
Qu'est-ce qu'une expression régulière (regex)?
En fait, une expression régulière est un modèle pour trouver une chaîne dans un texte. En Java, la représentation originale de ce motif est toujours une chaîne, c'est-à-dire un objet de laStringclasse. Cependant, ce n'est pas n'importe quelle chaîne qui peut être compilée dans une expression régulière — seulement les chaînes qui sont conformes aux règles de création d'expressions régulières.
La syntaxe est définie dans la spécification du langage. Les expressions régulières sont écrites à l'aide de lettres et de chiffres, ainsi que de métacaractères, qui sont des caractères ayant une signification particulière dans la syntaxe des expressions régulières. Par exemple:
String regex = "java"; // The pattern is "java";
String regex = "\\d{3}"; // The pattern is three digits;
Création d'expressions régulières en Java
La création d'une expression régulière en Java implique deux étapes simples :- écrivez-le sous la forme d'une chaîne conforme à la syntaxe des expressions régulières ;
- compilez la chaîne dans une expression régulière ;
Patternobjet. Pour ce faire, nous devons appeler l'une des deux méthodes statiques de la classe : compile.
La première méthode prend un argument - un littéral de chaîne contenant l'expression régulière, tandis que la seconde prend un argument supplémentaire qui détermine les paramètres de correspondance de modèle :
public static Pattern compile (String literal)
public static Pattern compile (String literal, int flags)
flagsparamètre est définie dans Patternla classe et nous est disponible sous forme de variables de classe statiques. Par exemple:
Pattern pattern = Pattern.compile("java", Pattern.CASE_INSENSITIVE); // Pattern-matching will be case insensitive.
Patternclasse est un constructeur d'expressions régulières. Sous le capot, la compileméthode appelle le Patternconstructeur privé de la classe pour créer une représentation compilée. Ce mécanisme de création d'objets est implémenté de cette façon afin de créer des objets immuables. Lorsqu'une expression régulière est créée, sa syntaxe est vérifiée. Si la chaîne contient des erreurs, un PatternSyntaxExceptionest généré.Syntaxe des expressions régulières
La syntaxe des expressions régulières repose sur les<([{\^-=$!|]})?*+.>caractères, qui peuvent être combinés avec des lettres. Selon leur rôle, ils peuvent être divisés en plusieurs groupes :
| Métacaractère | Description |
|---|---|
| ^ | début de ligne |
| $ | fin d'une ligne |
| \b | limite de mot |
| \B | limite de non-mot |
| \UN | début de la saisie |
| \G | fin du match précédent |
| \Z | fin de l'entrée |
| \z | fin de l'entrée |
| Métacaractère | Description |
|---|---|
| \d | chiffre |
| \D | non numérique |
| \s | caractère d'espacement |
| \S | caractère non blanc |
| \w | caractère alphanumérique ou trait de soulignement |
| \W | n'importe quel caractère sauf les lettres, les chiffres et le trait de soulignement |
| . | N'importe quel caractère |
| Métacaractère | Description |
|---|---|
| \t | caractère de tabulation |
| \n | caractère de retour à la ligne |
| \r | retour chariot |
| \F | caractère de saut de ligne |
| \u0085 | caractère de la ligne suivante |
| \u2028 | séparateur de ligne |
| \u2029 | séparateur de paragraphe |
| Métacaractère | Description |
|---|---|
| [abc] | l'un des caractères répertoriés (a, b ou c) |
| [^abc] | tout caractère autre que ceux répertoriés (pas a, b ou c) |
| [a-zA-Z] | plages fusionnées (caractères latins de a à z, insensibles à la casse) |
| [annonce[mp]] | union de caractères (de a à d et de m à p) |
| [az&&[déf]] | intersection de caractères (d, e, f) |
| [az&&[^bc]] | soustraction de caractères (a, dz) |
| Métacaractère | Description |
|---|---|
| ? | un ou aucun |
| * | zéro ou plusieurs fois |
| + | une ou plusieurs fois |
| {n} | n fois |
| {n,} | n fois ou plus |
| {n,m} | au moins n fois et pas plus de m fois |

Quantificateurs gourmands
Une chose que vous devez savoir sur les quantificateurs est qu'ils se déclinent en trois variétés différentes : gourmands, possessifs et réticents. Vous rendez un quantificateur possessif en ajoutant un+caractère " " après le quantificateur. Vous le rendez réticent en ajoutant " ?". Par exemple:
"A.+a" // greedy
"A.++a" // possessive
"A.+?a" // reluctant
public static void main(String[] args) {
String text = "Fred Anna Alexander";
Pattern pattern = Pattern.compile("A.+a");
Matcher matcher = pattern.matcher(text);
while (matcher.find()) {
System.out.println(text.substring(matcher.start(), matcher.end()));
}
}
Anna Alexa
A.+a", la correspondance de modèle est effectuée comme suit :
-
Le premier caractère du modèle spécifié est la lettre latine
A.Matcherle compare avec chaque caractère du texte, à partir de l'index zéro. Le caractèreFest à l'index zéro dans notre texte,Matcheril parcourt donc les caractères jusqu'à ce qu'il corresponde au modèle. Dans notre exemple, ce caractère se trouve à l'index 5.![Expressions régulières en Java - 2]()
-
Une fois qu'une correspondance avec le premier caractère du modèle est trouvée,
Matcherrecherche une correspondance avec son deuxième caractère. Dans notre cas, il s'agit du.caractère " ", qui représente n'importe quel caractère.![Expressions régulières en Java - 3]()
Le personnage
nest en sixième position. Il se qualifie certainement comme un match pour "n'importe quel personnage". -
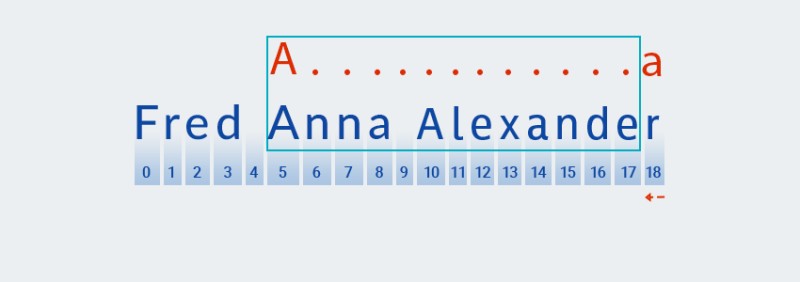
Matcherprocède à la vérification du caractère suivant du motif. Dans notre modèle, il est inclus dans le quantificateur qui s'applique au caractère précédent : ".+". Étant donné que le nombre de répétitions de "n'importe quel caractère" dans notre modèle est une ou plusieurs fois,Matcherprend à plusieurs reprises le caractère suivant de la chaîne et le vérifie par rapport au modèle tant qu'il correspond à "n'importe quel caractère". Dans notre exemple — jusqu'à la fin de la chaîne (de l'index 7 à l'index 18).![Expressions régulières en Java - 4]()
En gros,
Matchergobe la ficelle jusqu'au bout — c'est précisément ce que l'on entend par "gourmand". -
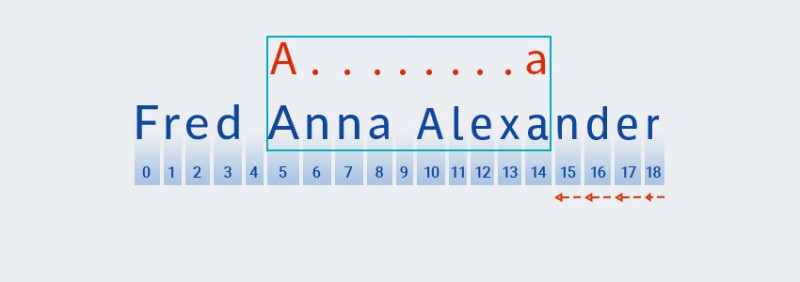
Une fois que Matcher a atteint la fin du texte et terminé la vérification de la
A.+partie " " du motif, il commence à vérifier le reste du motif :a. Il n'y a plus de texte qui avance, donc la vérification se poursuit en "reculant", en commençant par le dernier caractère :![Expressions régulières en Java - 5]()
-
Matcher"se souvient" du nombre de répétitions dans la.+partie " " du motif. À ce stade, il réduit le nombre de répétitions d'une unité et vérifie le motif le plus large par rapport au texte jusqu'à ce qu'une correspondance soit trouvée :![Expressions régulières en Java - 6]()



Quantificateurs possessifs
Les quantificateurs possessifs ressemblent beaucoup aux quantificateurs gourmands. La différence est que lorsque le texte a été capturé jusqu'à la fin de la chaîne, il n'y a pas de correspondance de modèle lors de la "recul". En d'autres termes, les trois premières étapes sont les mêmes que pour les quantificateurs gloutons. Après avoir capturé la chaîne entière, le matcher ajoute le reste du modèle à ce qu'il considère et le compare avec la chaîne capturée. Dans notre exemple, en utilisant l'expression régulière "A.++a", la méthode principale ne trouve aucune correspondance. 
Quantificateurs réticents
-
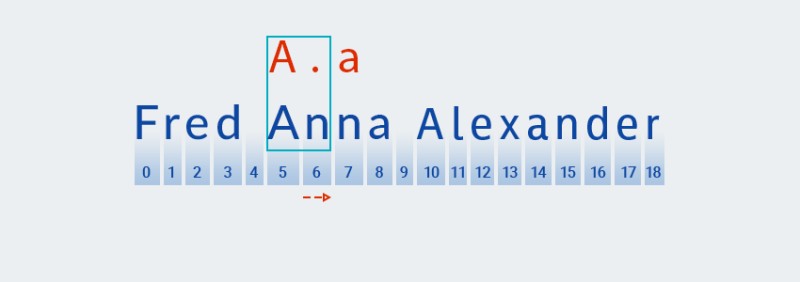
Pour ces quantificateurs, comme pour la variété gourmande, le code recherche une correspondance basée sur le premier caractère du modèle :
![Expressions régulières en Java - 8]()
-
Ensuite, il recherche une correspondance avec le caractère suivant du motif (n'importe quel caractère) :
![Expressions régulières en Java - 9]()
-
Contrairement au pattern-matching gourmand, la correspondance la plus courte est recherchée dans le pattern-matching réticent. Cela signifie qu'après avoir trouvé une correspondance avec le deuxième caractère du motif (un point, qui correspond au caractère à la position 6 dans le texte,
Matchervérifie si le texte correspond au reste du motif — le caractère "a"![Expressions régulières en Java - 10]()
-
Le texte ne correspond pas au motif (c'est-à-dire qu'il contient le caractère "
n" à l'index 7), doncMatcherajoute plus d'un "n'importe quel caractère", car le quantificateur en indique un ou plusieurs. Ensuite, il compare à nouveau le modèle avec le texte aux positions 5 à 8 :![Expressions régulières en Java - 11]()


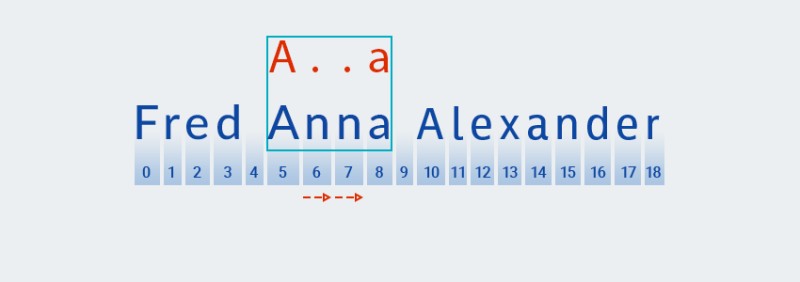
Dans notre cas, une correspondance est trouvée, mais nous n'avons pas encore atteint la fin du texte. Par conséquent, le pattern-matching recommence à partir de la position 9, c'est-à-dire que le premier caractère du pattern est recherché en utilisant un algorithme similaire et cela se répète jusqu'à la fin du texte.

mainméthode obtient le résultat suivant lors de l'utilisation du motif " A.+?a" : Anna Alexa Comme vous pouvez le voir dans notre exemple, différents types de quantificateurs produisent des résultats différents pour le même motif. Alors gardez cela à l'esprit et choisissez la bonne variété en fonction de ce que vous recherchez.Caractères d'échappement dans les expressions régulières
Étant donné qu'une expression régulière en Java, ou plutôt sa représentation d'origine, est un littéral de chaîne, nous devons tenir compte des règles Java concernant les littéraux de chaîne. En particulier, le caractère barre oblique inverse "\" dans les littéraux de chaîne du code source Java est interprété comme un caractère de contrôle qui indique au compilateur que le caractère suivant est spécial et doit être interprété d'une manière spéciale. Par exemple:
String s = "The root directory is \nWindows"; // Move "Windows" to a new line
String s = "The root directory is \u00A7Windows"; // Insert a paragraph symbol before "Windows"
\des caractères " " (c'est-à-dire pour indiquer des métacaractères) doivent répéter les barres obliques inverses pour s'assurer que le compilateur de bytecode Java n'interprète pas mal la chaîne. Par exemple:
String regex = "\\s"; // Pattern for matching a whitespace character
String regex = "\"Windows\""; // Pattern for matching "Windows"
String regex = "How\\?"; // Pattern for matching "How?"
Méthodes de la classe Pattern
LaPatternclasse a d'autres méthodes pour travailler avec des expressions régulières :
-
String pattern()‒ renvoie la représentation sous forme de chaîne d'origine de l'expression régulière utilisée pour créer l'Patternobjet :Pattern pattern = Pattern.compile("abc"); System.out.println(pattern.pattern()); // "abc" -
static boolean matches(String regex, CharSequence input)– vous permet de vérifier l'expression régulière passée en tant que regex par rapport au texte passé en tant queinput. Retour:true - si le texte correspond au modèle ;
faux - si ce n'est pas le cas ;Par exemple:
System.out.println(Pattern.matches("A.+a","Anna")); // true System.out.println(Pattern.matches("A.+a","Fred Anna Alexander")); // false -
int flags()‒ renvoie la valeur duflagsjeu de paramètres du modèle lors de la création du modèle ou 0 si le paramètre n'a pas été défini. Par exemple:Pattern pattern = Pattern.compile("abc"); System.out.println(pattern.flags()); // 0 Pattern pattern = Pattern.compile("abc",Pattern.CASE_INSENSITIVE); System.out.println(pattern.flags()); // 2 -
String[] split(CharSequence text, int limit)– divise le texte passé en unStringtableau. Lelimitparamètre indique le nombre maximum de correspondances recherchées dans le texte :- si
limit > 0‒limit-1correspond ; - si
limit < 0‒ toutes les correspondances dans le texte - si
limit = 0‒ toutes les correspondances dans le texte, les chaînes vides à la fin du tableau sont ignorées ;
Par exemple:
public static void main(String[] args) { String text = "Fred Anna Alexa"; Pattern pattern = Pattern.compile("\\s"); String[] strings = pattern.split(text,2); for (String s : strings) { System.out.println(s); } System.out.println("---------"); String[] strings1 = pattern.split(text); for (String s : strings1) { System.out.println(s); } }Sortie console :
Fred Anna Alexa --------- Fred Anna AlexaCi-dessous, nous examinerons une autre méthode de la classe utilisée pour créer un
Matcherobjet. - si
Méthodes de la classe Matcher
Des instances de laMatcherclasse sont créées pour effectuer une correspondance de modèle. Matcherest le "moteur de recherche" des expressions régulières. Pour effectuer une recherche, nous devons lui donner deux choses : un motif et un index de départ.
Pour créer un Matcherobjet, la Patternclasse fournit la méthode suivante : рublic Matcher matcher(CharSequence input) La méthode prend une séquence de caractères, qui sera recherchée. Il s'agit d'une instance d'une classe qui implémente l' CharSequenceinterface.
Vous pouvez passer non seulement un String, mais aussi un StringBuffer, StringBuilder, Segmentou CharBuffer. Le motif est un Patternobjet sur lequel la matcherméthode est appelée. Exemple de création d'un matcher :
Pattern p = Pattern.compile("a*b"); // Create a compiled representation of the regular expression
Matcher m = p.matcher("aaaaab"); // Create a "search engine" to search the text "aaaaab" for the pattern "a*b"

boolean find()méthode recherche la correspondance suivante dans le texte.
Nous pouvons utiliser cette méthode et une instruction de boucle pour analyser un texte entier dans le cadre d'un modèle d'événement. En d'autres termes, nous pouvons effectuer les opérations nécessaires lorsqu'un événement se produit, c'est-à-dire lorsque nous trouvons une correspondance dans le texte.
int start()Par exemple, nous pouvons utiliser les méthodes et de cette classe int end()pour déterminer la position d'une correspondance dans le texte. Et nous pouvons utiliser les méthodes String replaceFirst(String replacement)et String replaceAll(String replacement)pour remplacer les correspondances par la valeur du paramètre de remplacement. Par exemple:
public static void main(String[] args) {
String text = "Fred Anna Alexa";
Pattern pattern = Pattern.compile("A.+?a");
Matcher matcher = pattern.matcher(text);
while (matcher.find()) {
int start=matcher.start();
int end=matcher.end();
System.out.println("Match found: " + text.substring(start, end) + " from index "+ start + " through " + (end-1));
}
System.out.println(matcher.replaceFirst("Ira"));
System.out.println(matcher.replaceAll("Mary"));
System.out.println(text);
}
Match found: Anna from index 5 through 8
Match found: Alexa from index 10 through 14
Fred Ira Alexa
Fred Mary Mary
Fred Anna Alexa
replaceFirstet replaceAllcréent un nouvel Stringobjet - une chaîne dans laquelle les correspondances de modèle dans le texte d'origine sont remplacées par le texte passé à la méthode en tant qu'argument. De plus, la replaceFirstméthode remplace uniquement la première correspondance, mais la replaceAllméthode remplace toutes les correspondances dans le texte. Le texte original reste inchangé.
Les opérations régulières les plus fréquentes des classes Patternet sont intégrées directement dans la classe. Il s'agit de méthodes telles que , , et . Mais sous le capot, ces méthodes utilisent les classes et.
Donc, si vous voulez remplacer du texte ou comparer des chaînes dans un programme sans écrire de code supplémentaire, utilisez les méthodes duMatcherStringsplitmatchesreplaceFirstreplaceAllPatternMatcherStringclasse. Si vous avez besoin de fonctionnalités plus avancées, souvenez-vous des classes Patternet Matcher.Conclusion
Dans un programme Java, une expression régulière est définie par une chaîne qui obéit à des règles de correspondance de modèles spécifiques. Lors de l'exécution du code, la machine Java compile cette chaîne dans unPatternobjet et utilise un Matcherobjet pour trouver des correspondances dans le texte.
Comme je l'ai dit au début, les gens remettent souvent les expressions régulières à plus tard, les considérant comme un sujet difficile. Mais si vous comprenez la syntaxe de base, les métacaractères et les caractères d'échappement, et étudiez des exemples d'expressions régulières, vous constaterez qu'elles sont beaucoup plus simples qu'elles ne le paraissent à première vue.|
Plus de lecture : |
|---|
GO TO FULL VERSION