
Co to jest wyrażenie regularne (regex)?
W rzeczywistości wyrażenie regularne jest wzorcem wyszukiwania ciągu znaków w tekście. W Javie oryginalną reprezentacją tego wzorca jest zawsze string, czyli obiekt klasyString. Jednak nie jest to dowolny ciąg, który można skompilować w wyrażenie regularne — tylko ciągi, które są zgodne z regułami tworzenia wyrażeń regularnych. Składnia jest zdefiniowana w specyfikacji języka. Wyrażenia regularne są zapisywane przy użyciu liter i cyfr, a także metaznaków, które są znakami o specjalnym znaczeniu w składni wyrażeń regularnych. Na przykład:
String regex = "java"; // The pattern is "java";
String regex = "\\d{3}"; // The pattern is three digits;
Tworzenie wyrażeń regularnych w Javie
Tworzenie wyrażenia regularnego w Javie obejmuje dwa proste kroki:- zapisz to jako ciąg zgodny ze składnią wyrażeń regularnych;
- skompiluj ciąg znaków w wyrażenie regularne;
Pattern. Aby to zrobić, musimy wywołać jedną z dwóch statycznych metod klasy: compile. Pierwsza metoda przyjmuje jeden argument — literał łańcuchowy zawierający wyrażenie regularne, natomiast druga przyjmuje dodatkowy argument określający ustawienia dopasowywania wzorców:
public static Pattern compile (String literal)
public static Pattern compile (String literal, int flags)
flagsjest zdefiniowana w Patternklasie i jest dla nas dostępna jako statyczne zmienne klasowe. Na przykład:
Pattern pattern = Pattern.compile("java", Pattern.CASE_INSENSITIVE); // Pattern-matching will be case insensitive.
Patternklasa jest konstruktorem wyrażeń regularnych. Pod maską compilemetoda wywołuje Patternprywatnego konstruktora klasy, aby utworzyć skompilowaną reprezentację. Ten mechanizm tworzenia obiektów jest realizowany w ten sposób w celu tworzenia niezmiennych obiektów. Podczas tworzenia wyrażenia regularnego sprawdzana jest jego składnia. Jeśli łańcuch zawiera błędy, PatternSyntaxExceptiongenerowany jest a.
Składnia wyrażeń regularnych
Składnia wyrażeń regularnych opiera się na<([{\^-=$!|]})?*+.>znakach, które można łączyć z literami. W zależności od pełnionej roli można je podzielić na kilka grup:
| Metaznak | Opis |
|---|---|
| ^ | początek linii |
| $ | koniec linii |
| \B | granica słowa |
| \B | granica niebędąca słowem |
| \A | początek wejścia |
| \G | Koniec poprzedniego meczu |
| \Z | koniec wpisu |
| \z | koniec wpisu |
| Metaznak | Opis |
|---|---|
| \D | cyfra |
| \D | niecyfrowy |
| \S | biały znak |
| \S | znak inny niż spacja |
| \w | znak alfanumeryczny lub podkreślenie |
| \W | dowolny znak z wyjątkiem liter, cyfr i podkreślenia |
| . | dowolny znak |

| Metaznak | Opis |
|---|---|
| \T | znak tabulacji |
| \N | znak nowej linii |
| \R | powrót karetki |
| \F | znak wysuwu wiersza |
| \u0085 | znak następnego wiersza |
| \u2028 | separator linii |
| \u2029 | separator akapitów |
| Metaznak | Opis |
|---|---|
| [ABC] | dowolny z wymienionych znaków (a, b lub c) |
| [^abc] | dowolny znak inny niż wymienione (nie a, b lub c) |
| [a-zA-Z] | zakresy scalone (znaki łacińskie od a do z, wielkość liter nie ma znaczenia) |
| [ad[mp]] | połączenie znaków (od a do d i od m do p) |
| [az&&[def]] | przecięcie znaków (d, e, f) |
| [az&&[^bc]] | odejmowanie znaków (a, dz) |
| Metaznak | Opis |
|---|---|
| ? | jeden lub żaden |
| * | zero lub więcej razy |
| + | jeden lub więcej razy |
| {N} | n razy |
| {N,} | n lub więcej razy |
| {n, m} | co najmniej n razy i nie więcej niż m razy |
Chciwe kwantyfikatory
Jedną rzeczą, którą powinieneś wiedzieć o kwantyfikatorach, jest to, że występują one w trzech różnych odmianach: chciwej, zaborczej i niechętnej. Kwantyfikator staje się zaborczy, dodając+znak „ ” po kwantyfikatorze. Sprawiasz, że jest niechętny, dodając „ ?”. Na przykład:
"A.+a" // greedy
"A.++a" // possessive
"A.+?a" // reluctant
public static void main(String[] args) {
String text = "Fred Anna Alexander";
Pattern pattern = Pattern.compile("A.+a");
Matcher matcher = pattern.matcher(text);
while (matcher.find()) {
System.out.println(text.substring(matcher.start(), matcher.end()));
}
}
Anna Alexa
A.+a” dopasowywanie wzorców odbywa się w następujący sposób:
-
Pierwszym znakiem w podanym wzorze jest litera łacińska
A.Matcherporównuje go z każdym znakiem tekstu, zaczynając od indeksu zero. ZnakFznajduje się w indeksie zero w naszym tekście, więcMatcheriteruje po znakach, aż dopasuje się do wzorca. W naszym przykładzie ten znak znajduje się pod indeksem 5.![Wyrażenia regularne w Javie - 2]()
-
Po znalezieniu dopasowania do pierwszego znaku
Matcherwzorca szuka dopasowania do drugiego znaku. W naszym przypadku jest to.znak „ ”, który oznacza dowolny znak.![Wyrażenia regularne w Javie - 3]()
Postać
njest na szóstej pozycji. Z pewnością kwalifikuje się jako dopasowanie do „dowolnej postaci”. -
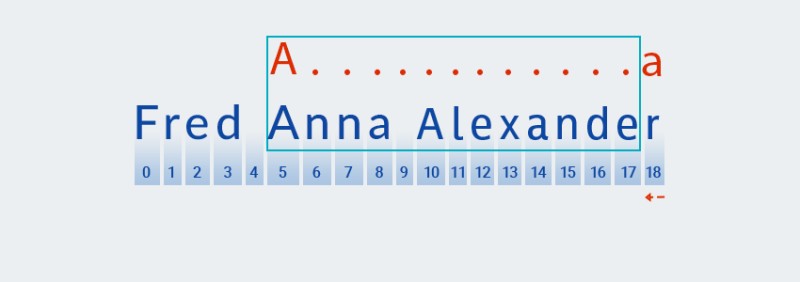
Matcherprzechodzi do sprawdzania następnego znaku wzorca. W naszym wzorcu jest zawarty w kwantyfikatorze odnoszącym się do poprzedzającego znaku: „.+”. Ponieważ liczba powtórzeń „dowolnego znaku” w naszym wzorcu wynosi jeden lub więcej razy,Matcherwielokrotnie bierze następny znak z łańcucha i sprawdza go pod kątem wzorca, o ile pasuje do „dowolnego znaku”. W naszym przykładzie — do końca napisu (od indeksu 7 do indeksu 18).![Wyrażenia regularne w Javie - 4]()
Zasadniczo
Matcherpożera strunę do końca — dokładnie to oznacza „chciwy”. -
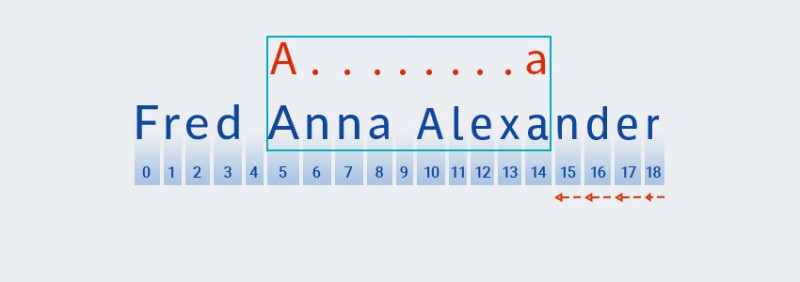
Gdy Matcher dotrze do końca tekstu i zakończy sprawdzanie "
A.+" części wzorca, zaczyna sprawdzać resztę wzorca:a. Nie ma więcej tekstu do przodu, więc sprawdzanie przebiega przez „wycofanie się”, zaczynając od ostatniego znaku:![Wyrażenia regularne w Javie - 5]()
-
Matcher„zapamiętuje” liczbę powtórzeń w „.+” części wzoru. W tym momencie zmniejsza liczbę powtórzeń o jeden i sprawdza większy wzorzec z tekstem, aż do znalezienia dopasowania:![Wyrażenia regularne w Javie - 6]()



Kwantyfikatory dzierżawcze
Kwantyfikatory dzierżawcze są bardzo podobne do chciwych. Różnica polega na tym, że gdy tekst został przechwycony do końca łańcucha, nie ma dopasowywania wzorców podczas „cofania się”. Innymi słowy, pierwsze trzy etapy są takie same jak w przypadku zachłannych kwantyfikatorów. Po przechwyceniu całego ciągu, dopasowujący dodaje resztę wzorca do tego, co bierze pod uwagę i porównuje go z przechwyconym ciągiem. W naszym przykładzie przy użyciu wyrażenia regularnego „A.++a” główna metoda nie znajduje dopasowania. 
Kwantyfikatory niechętne
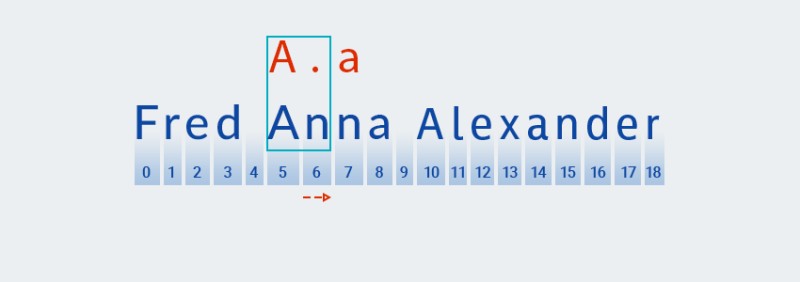
-
W przypadku tych kwantyfikatorów, podobnie jak w przypadku zachłannej odmiany, kod szuka dopasowania na podstawie pierwszego znaku wzorca:
![Wyrażenia regularne w Javie - 8]()
-
Następnie szuka dopasowania do następnego znaku wzorca (dowolnego znaku):
![Wyrażenia regularne w Javie - 9]()
-
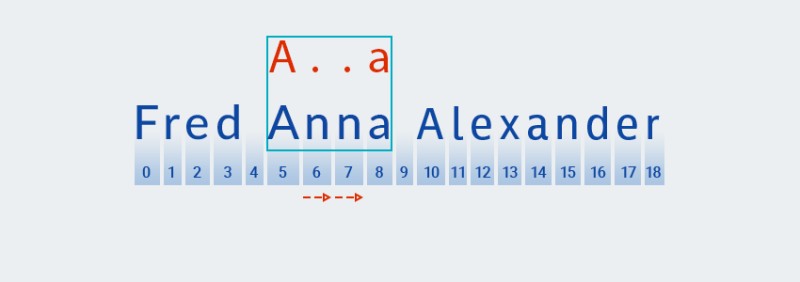
W przeciwieństwie do zachłannego dopasowywania wzorców, najkrótsze dopasowanie jest wyszukiwane w niechętnym dopasowywaniu wzorców. Oznacza to, że po znalezieniu dopasowania do drugiego znaku wzorca (kropka, która odpowiada znakowi na pozycji 6 w tekście,
Matchersprawdza, czy tekst pasuje do reszty wzorca — znaku „a”![Wyrażenia regularne w Javie - 10]()
-
Tekst nie pasuje do wzorca (tzn. zawiera znak „
n” na indeksie 7), więcMatcherdodaje jeszcze jeden „dowolny znak”, ponieważ kwantyfikator wskazuje jeden lub więcej. Następnie ponownie porównuje wzór z tekstem na pozycjach od 5 do 8:![Wyrażenia regularne w Javie - 11]()


W naszym przypadku dopasowanie zostało znalezione, ale nie dotarliśmy jeszcze do końca tekstu. W związku z tym dopasowywanie wzorca zaczyna się od pozycji 9, tj. przy użyciu podobnego algorytmu szukany jest pierwszy znak wzorca i powtarza się to do końca tekstu.

mainmetoda uzyskuje następujący wynik przy użyciu wzorca „ A.+?a”: Anna Alexa Jak widać z naszego przykładu, różne typy kwantyfikatorów dają różne wyniki dla tego samego wzorca. Miej to na uwadze i wybierz odpowiednią odmianę w oparciu o to, czego szukasz.
Znaki specjalne w wyrażeniach regularnych
Ponieważ wyrażenie regularne w Javie, a raczej jego oryginalna reprezentacja, jest literałem łańcuchowym, musimy uwzględnić reguły Java dotyczące literałów łańcuchowych. W szczególności znak odwrotnego ukośnika „\” w literałach łańcuchowych w kodzie źródłowym Javy jest interpretowany jako znak kontrolny, który informuje kompilator, że następny znak jest specjalny i musi być interpretowany w specjalny sposób. Na przykład:
String s = "The root directory is \nWindows"; // Move "Windows" to a new line
String s = "The root directory is \u00A7Windows"; // Insert a paragraph symbol before "Windows"
\znaków „ ” (tj. wskazujących metaznaki) muszą powtarzać ukośniki odwrotne, aby zapewnić, że kompilator kodu bajtowego Javy nie zinterpretuje błędnie ciągu znaków. Na przykład:
String regex = "\\s"; // Pattern for matching a whitespace character
String regex = "\"Windows\""; // Pattern for matching "Windows"
String regex = "How\\?"; // Pattern for matching "How?"
Metody klasy Pattern
KlasaPatternposiada inne metody pracy z wyrażeniami regularnymi:
-
String pattern()‒ zwraca oryginalną reprezentację ciągu wyrażeń regularnych użytą do utworzeniaPatternobiektu:Pattern pattern = Pattern.compile("abc"); System.out.println(pattern.pattern()); // "abc" -
static boolean matches(String regex, CharSequence input)– pozwala sprawdzić wyrażenie regularne przekazane jako regex z tekstem przekazanym jakoinput. Zwroty:true – jeśli tekst pasuje do wzorca;
fałsz – jeśli nie;Na przykład:
System.out.println(Pattern.matches("A.+a","Anna")); // true System.out.println(Pattern.matches("A.+a","Fred Anna Alexander")); // false -
int flags()‒ zwraca wartość parametru wzorcaflagsustawionego podczas tworzenia wzorca lub 0, jeśli parametr nie był ustawiony. Na przykład:Pattern pattern = Pattern.compile("abc"); System.out.println(pattern.flags()); // 0 Pattern pattern = Pattern.compile("abc",Pattern.CASE_INSENSITIVE); System.out.println(pattern.flags()); // 2 -
String[] split(CharSequence text, int limit)– dzieli przekazany tekst naStringtablicę. Parametrlimitwskazuje maksymalną liczbę dopasowań wyszukanych w tekście:- jeśli
limit > 0‒limit-1pasuje; - if
limit < 0‒ wszystkie dopasowania w tekście - if
limit = 0‒ wszystkie dopasowania w tekście, odrzucane są puste napisy na końcu tablicy;
Na przykład:
public static void main(String[] args) { String text = "Fred Anna Alexa"; Pattern pattern = Pattern.compile("\\s"); String[] strings = pattern.split(text,2); for (String s : strings) { System.out.println(s); } System.out.println("---------"); String[] strings1 = pattern.split(text); for (String s : strings1) { System.out.println(s); } }Wyjście konsoli:
Fred Anna Alexa --------- Fred Anna AlexaPoniżej rozważymy inną metodę klasy używaną do tworzenia
Matcherobiektu. - jeśli
Metody klasy Matcher
Instancje klasyMatchersą tworzone w celu przeprowadzania dopasowywania wzorców. Matcherjest "wyszukiwarką" wyrażeń regularnych. Aby przeprowadzić wyszukiwanie, musimy podać mu dwie rzeczy: wzorzec i indeks początkowy. Aby utworzyć Matcherobiekt, Patternklasa zapewnia następującą metodę: рublic Matcher matcher(CharSequence input) Metoda przyjmuje ciąg znaków, który zostanie przeszukany. Jest to instancja klasy, która implementuje CharSequenceinterfejs. Możesz przekazać nie tylko a String, ale także a StringBuffer, StringBuilder, Segmentlub CharBuffer. Wzorzec jest Patternobiektem, na którym matcherwywoływana jest metoda. Przykład tworzenia dopasowania:
Pattern p = Pattern.compile("a*b"); // Create a compiled representation of the regular expression
Matcher m = p.matcher("aaaaab"); // Create a "search engine" to search the text "aaaaab" for the pattern "a*b"

boolean find()szuka następnego dopasowania w tekście. Możemy użyć tej metody i instrukcji pętli do analizy całego tekstu jako części modelu zdarzeń. Innymi słowy, możemy wykonać niezbędne operacje, gdy wystąpi zdarzenie, czyli gdy znajdziemy dopasowanie w tekście. Na przykład możemy użyć tej klasy int start()i int end()metod do określenia pozycji dopasowania w tekście. I możemy użyć metod String replaceFirst(String replacement)i String replaceAll(String replacement)do zastąpienia dopasowań wartością parametru zamiany. Na przykład:
public static void main(String[] args) {
String text = "Fred Anna Alexa";
Pattern pattern = Pattern.compile("A.+?a");
Matcher matcher = pattern.matcher(text);
while (matcher.find()) {
int start=matcher.start();
int end=matcher.end();
System.out.println("Match found: " + text.substring(start, end) + " from index "+ start + " through " + (end-1));
}
System.out.println(matcher.replaceFirst("Ira"));
System.out.println(matcher.replaceAll("Mary"));
System.out.println(text);
}
Match found: Anna from index 5 through 8
Match found: Alexa from index 10 through 14
Fred Ira Alexa
Fred Mary Mary
Fred Anna Alexa
replaceFirsti replaceAlltworzą nowy Stringobiekt — ciąg znaków, w którym wzorce pasujące do oryginalnego tekstu są zastępowane tekstem przekazanym metodzie jako argument. Ponadto replaceFirstmetoda zastępuje tylko pierwsze dopasowanie, ale replaceAllmetoda zastępuje wszystkie dopasowania w tekście. Oryginalny tekst pozostaje niezmieniony. Najczęstsze operacje wyrażeń regularnych klas i są wbudowane bezpośrednio w Patternklasę . Są to metody takie jak , , , i . Ale pod maską te metody wykorzystują klasy i . Jeśli więc chcesz zastąpić tekst lub porównać ciągi w programie bez pisania dodatkowego kodu, użyj metodMatcherStringsplitmatchesreplaceFirstreplaceAllPatternMatcherStringklasa. Jeśli potrzebujesz bardziej zaawansowanych funkcji, pamiętaj o klasach Patterni Matcher.
Wniosek
W programie Java wyrażenie regularne jest definiowane przez ciąg, który spełnia określone reguły dopasowywania wzorców. Podczas wykonywania kodu maszyna Java kompiluje ten ciąg znaków wPatternobiekt i używa Matcherobiektu do znajdowania dopasowań w tekście. Jak powiedziałem na początku, ludzie często odkładają wyrażenia regularne na później, uważając je za trudny temat. Ale jeśli rozumiesz podstawową składnię, metaznaki i znaki specjalne, a także przestudiujesz przykłady wyrażeń regularnych, przekonasz się, że są one znacznie prostsze, niż się wydaje na pierwszy rzut oka.
|
Więcej czytania: |
|---|
GO TO FULL VERSION