
సాధారణ వ్యక్తీకరణ (రెజెక్స్) అంటే ఏమిటి?
వాస్తవానికి, సాధారణ వ్యక్తీకరణ అనేది టెక్స్ట్లో స్ట్రింగ్ను కనుగొనడానికి ఒక నమూనా. జావాలో, ఈ నమూనా యొక్క అసలైన ప్రాతినిధ్యం ఎల్లప్పుడూ స్ట్రింగ్గా ఉంటుంది, అనగా తరగతికి సంబంధించిన వస్తువుString. అయితే, ఇది సాధారణ వ్యక్తీకరణగా కంపైల్ చేయబడే స్ట్రింగ్ కాదు - సాధారణ వ్యక్తీకరణలను సృష్టించే నియమాలకు అనుగుణంగా ఉండే స్ట్రింగ్లు మాత్రమే. సింటాక్స్ భాష స్పెసిఫికేషన్లో నిర్వచించబడింది. రెగ్యులర్ వ్యక్తీకరణలు అక్షరాలు మరియు సంఖ్యలను ఉపయోగించి వ్రాయబడతాయి, అలాగే మెటాక్యారెక్టర్లు, ఇవి సాధారణ వ్యక్తీకరణ వాక్యనిర్మాణంలో ప్రత్యేక అర్ధాన్ని కలిగి ఉంటాయి. ఉదాహరణకి:
String regex = "java"; // The pattern is "java";
String regex = "\\d{3}"; // The pattern is three digits;
జావాలో సాధారణ వ్యక్తీకరణలను సృష్టిస్తోంది
జావాలో సాధారణ వ్యక్తీకరణను సృష్టించడం రెండు సాధారణ దశలను కలిగి ఉంటుంది:- సాధారణ వ్యక్తీకరణ సింటాక్స్కు అనుగుణంగా ఉండే స్ట్రింగ్గా వ్రాయండి;
- స్ట్రింగ్ను సాధారణ వ్యక్తీకరణలో కంపైల్ చేయండి;
Pattern. దీన్ని చేయడానికి, మేము తరగతి యొక్క రెండు స్టాటిక్ పద్ధతుల్లో ఒకదానిని కాల్ చేయాలి: compile. మొదటి పద్ధతి ఒక ఆర్గ్యుమెంట్ తీసుకుంటుంది — సాధారణ వ్యక్తీకరణను కలిగి ఉండే స్ట్రింగ్ అక్షరార్థం, రెండవది నమూనా-సరిపోలిక సెట్టింగ్లను నిర్ణయించే అదనపు ఆర్గ్యుమెంట్ను తీసుకుంటుంది:
public static Pattern compile (String literal)
public static Pattern compile (String literal, int flags)
flagsనిర్వచించబడింది Patternమరియు స్టాటిక్ క్లాస్ వేరియబుల్స్గా మాకు అందుబాటులో ఉంటుంది. ఉదాహరణకి:
Pattern pattern = Pattern.compile("java", Pattern.CASE_INSENSITIVE); // Pattern-matching will be case insensitive.
Patternతరగతి సాధారణ వ్యక్తీకరణల కోసం ఒక కన్స్ట్రక్టర్. హుడ్ కింద, కంపైల్డ్ ప్రాతినిధ్యాన్ని సృష్టించడానికి compileపద్ధతి తరగతి యొక్క ప్రైవేట్ కన్స్ట్రక్టర్ని పిలుస్తుంది . Patternఈ వస్తువు-సృష్టి విధానం మార్పులేని వస్తువులను సృష్టించడానికి ఈ విధంగా అమలు చేయబడుతుంది. సాధారణ వ్యక్తీకరణ సృష్టించబడినప్పుడు, దాని వాక్యనిర్మాణం తనిఖీ చేయబడుతుంది. స్ట్రింగ్ లోపాలను కలిగి ఉంటే, అప్పుడు a PatternSyntaxExceptionసృష్టించబడుతుంది.
సాధారణ వ్యక్తీకరణ సింటాక్స్
రెగ్యులర్ ఎక్స్ప్రెషన్ సింటాక్స్ అక్షరాలపై ఆధారపడి ఉంటుంది<([{\^-=$!|]})?*+.>, వీటిని అక్షరాలతో కలపవచ్చు. వారి పాత్రపై ఆధారపడి, వాటిని అనేక సమూహాలుగా విభజించవచ్చు:
| మెటాక్యారెక్టర్ | వివరణ |
|---|---|
| ^ | ఒక లైన్ ప్రారంభం |
| $ | ఒక లైన్ ముగింపు |
| \b | పదం సరిహద్దు |
| \B | పదం కాని సరిహద్దు |
| \A | ఇన్పుట్ ప్రారంభం |
| \G | మునుపటి మ్యాచ్ ముగింపు |
| \Z | ఇన్పుట్ ముగింపు |
| \z | ఇన్పుట్ ముగింపు |
| మెటాక్యారెక్టర్ | వివరణ |
|---|---|
| \d | అంకె |
| \D | అంకెలు లేని |
| \s | ఖాళీ పాత్ర |
| \S | నాన్-వైట్స్పేస్ క్యారెక్టర్ |
| \w | ఆల్ఫాన్యూమరిక్ అక్షరం లేదా అండర్ స్కోర్ |
| \W | అక్షరాలు, సంఖ్యలు మరియు అండర్స్కోర్ మినహా ఏదైనా అక్షరం |
| . | ఏదైనా పాత్ర |

| మెటాక్యారెక్టర్ | వివరణ |
|---|---|
| \t | ట్యాబ్ అక్షరం |
| \n | కొత్త లైన్ పాత్ర |
| \r | క్యారేజ్ రిటర్న్ |
| \f | లైన్ఫీడ్ పాత్ర |
| \u0085 | తదుపరి వరుస పాత్ర |
| \u2028 | లైన్ సెపరేటర్ |
| \u2029 | పేరా వేరు |
| మెటాక్యారెక్టర్ | వివరణ |
|---|---|
| [abc] | జాబితా చేయబడిన అక్షరాలలో ఏదైనా (a, b, లేదా c) |
| [^abc] | జాబితా చేయబడినవి కాకుండా ఏదైనా అక్షరం (a, b లేదా c కాదు) |
| [a-zA-Z] | విలీన పరిధులు (a నుండి z వరకు లాటిన్ అక్షరాలు, కేస్ సెన్సిటివ్) |
| [ad[mp]] | అక్షరాల కలయిక (a నుండి d వరకు మరియు m నుండి p వరకు) |
| [az&&[def]] | అక్షరాల ఖండన (d, e, f) |
| [az&&[^bc]] | అక్షరాల వ్యవకలనం (a, dz) |
| మెటాక్యారెక్టర్ | వివరణ |
|---|---|
| ? | ఒకటి లేదా ఏదీ కాదు |
| * | సున్నా లేదా అంతకంటే ఎక్కువ సార్లు |
| + | ఒకటి లేదా అంతకంటే ఎక్కువ సార్లు |
| {n} | n సార్లు |
| {n,} | n లేదా అంతకంటే ఎక్కువ సార్లు |
| {n,m} | కనీసం n సార్లు మరియు m కంటే ఎక్కువ సార్లు కాదు |
అత్యాశ పరిమాణాలు
క్వాంటిఫైయర్ల గురించి మీరు తెలుసుకోవలసిన ఒక విషయం ఏమిటంటే అవి మూడు వేర్వేరు రకాలుగా వస్తాయి: అత్యాశ, స్వాధీనత మరియు అయిష్టం.+మీరు క్వాంటిఫైయర్ తర్వాత " " అక్షరాన్ని జోడించడం ద్వారా క్వాంటిఫైయర్ను స్వాధీనపరుస్తుంది . మీరు "" జోడించడం ద్వారా దానిని అయిష్టంగా చేస్తారు ?. ఉదాహరణకి:
"A.+a" // greedy
"A.++a" // possessive
"A.+?a" // reluctant
public static void main(String[] args) {
String text = "Fred Anna Alexander";
Pattern pattern = Pattern.compile("A.+a");
Matcher matcher = pattern.matcher(text);
while (matcher.find()) {
System.out.println(text.substring(matcher.start(), matcher.end()));
}
}
Anna Alexa
A.+a" కోసం, నమూనా-సరిపోలిక క్రింది విధంగా నిర్వహించబడుతుంది:
-
పేర్కొన్న నమూనాలో మొదటి అక్షరం లాటిన్ అక్షరం
A.Matcherఇండెక్స్ జీరో నుండి ప్రారంభించి, టెక్స్ట్లోని ప్రతి అక్షరంతో పోల్చింది. అక్షరంFమా టెక్స్ట్లో ఇండెక్స్ జీరో వద్ద ఉంది, కనుకMatcherఇది నమూనాతో సరిపోలే వరకు అక్షరాల ద్వారా పునరావృతమవుతుంది. మా ఉదాహరణలో, ఈ అక్షరం ఇండెక్స్ 5లో కనుగొనబడింది.![జావాలో సాధారణ వ్యక్తీకరణలు - 2]()
-
నమూనా యొక్క మొదటి అక్షరంతో సరిపోలిక కనుగొనబడిన తర్వాత,
Matcherదాని రెండవ అక్షరంతో సరిపోలిక కోసం చూస్తుంది. మా విషయంలో, ఇది "." పాత్ర, ఇది ఏదైనా పాత్రను సూచిస్తుంది.![జావాలో సాధారణ వ్యక్తీకరణలు - 3]()
పాత్ర
nఆరవ స్థానంలో ఉంది. ఇది ఖచ్చితంగా "ఏదైనా క్యారెక్టర్"కి సరిపోయేలా అర్హత పొందుతుంది. -
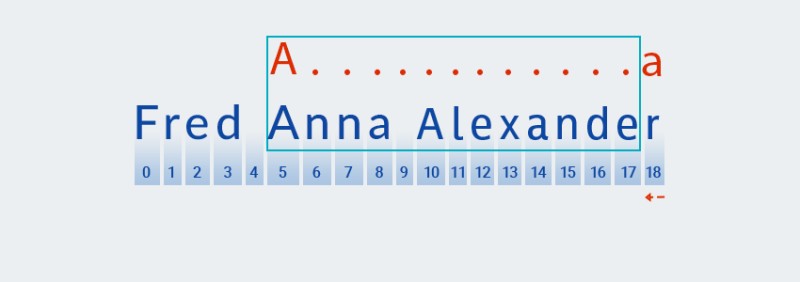
Matcherనమూనా యొక్క తదుపరి అక్షరాన్ని తనిఖీ చేయడానికి కొనసాగుతుంది. మా నమూనాలో, ఇది మునుపటి అక్షరానికి వర్తించే క్వాంటిఫైయర్లో చేర్చబడింది: ".+". మా నమూనాలో "ఏదైనా అక్షరం" యొక్క పునరావృతాల సంఖ్య ఒకటి లేదా అంతకంటే ఎక్కువ సార్లు ఉన్నందున,Matcherపదేపదే స్ట్రింగ్ నుండి తదుపరి అక్షరాన్ని తీసుకుంటుంది మరియు అది "ఏదైనా అక్షరం"తో సరిపోలినంత వరకు దానిని నమూనాకు వ్యతిరేకంగా తనిఖీ చేస్తుంది. మా ఉదాహరణలో — స్ట్రింగ్ చివరి వరకు (ఇండెక్స్ 7 నుండి ఇండెక్స్ 18 వరకు).![జావాలో సాధారణ వ్యక్తీకరణలు - 4]()
ప్రాథమికంగా,
Matcherస్ట్రింగ్ను చివరి వరకు గాబుల్ చేయండి — ఇది ఖచ్చితంగా "అత్యాశ" అంటే అర్థం. -
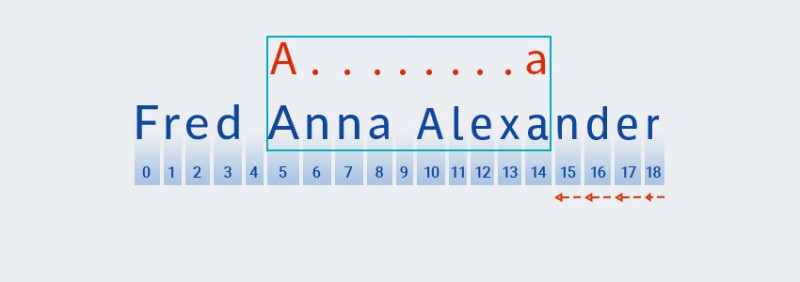
మ్యాచర్ టెక్స్ట్ ముగింపుకు చేరుకున్న తర్వాత మరియు నమూనా యొక్క "" భాగం కోసం తనిఖీని పూర్తి చేసిన తర్వాత
A.+, అది మిగిలిన నమూనా కోసం తనిఖీ చేయడం ప్రారంభిస్తుంది:a. ముందుకు వెళ్లే వచనం లేదు, కాబట్టి చెక్ చివరి అక్షరం నుండి ప్రారంభించి "బ్యాకింగ్ ఆఫ్" ద్వారా కొనసాగుతుంది:![జావాలో సాధారణ వ్యక్తీకరణలు - 5]()
-
Matcher.+నమూనా యొక్క " " భాగంలో పునరావృతాల సంఖ్యను "గుర్తుంచుకుంటుంది" . ఈ సమయంలో, ఇది పునరావృతాల సంఖ్యను ఒకదానితో ఒకటి తగ్గిస్తుంది మరియు సరిపోలిక కనుగొనబడే వరకు వచనానికి వ్యతిరేకంగా పెద్ద నమూనాను తనిఖీ చేస్తుంది:![జావాలో సాధారణ వ్యక్తీకరణలు - 6]()



పొసెసివ్ క్వాంటిఫైయర్స్
పొసెసివ్ క్వాంటిఫైయర్లు చాలా అత్యాశతో ఉంటాయి. వ్యత్యాసం ఏమిటంటే, టెక్స్ట్ స్ట్రింగ్ చివరి వరకు క్యాప్చర్ చేయబడినప్పుడు, "బ్యాకింగ్ ఆఫ్" అయితే నమూనా-సరిపోలిక ఉండదు. మరో మాటలో చెప్పాలంటే, మొదటి మూడు దశలు అత్యాశతో కూడిన క్వాంటిఫైయర్ల మాదిరిగానే ఉంటాయి. మొత్తం స్ట్రింగ్ను క్యాప్చర్ చేసిన తర్వాత, మ్యాచర్ మిగిలిన ప్యాటర్న్ని అది పరిశీలిస్తున్నదానికి జోడిస్తుంది మరియు క్యాప్చర్ చేసిన స్ట్రింగ్తో పోలుస్తుంది. మా ఉదాహరణలో, సాధారణ వ్యక్తీకరణ "A.++a"ని ఉపయోగించి, ప్రధాన పద్ధతికి సరిపోలలేదు. 
రిలక్టెంట్ క్వాంటిఫైయర్స్
-
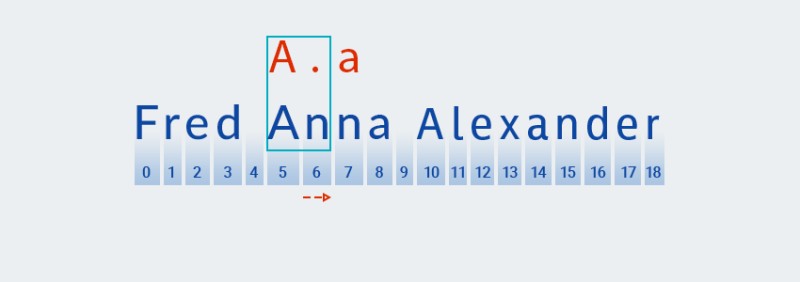
ఈ క్వాంటిఫైయర్ల కోసం, అత్యాశతో కూడిన రకాలు వలె, కోడ్ నమూనా యొక్క మొదటి అక్షరం ఆధారంగా సరిపోలిక కోసం చూస్తుంది:
![జావాలో సాధారణ వ్యక్తీకరణలు - 8]()
-
అప్పుడు అది నమూనా యొక్క తదుపరి అక్షరంతో (ఏదైనా అక్షరమైనా) సరిపోలిక కోసం చూస్తుంది:
![జావాలో సాధారణ వ్యక్తీకరణలు - 9]()
-
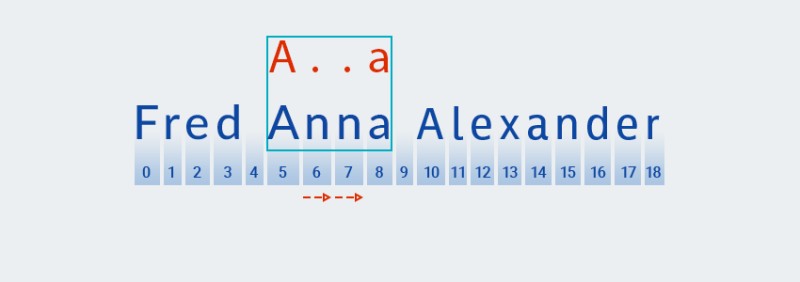
అత్యాశతో కూడిన నమూనా-సరిపోలిక వలె కాకుండా, అయిష్టమైన నమూనా-సరిపోలికలో అతి తక్కువ సరిపోలిక కోసం శోధించబడుతుంది. దీనర్థం, నమూనా యొక్క రెండవ అక్షరంతో సరిపోలికను కనుగొన్న తర్వాత (టెక్స్ట్లో 6వ స్థానంలో ఉన్న అక్షరానికి అనుగుణంగా ఉండే కాలం,
Matcherటెక్స్ట్ మిగిలిన నమూనాతో సరిపోలుతుందో లేదో తనిఖీ చేస్తుంది — అక్షరం "a"![జావాలో సాధారణ వ్యక్తీకరణలు - 10]()
-
టెక్స్ట్ నమూనాతో సరిపోలడం లేదు (అనగా ఇది సూచిక 7 వద్ద " " అక్షరాన్ని కలిగి ఉంటుంది
n), కాబట్టిMatcherక్వాంటిఫైయర్ ఒకటి లేదా అంతకంటే ఎక్కువ సూచిస్తుంది కాబట్టి ఎక్కువ ఒకటి "ఏదైనా అక్షరం" జోడిస్తుంది. అది మళ్లీ 5 నుండి 8 స్థానాల్లోని టెక్స్ట్తో నమూనాను పోలుస్తుంది:![జావాలో సాధారణ వ్యక్తీకరణలు - 11]()


మా విషయంలో, ఒక సరిపోలిక కనుగొనబడింది, కానీ మేము ఇంకా టెక్స్ట్ ముగింపుకు చేరుకోలేదు. అందువల్ల, నమూనా-మ్యాచింగ్ స్థానం 9 నుండి పునఃప్రారంభించబడుతుంది, అనగా నమూనా యొక్క మొదటి అక్షరం సారూప్య అల్గారిథమ్ను ఉపయోగించడం కోసం శోధించబడుతుంది మరియు ఇది వచనం ముగిసే వరకు పునరావృతమవుతుంది.

main"" నమూనాను ఉపయోగిస్తున్నప్పుడు పద్ధతి క్రింది ఫలితాన్ని పొందుతుంది A.+?a: అన్నా అలెక్సా మా ఉదాహరణ నుండి మీరు చూడగలిగినట్లుగా, వివిధ రకాల క్వాంటిఫైయర్లు ఒకే నమూనా కోసం విభిన్న ఫలితాలను ఉత్పత్తి చేస్తాయి. కాబట్టి దీన్ని గుర్తుంచుకోండి మరియు మీరు వెతుకుతున్న దాని ఆధారంగా సరైన రకాన్ని ఎంచుకోండి.
రెగ్యులర్ ఎక్స్ప్రెషన్స్లో పాత్రలు తప్పించుకోవడం
జావాలో రెగ్యులర్ ఎక్స్ప్రెషన్ లేదా దాని అసలు ప్రాతినిధ్యం స్ట్రింగ్ లిటరల్ అయినందున, స్ట్రింగ్ లిటరల్స్కు సంబంధించి జావా నియమాలను మనం పరిగణనలోకి తీసుకోవాలి. ప్రత్యేకించి,\జావా సోర్స్ కోడ్లోని స్ట్రింగ్ లిటరల్స్లోని బ్యాక్స్లాష్ క్యారెక్టర్ "" కంట్రోల్ క్యారెక్టర్గా అన్వయించబడుతుంది, ఇది కంపైలర్కు తదుపరి అక్షరం ప్రత్యేకమైనదని మరియు ప్రత్యేక పద్ధతిలో అర్థం చేసుకోవాలి. ఉదాహరణకి:
String s = "The root directory is \nWindows"; // Move "Windows" to a new line
String s = "The root directory is \u00A7Windows"; // Insert a paragraph symbol before "Windows"
\జావా బైట్కోడ్ కంపైలర్ స్ట్రింగ్ను తప్పుగా అర్థం చేసుకోకుండా ఉండటానికి " " అక్షరాలను (అంటే మెటాక్యారెక్టర్లను సూచించడానికి) ఉపయోగించే స్ట్రింగ్ లిటరల్స్ తప్పనిసరిగా బ్యాక్స్లాష్లను పునరావృతం చేయాలి. ఉదాహరణకి:
String regex = "\\s"; // Pattern for matching a whitespace character
String regex = "\"Windows\""; // Pattern for matching "Windows"
String regex = "How\\?"; // Pattern for matching "How?"
నమూనా తరగతి యొక్క పద్ధతులు
Patternసాధారణ వ్యక్తీకరణలతో పని చేయడానికి తరగతికి ఇతర పద్ధతులు ఉన్నాయి :
-
String pattern()‒ ఆబ్జెక్ట్ను రూపొందించడానికి ఉపయోగించిన సాధారణ వ్యక్తీకరణ యొక్క అసలైన స్ట్రింగ్ ప్రాతినిధ్యాన్ని అందిస్తుందిPattern:Pattern pattern = Pattern.compile("abc"); System.out.println(pattern.pattern()); // "abc" -
static boolean matches(String regex, CharSequence input)- గా పాస్ చేసిన టెక్స్ట్కు వ్యతిరేకంగా రీజెక్స్గా పాస్ చేసిన సాధారణ వ్యక్తీకరణను తనిఖీ చేయడానికి మిమ్మల్ని అనుమతిస్తుందిinput. రిటర్న్స్:నిజం - టెక్స్ట్ నమూనాతో సరిపోలితే;
తప్పుడు – అలా చేయకపోతే;ఉదాహరణకి:
System.out.println(Pattern.matches("A.+a","Anna")); // true System.out.println(Pattern.matches("A.+a","Fred Anna Alexander")); // false -
int flags()flags‒ నమూనా సృష్టించబడినప్పుడు నమూనా యొక్క పరామితి సెట్ విలువను లేదా పరామితి సెట్ చేయకపోతే 0ని అందిస్తుంది . ఉదాహరణకి:Pattern pattern = Pattern.compile("abc"); System.out.println(pattern.flags()); // 0 Pattern pattern = Pattern.compile("abc",Pattern.CASE_INSENSITIVE); System.out.println(pattern.flags()); // 2 -
String[] split(CharSequence text, int limit)- పాస్ చేసిన వచనాన్ని శ్రేణిగా విభజిస్తుందిString. పారామితిlimitటెక్స్ట్లో శోధించిన గరిష్ట సంఖ్యలో సరిపోలికలను సూచిస్తుంది:- ఒకవేళ
limit > 0-limit-1సరిపోలితే; - ఒకవేళ
limit < 0‒ టెక్స్ట్లోని అన్ని మ్యాచ్లు - ‒ టెక్స్ట్లోని అన్ని మ్యాచ్లు ఉంటే
limit = 0, శ్రేణి చివరిలో ఖాళీ స్ట్రింగ్లు విస్మరించబడతాయి;
ఉదాహరణకి:
public static void main(String[] args) { String text = "Fred Anna Alexa"; Pattern pattern = Pattern.compile("\\s"); String[] strings = pattern.split(text,2); for (String s : strings) { System.out.println(s); } System.out.println("---------"); String[] strings1 = pattern.split(text); for (String s : strings1) { System.out.println(s); } }కన్సోల్ అవుట్పుట్:
Fred Anna Alexa --------- Fred Anna Alexaఆబ్జెక్ట్ను రూపొందించడానికి ఉపయోగించే తరగతి యొక్క మరొక పద్ధతులను మేము క్రింద పరిశీలిస్తాము
Matcher. - ఒకవేళ
మ్యాచర్ క్లాస్ యొక్క పద్ధతులు
ప్యాటర్న్-మ్యాచింగ్ చేయడానికి క్లాస్ యొక్క ఉదాహరణలుMatcherసృష్టించబడ్డాయి. Matcherసాధారణ వ్యక్తీకరణల కోసం "శోధన ఇంజిన్". శోధనను నిర్వహించడానికి, మేము దానికి రెండు అంశాలను ఇవ్వాలి: నమూనా మరియు ప్రారంభ సూచిక. Matcherఒక వస్తువును సృష్టించడానికి , Patternతరగతి క్రింది పద్ధతిని అందిస్తుంది: рublic Matcher matcher(CharSequence input) పద్ధతి ఒక అక్షర క్రమాన్ని తీసుకుంటుంది, అది శోధించబడుతుంది. ఇది ఇంటర్ఫేస్ను అమలు చేసే తరగతికి ఉదాహరణ CharSequence. మీరు a మాత్రమే కాకుండా Stringa StringBuffer, StringBuilder, Segment, లేదా CharBuffer. నమూనా అనేది పద్ధతి అని పిలువబడే ఒక Patternవస్తువు matcher. సరిపోలికను సృష్టించడానికి ఉదాహరణ:
Pattern p = Pattern.compile("a*b"); // Create a compiled representation of the regular expression
Matcher m = p.matcher("aaaaab"); // Create a "search engine" to search the text "aaaaab" for the pattern "a*b"

boolean find()వచనంలో తదుపరి సరిపోలిక కోసం చూస్తుంది. ఈవెంట్ మోడల్లో భాగంగా మొత్తం వచనాన్ని విశ్లేషించడానికి మేము ఈ పద్ధతిని మరియు లూప్ స్టేట్మెంట్ను ఉపయోగించవచ్చు. మరో మాటలో చెప్పాలంటే, ఒక ఈవెంట్ సంభవించినప్పుడు, అంటే మనం టెక్స్ట్లో సరిపోలికను కనుగొన్నప్పుడు అవసరమైన ఆపరేషన్లను చేయవచ్చు. ఉదాహరణకు, టెక్స్ట్లో మ్యాచ్ స్థానాన్ని నిర్ణయించడానికి మేము ఈ తరగతి int start()మరియు పద్ధతులను ఉపయోగించవచ్చు. మరియు మేము రీప్లేస్మెంట్ పరామితి యొక్క విలువతో మ్యాచ్లను భర్తీ చేయడానికి మరియు పద్ధతులను int end()ఉపయోగించవచ్చు . ఉదాహరణకి: String replaceFirst(String replacement)String replaceAll(String replacement)
public static void main(String[] args) {
String text = "Fred Anna Alexa";
Pattern pattern = Pattern.compile("A.+?a");
Matcher matcher = pattern.matcher(text);
while (matcher.find()) {
int start=matcher.start();
int end=matcher.end();
System.out.println("Match found: " + text.substring(start, end) + " from index "+ start + " through " + (end-1));
}
System.out.println(matcher.replaceFirst("Ira"));
System.out.println(matcher.replaceAll("Mary"));
System.out.println(text);
}
Match found: Anna from index 5 through 8
Match found: Alexa from index 10 through 14
Fred Ira Alexa
Fred Mary Mary
Fred Anna Alexa
replaceFirstమరియు replaceAllపద్ధతులు కొత్త వస్తువును సృష్టిస్తాయని ఉదాహరణ స్పష్టం చేస్తుంది String- అసలు టెక్స్ట్లోని నమూనా సరిపోలికలను ఆర్గ్యుమెంట్గా పద్ధతికి పంపిన టెక్స్ట్ ద్వారా భర్తీ చేయబడిన స్ట్రింగ్. అదనంగా, replaceFirstపద్ధతి మొదటి మ్యాచ్ని మాత్రమే భర్తీ చేస్తుంది, కానీ replaceAllపద్ధతి టెక్స్ట్లోని అన్ని మ్యాచ్లను భర్తీ చేస్తుంది. అసలు వచనం మారదు. మరియు తరగతుల యొక్క అత్యంత తరచుగా Patternజరిగే Matcherరీజెక్స్ కార్యకలాపాలు తరగతిలోనే నిర్మించబడ్డాయి String. splitఇవి , matches, replaceFirstమరియు వంటి పద్ధతులు replaceAll. కానీ హుడ్ కింద, ఈ పద్ధతులు Patternమరియు Matcherతరగతులను ఉపయోగిస్తాయి. కాబట్టి మీరు ఏదైనా అదనపు కోడ్ను వ్రాయకుండా ప్రోగ్రామ్లో టెక్స్ట్ను భర్తీ చేయాలనుకుంటే లేదా స్ట్రింగ్లను సరిపోల్చాలనుకుంటే, పద్ధతులను ఉపయోగించండిStringతరగతి. మీకు మరింత అధునాతన ఫీచర్లు కావాలంటే, Patternమరియు Matcherతరగతులను గుర్తుంచుకోండి.
ముగింపు
జావా ప్రోగ్రామ్లో, నిర్దిష్ట నమూనా-సరిపోలిక నియమాలను పాటించే స్ట్రింగ్ ద్వారా సాధారణ వ్యక్తీకరణ నిర్వచించబడుతుంది. కోడ్ని అమలు చేస్తున్నప్పుడు, జావా మెషీన్ ఈ స్ట్రింగ్ను ఒకPatternఆబ్జెక్ట్గా కంపైల్ చేస్తుంది మరియు Matcherటెక్స్ట్లో సరిపోలికలను కనుగొనడానికి ఒక వస్తువును ఉపయోగిస్తుంది. నేను మొదట్లో చెప్పినట్లుగా, ప్రజలు తరచుగా సాధారణ వ్యక్తీకరణలను తర్వాత కోసం నిలిపివేస్తారు, వాటిని కష్టమైన అంశంగా భావిస్తారు. కానీ మీరు ప్రాథమిక వాక్యనిర్మాణం, మెటాక్యారెక్టర్లు మరియు అక్షరాలు తప్పించుకోవడం మరియు సాధారణ వ్యక్తీకరణల ఉదాహరణలను అధ్యయనం చేస్తే, అవి మొదటి చూపులో కనిపించే దానికంటే చాలా సరళంగా ఉన్నాయని మీరు కనుగొంటారు.
|
మరింత పఠనం: |
|---|
GO TO FULL VERSION