้อความที่ส่งไปยังเมธอดเป็นอาร์กิวเมนต์ นอกจากนี้replaceFirstเมธอดจะแทนที่เฉพาะการจับคู่แรกเท่านั้น แต่replaceAllเมธอดจะแทนที่การจับคู่ทั้งหมดในข้อความ ข้อความเดิมยังคงไม่เปลี่ยนแปลง การดำเนินการ regex ที่พบบ่อยที่สุดของ คลาสPatternและMatcherคลาสถูกสร้างขึ้นในStringคลาส โดยตรง วิธีการเหล่านี้ได้แก่split, matches, replaceFirst, replaceAllและ แต่ภายใต้ประทุน วิธีการเหล่านี้ใช้Patternand Matcherคลาส ดังนั้น หากคุณต้องการแทนที่ข้อความหรือเปรียบเทียบสตริงในโปรแกรมโดยไม่ต้องเขียนโค้ดเพิ่มเติม ให้ใช้วิธีการของStringระดับ. หากคุณต้องการคุณสมบัติขั้นสูงเพิ่มเติม โปรดจำPatternและMatcherคลาส
บทสรุป
ในโปรแกรม Java นิพจน์ทั่วไปถูกกำหนดโดยสตริงที่เป็นไปตามกฎการจับคู่รูปแบบเฉพาะ เมื่อรันโค้ด เครื่อง Java จะคอมไพล์สตริงนี้เป็นออบPatternเจกต์และใช้Matcherออบเจกต์เพื่อค้นหาสิ่งที่ตรงกันในข้อความ อย่างที่ฉันได้กล่าวไปในตอนต้น ผู้คนมักจะเลิกใช้นิพจน์ทั่วไปในภายหลัง เนื่องจากพิจารณาว่าเป็นหัวข้อที่ยาก แต่ถ้าคุณเข้าใจไวยากรณ์พื้นฐาน อักขระเมตา และการเอสเคปอักขระ และศึกษาตัวอย่างนิพจน์ทั่วไป คุณจะพบว่าสิ่งเหล่านี้ง่ายกว่าที่เห็นเมื่อมองแวบแรกมาก
|
อ่านเพิ่มเติม: |
|---|
GO TO FULL VERSION