
Cos'è un'espressione regolare (regex)?
In effetti, un'espressione regolare è un modello per trovare una stringa nel testo. In Java la rappresentazione originale di questo pattern è sempre una stringa, cioè un oggetto dellaStringclasse. Tuttavia, non è una qualsiasi stringa che può essere compilata in un'espressione regolare, ma solo stringhe conformi alle regole per la creazione di espressioni regolari. La sintassi è definita nella specifica del linguaggio. Le espressioni regolari vengono scritte utilizzando lettere e numeri, nonché metacaratteri, che sono caratteri che hanno un significato speciale nella sintassi delle espressioni regolari. Per esempio:
String regex = "java"; // The pattern is "java";
String regex = "\\d{3}"; // The pattern is three digits;
Creazione di espressioni regolari in Java
La creazione di un'espressione regolare in Java comporta due semplici passaggi:- scriverlo come una stringa conforme alla sintassi delle espressioni regolari;
- compilare la stringa in un'espressione regolare;
Patternoggetto. Per fare ciò, dobbiamo chiamare uno dei due metodi statici della classe: compile. Il primo metodo accetta un argomento, una stringa letterale contenente l'espressione regolare, mentre il secondo accetta un argomento aggiuntivo che determina le impostazioni di corrispondenza del modello:
public static Pattern compile (String literal)
public static Pattern compile (String literal, int flags)
flagsparametro è definito in Patternclass ed è a nostra disposizione come variabili di classe statiche. Per esempio:
Pattern pattern = Pattern.compile("java", Pattern.CASE_INSENSITIVE); // Pattern-matching will be case insensitive.
Patternclasse è un costruttore per espressioni regolari. Sotto il cofano, il compilemetodo chiama il Patterncostruttore privato della classe per creare una rappresentazione compilata. Questo meccanismo di creazione di oggetti è implementato in questo modo per creare oggetti immutabili. Quando viene creata un'espressione regolare, la sua sintassi viene verificata. Se la stringa contiene errori, PatternSyntaxExceptionviene generato a.
Sintassi delle espressioni regolari
La sintassi delle espressioni regolari si basa sui<([{\^-=$!|]})?*+.>caratteri, che possono essere combinati con le lettere. A seconda del loro ruolo, possono essere suddivisi in diversi gruppi:
| Metacarattere | Descrizione |
|---|---|
| ^ | inizio di una riga |
| $ | fine di una riga |
| \B | confine di parola |
| \B | confine non verbale |
| \UN | inizio dell'input |
| \G | fine della partita precedente |
| \Z | fine dell'input |
| \z | fine dell'input |
| Metacarattere | Descrizione |
|---|---|
| \D | cifra |
| \D | non cifra |
| \S | carattere di spazio bianco |
| \S | carattere non spaziato |
| \w | carattere alfanumerico o underscore |
| \W | qualsiasi carattere tranne lettere, numeri e trattino basso |
| . | qualsiasi personaggio |

| Metacarattere | Descrizione |
|---|---|
| \T | carattere di tabulazione |
| \N | carattere di nuova riga |
| \R | ritorno a capo |
| \F | carattere di avanzamento riga |
| \u0085 | carattere della riga successiva |
| \u2028 | separatore di riga |
| \u2029 | separatore di paragrafo |
| Metacarattere | Descrizione |
|---|---|
| [abc] | uno qualsiasi dei caratteri elencati (a, b o c) |
| [^abc] | qualsiasi carattere diverso da quelli elencati (non a, b o c) |
| [a-zA-Z] | intervalli uniti (caratteri latini dalla a alla z, senza distinzione tra maiuscole e minuscole) |
| [annuncio[mp]] | unione di caratteri (da a a d e da m a p) |
| [az&&[def]] | intersezione di caratteri (d, e, f) |
| [az&&[^bc]] | sottrazione di caratteri (a, dz) |
| Metacarattere | Descrizione |
|---|---|
| ? | uno o nessuno |
| * | zero o più volte |
| + | una o più volte |
| {N} | n volte |
| {N,} | n o più volte |
| {m} | almeno n volte e non più di m volte |
Quantificatori avidi
Una cosa che dovresti sapere sui quantificatori è che sono disponibili in tre diverse varietà: avidi, possessivi e riluttanti. Rendi possessivo un quantificatore aggiungendo un+carattere " " dopo il quantificatore. Lo rendi riluttante aggiungendo " ?". Per esempio:
"A.+a" // greedy
"A.++a" // possessive
"A.+?a" // reluctant
public static void main(String[] args) {
String text = "Fred Anna Alexander";
Pattern pattern = Pattern.compile("A.+a");
Matcher matcher = pattern.matcher(text);
while (matcher.find()) {
System.out.println(text.substring(matcher.start(), matcher.end()));
}
}
Anna Alexa
A.+a", la corrispondenza del modello viene eseguita come segue:
-
Il primo carattere nel modello specificato è la lettera latina
A.Matcherlo confronta con ogni carattere del testo, partendo dall'indice zero. Il carattereFè all'indice zero nel nostro testo, quindiMatcherscorre i caratteri fino a quando non corrisponde al modello. Nel nostro esempio, questo carattere si trova all'indice 5.![Espressioni regolari in Java - 2]()
-
Una volta trovata una corrispondenza con il primo carattere del modello,
Matchercerca una corrispondenza con il suo secondo carattere. Nel nostro caso, è il.carattere " ", che rappresenta qualsiasi carattere.![Espressioni regolari in Java - 3]()
Il personaggio
nè in sesta posizione. Certamente si qualifica come corrispondenza per "qualsiasi personaggio". -
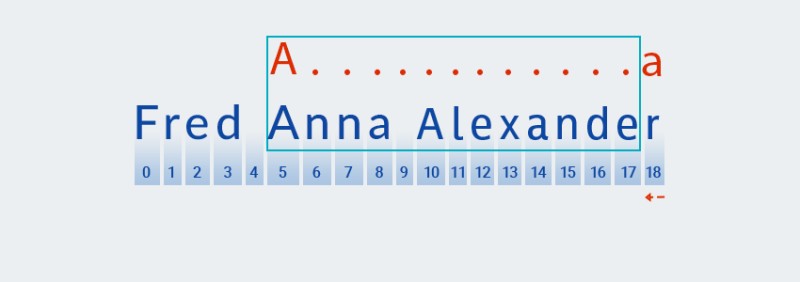
Matcherprocede a controllare il carattere successivo del motivo. Nel nostro modello, è incluso nel quantificatore che si applica al carattere precedente: ".+". Poiché il numero di ripetizioni di "qualsiasi carattere" nel nostro modello è una o più volte,Matcherripetutamente prende il carattere successivo dalla stringa e lo confronta con il modello finché corrisponde a "qualsiasi carattere". Nel nostro esempio, fino alla fine della stringa (dall'indice 7 all'indice 18).![Espressioni regolari in Java - 4]()
Fondamentalmente,
Matcherdivora la corda fino alla fine - questo è esattamente ciò che si intende per "avido". -
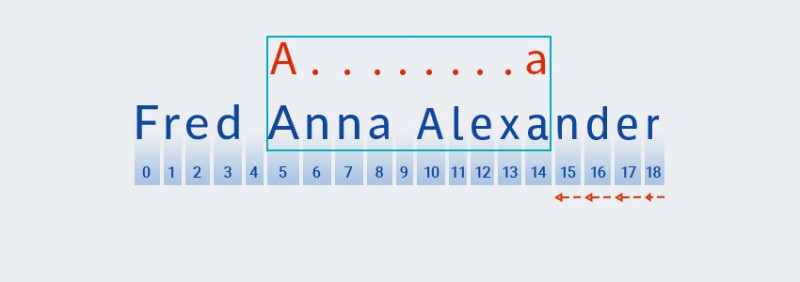
Dopo che Matcher raggiunge la fine del testo e termina il controllo per la
A.+parte " " del pattern, inizia a controllare il resto del pattern:a. Non c'è più testo in avanti, quindi il controllo procede "arretrando", partendo dall'ultimo carattere:![Espressioni regolari in Java - 5]()
-
Matcher"ricorda" il numero di ripetizioni nella.+parte " " dello schema. A questo punto, riduce il numero di ripetizioni di uno e confronta il modello più grande con il testo finché non trova una corrispondenza:![Espressioni regolari in Java - 6]()



Quantificatori possessivi
I quantificatori possessivi sono molto simili a quelli avidi. La differenza è che quando il testo è stato catturato fino alla fine della stringa, non c'è corrispondenza di modello durante il "ritiro". In altre parole, le prime tre fasi sono le stesse dei quantificatori avidi. Dopo aver catturato l'intera stringa, il matcher aggiunge il resto del modello a ciò che sta considerando e lo confronta con la stringa catturata. Nel nostro esempio, utilizzando l'espressione regolare "A.++a", il metodo main non trova corrispondenze. 
Quantificatori riluttanti
-
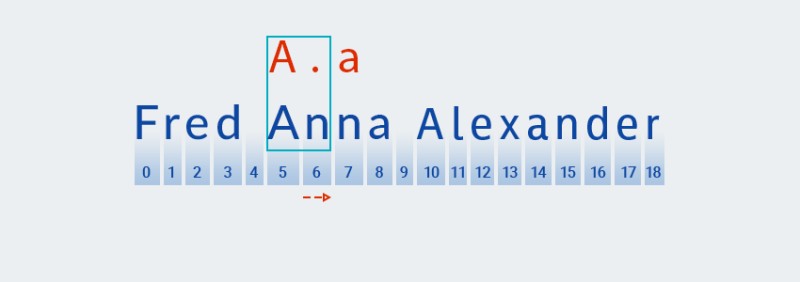
Per questi quantificatori, come per la varietà greedy, il codice cerca una corrispondenza basata sul primo carattere del pattern:
![Espressioni regolari in Java - 8]()
-
Quindi cerca una corrispondenza con il carattere successivo del modello (qualsiasi carattere):
![Espressioni regolari in Java - 9]()
-
A differenza del greedy pattern-matching, nel riluttante pattern-matching viene cercata la corrispondenza più breve. Ciò significa che dopo aver trovato una corrispondenza con il secondo carattere del pattern (un punto, che corrisponde al carattere alla posizione 6 nel testo,
Matchercontrolla se il testo corrisponde al resto del pattern — il carattere "a"![Espressioni regolari in Java - 10]()
-
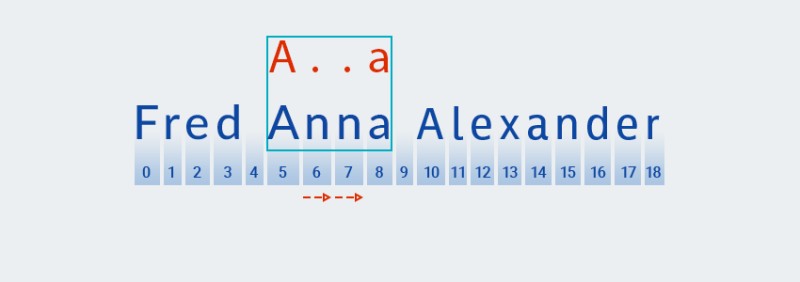
Il testo non corrisponde al modello (cioè contiene il carattere " "
nall'indice 7), quindiMatcheraggiunge più un "qualsiasi carattere", perché il quantificatore ne indica uno o più. Quindi confronta nuovamente lo schema con il testo nelle posizioni da 5 a 8:![Espressioni regolari in Java - 11]()


Nel nostro caso viene trovata una corrispondenza, ma non siamo ancora arrivati alla fine del testo. Pertanto, il pattern-matching riparte dalla posizione 9, cioè il primo carattere del pattern viene cercato utilizzando un algoritmo simile e questo si ripete fino alla fine del testo.

mainmetodo ottiene il seguente risultato quando si utilizza il modello " A.+?a": Anna Alexa Come puoi vedere dal nostro esempio, diversi tipi di quantificatori producono risultati diversi per lo stesso modello. Quindi tienilo a mente e scegli la varietà giusta in base a ciò che stai cercando.
Caratteri di escape nelle espressioni regolari
Poiché un'espressione regolare in Java, o meglio, la sua rappresentazione originale, è una stringa letterale, dobbiamo tenere conto delle regole Java relative alle stringhe letterali. In particolare, il carattere backslash "\" nei valori letterali stringa nel codice sorgente Java viene interpretato come un carattere di controllo che indica al compilatore che il carattere successivo è speciale e deve essere interpretato in modo speciale. Per esempio:
String s = "The root directory is \nWindows"; // Move "Windows" to a new line
String s = "The root directory is \u00A7Windows"; // Insert a paragraph symbol before "Windows"
\caratteri " " (ovvero per indicare metacaratteri) devono ripetere le barre rovesciate per garantire che il compilatore di bytecode Java non interpreti erroneamente la stringa. Per esempio:
String regex = "\\s"; // Pattern for matching a whitespace character
String regex = "\"Windows\""; // Pattern for matching "Windows"
String regex = "How\\?"; // Pattern for matching "How?"
Metodi della classe Pattern
LaPatternclasse ha altri metodi per lavorare con le espressioni regolari:
-
String pattern()‒ restituisce la rappresentazione di stringa originale dell'espressione regolare usata per creare l'Patternoggetto:Pattern pattern = Pattern.compile("abc"); System.out.println(pattern.pattern()); // "abc" -
static boolean matches(String regex, CharSequence input)– consente di confrontare l'espressione regolare passata come regex con il testo passato comeinput. Ritorna:true – se il testo corrisponde al modello;
falso - se non lo fa;Per esempio:
System.out.println(Pattern.matches("A.+a","Anna")); // true System.out.println(Pattern.matches("A.+a","Fred Anna Alexander")); // false -
int flags()‒ restituisce il valore delflagsparametro del modello impostato quando il modello è stato creato o 0 se il parametro non è stato impostato. Per esempio:Pattern pattern = Pattern.compile("abc"); System.out.println(pattern.flags()); // 0 Pattern pattern = Pattern.compile("abc",Pattern.CASE_INSENSITIVE); System.out.println(pattern.flags()); // 2 -
String[] split(CharSequence text, int limit)– divide il testo passato in unStringarray. Illimitparametro indica il numero massimo di corrispondenze cercate nel testo:- se
limit > 0‒limit-1corrisponde; - if
limit < 0‒ tutte le corrispondenze nel testo - se
limit = 0‒ tutte le corrispondenze nel testo, le stringhe vuote alla fine dell'array vengono scartate;
Per esempio:
public static void main(String[] args) { String text = "Fred Anna Alexa"; Pattern pattern = Pattern.compile("\\s"); String[] strings = pattern.split(text,2); for (String s : strings) { System.out.println(s); } System.out.println("---------"); String[] strings1 = pattern.split(text); for (String s : strings1) { System.out.println(s); } }Uscita console:
Fred Anna Alexa --------- Fred Anna AlexaDi seguito considereremo un altro dei metodi della classe utilizzati per creare un
Matcheroggetto. - se
Metodi della classe Matcher
Le istanze dellaMatcherclasse vengono create per eseguire la corrispondenza dei modelli. Matcherè il "motore di ricerca" per le espressioni regolari. Per eseguire una ricerca, dobbiamo fornirle due cose: uno schema e un indice di partenza. Per creare un Matcheroggetto, la Patternclasse fornisce il seguente metodo: рublic Matcher matcher(CharSequence input) Il metodo prende una sequenza di caratteri, che verrà cercata. Questa è un'istanza di una classe che implementa l' CharSequenceinterfaccia. Puoi passare non solo a String, ma anche a StringBuffer, StringBuilder, Segmento CharBuffer. Il modello è un Patternoggetto su cui matcherviene chiamato il metodo. Esempio di creazione di un matcher:

Pattern p = Pattern.compile("a*b"); // Create a compiled representation of the regular expression
Matcher m = p.matcher("aaaaab"); // Create a "search engine" to search the text "aaaaab" for the pattern "a*b"
boolean find()metodo cerca la corrispondenza successiva nel testo. Possiamo utilizzare questo metodo e un'istruzione loop per analizzare un intero testo come parte di un modello di eventi. In altre parole, possiamo eseguire le operazioni necessarie quando si verifica un evento, cioè quando troviamo una corrispondenza nel testo. Ad esempio, possiamo utilizzare i metodi int start()e di questa classe int end()per determinare la posizione di una corrispondenza nel testo. E possiamo usare i metodi String replaceFirst(String replacement)e String replaceAll(String replacement)per sostituire le corrispondenze con il valore del parametro di sostituzione. Per esempio:
public static void main(String[] args) {
String text = "Fred Anna Alexa";
Pattern pattern = Pattern.compile("A.+?a");
Matcher matcher = pattern.matcher(text);
while (matcher.find()) {
int start=matcher.start();
int end=matcher.end();
System.out.println("Match found: " + text.substring(start, end) + " from index "+ start + " through " + (end-1));
}
System.out.println(matcher.replaceFirst("Ira"));
System.out.println(matcher.replaceAll("Mary"));
System.out.println(text);
}
Match found: Anna from index 5 through 8
Match found: Alexa from index 10 through 14
Fred Ira Alexa
Fred Mary Mary
Fred Anna Alexa
replaceFirste replaceAllcreano un nuovo Stringoggetto, una stringa in cui le corrispondenze di pattern nel testo originale vengono sostituite dal testo passato al metodo come argomento. Inoltre, il replaceFirstmetodo sostituisce solo la prima corrispondenza, ma il replaceAllmetodo sostituisce tutte le corrispondenze nel testo. Il testo originale rimane invariato. Le operazioni regex più frequenti delle classi Patterne Matchersono incorporate direttamente nella Stringclasse. Questi sono metodi come split, matches, replaceFirste replaceAll. Ma sotto il cofano, questi metodi usano le classi Patterne Matcher. Quindi, se vuoi sostituire il testo o confrontare le stringhe in un programma senza scrivere alcun codice aggiuntivo, usa i metodi delStringclasse. Se hai bisogno di funzionalità più avanzate, ricorda le classi Patterne Matcher.
Conclusione
In un programma Java, un'espressione regolare è definita da una stringa che obbedisce a specifiche regole di corrispondenza dei modelli. Durante l'esecuzione del codice, la macchina Java compila questa stringa in unPatternoggetto e utilizza un Matcheroggetto per trovare corrispondenze nel testo. Come ho detto all'inizio, le persone spesso rimandano le espressioni regolari a dopo, considerandole un argomento difficile. Ma se capisci la sintassi di base, i metacaratteri e l'escape dei caratteri e studi esempi di espressioni regolari, scoprirai che sono molto più semplici di quanto sembri a prima vista.
|
Altre letture: |
|---|
GO TO FULL VERSION