
Mi az a reguláris kifejezés (regex)?
Valójában a reguláris kifejezés egy karakterlánc keresési minta a szövegben. Java-ban ennek a mintának az eredeti reprezentációja mindig egy karakterlánc, azaz az osztály objektumaString. Azonban nem bármilyen karakterlánc fordítható reguláris kifejezéssé – csak olyan karakterlánc, amely megfelel a reguláris kifejezések létrehozására vonatkozó szabályoknak. A szintaxist a nyelvi specifikáció határozza meg. A reguláris kifejezések írása betűk és számok, valamint metakarakterek használatával történik, amelyek olyan karakterek, amelyeknek különleges jelentése van a reguláris kifejezés szintaxisában. Például:
String regex = "java"; // The pattern is "java";
String regex = "\\d{3}"; // The pattern is three digits;
Szabályos kifejezések létrehozása Java nyelven
A reguláris kifejezés létrehozása Java nyelven két egyszerű lépésből áll:- írja be olyan karakterláncként, amely megfelel a reguláris kifejezés szintaxisának;
- fordítsa le a karakterláncot reguláris kifejezéssé;
Patternobjektum létrehozásával kezdünk el dolgozni a reguláris kifejezésekkel. Ehhez meg kell hívnunk az osztály két statikus metódusa közül az egyiket: compile. Az első módszer egy argumentumot vesz fel – a reguláris kifejezést tartalmazó string literált, míg a második egy további argumentumot, amely meghatározza a mintaillesztési beállításokat:
public static Pattern compile (String literal)
public static Pattern compile (String literal, int flags)
flags osztályban van definiálva Pattern, és statikus osztályváltozóként áll rendelkezésünkre. Például:
Pattern pattern = Pattern.compile("java", Pattern.CASE_INSENSITIVE); // Pattern-matching will be case insensitive.
Patternosztály a reguláris kifejezések konstruktora. A burkolat alatt a compilemetódus meghívja az Patternosztály privát konstruktorát, hogy létrehozzon egy lefordított reprezentációt. Ezt az objektum-létrehozási mechanizmust így valósítják meg annak érdekében, hogy megváltoztathatatlan objektumokat hozzanak létre. A reguláris kifejezés létrehozásakor a szintaxis ellenőrzésre kerül. Ha a karakterlánc hibákat tartalmaz, akkor a PatternSyntaxExceptiongenerálódik.
Reguláris kifejezés szintaxisa
A reguláris kifejezés szintaxisa a karaktereken alapul<([{\^-=$!|]})?*+.>, amelyek kombinálhatók betűkkel. Szerepüktől függően több csoportra oszthatók:
| Metakarakter | Leírás |
|---|---|
| ^ | egy sor eleje |
| $ | egy sor vége |
| \b | szóhatár |
| \B | nem szóhatár |
| \A | a bemenet eleje |
| \G | az előző meccs vége |
| \Z | a bemenet vége |
| \z | a bemenet vége |
| Metakarakter | Leírás |
|---|---|
| \d | számjegy |
| \D | nem számjegyű |
| \s | szóköz karakter |
| \S | nem szóköz karakter |
| \w | alfanumerikus karakter vagy aláhúzás |
| \W | bármilyen karakter, kivéve a betűket, számokat és aláhúzást |
| . | bármilyen karakter |

| Metakarakter | Leírás |
|---|---|
| \t | tabulátor karakter |
| \n | újsor karakter |
| \r | kocsi vissza |
| \f | soremelés karakter |
| \u0085 | következő sor karakter |
| \u2028 | sorelválasztó |
| \u2029 | bekezdéselválasztó |
| Metakarakter | Leírás |
|---|---|
| [ABC] | a felsorolt karakterek bármelyike (a, b vagy c) |
| [^abc] | a felsoroltakon kívül bármilyen karakter (nem a, b vagy c) |
| [a-zA-Z] | egyesített tartományok (latin karakterek a-tól z-ig, nem különbözik a kis- és nagybetűktől) |
| [ad[mp]] | karakterek egyesítése (a-tól d-ig és m-től p-ig) |
| [az&&[def]] | karakterek metszéspontja (d, e, f) |
| [az&&[^bc]] | karakterek kivonása (a, dz) |
| Metakarakter | Leírás |
|---|---|
| ? | egyet vagy egyet sem |
| * | nulla vagy több alkalommal |
| + | egy vagy több alkalommal |
| {n} | n-szer |
| {n,} | n vagy több alkalommal |
| {n, m} | legalább n-szer és legfeljebb m-szer |
Mohó kvantorok
Egy dolog, amit a kvantorokról tudnia kell, az az, hogy három különböző változatban kaphatók: mohó, birtokló és vonakodó. A kvantort birtokossá teheti, ha+a kvantor után egy " " karaktert ad hozzá. A " " hozzáadásával vonakodóvá teszi ?. Például:
"A.+a" // greedy
"A.++a" // possessive
"A.+?a" // reluctant
public static void main(String[] args) {
String text = "Fred Anna Alexander";
Pattern pattern = Pattern.compile("A.+a");
Matcher matcher = pattern.matcher(text);
while (matcher.find()) {
System.out.println(text.substring(matcher.start(), matcher.end()));
}
}
Anna Alexa
A.+aa mintaillesztés a következőképpen történik:
-
A megadott minta első karaktere a latin betű
A.Matcherösszehasonlítja a szöveg minden karakterével, a nulla indextől kezdve. A karakterFa szövegünkben a nulla indexen található, tehát addigMatcheriterál a karakterek között, amíg meg nem felel a mintának. Példánkban ez a karakter az 5-ös indexen található.![Reguláris kifejezések Java nyelven - 2]()
-
Ha talált egyezést a minta első karakterével,
Matcherkeressen egyezést a második karakterével. Esetünkben ez a "." karakter, amely bármely karaktert jelöl.![Reguláris kifejezések Java nyelven - 3]()
A karakter
na hatodik helyen áll. Minden bizonnyal "bármilyen karakter" megfelelőnek minősül. -
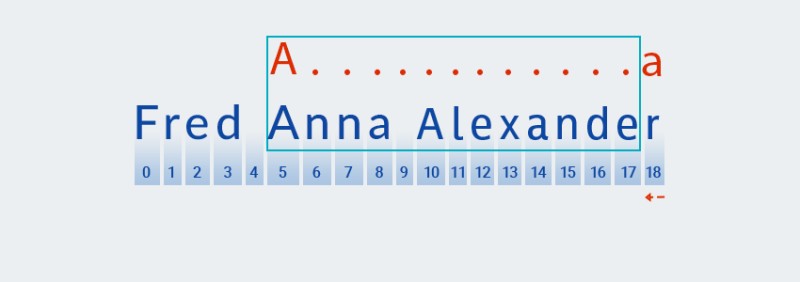
Matcherfolytatja a minta következő karakterének ellenőrzését. A mi mintánkban szerepel a kvantorban, amely az előző karakterre vonatkozik: ".+". Mivel a mintánkban szereplő "bármely karakter" ismétlődéseinek száma egy vagy több,Matcherismételten kiveszi a következő karaktert a karakterláncból, és ellenőrzi a mintával, amíg az megegyezik a "bármely karakterrel". Példánkban - a karakterlánc végéig (7-es indextől 18-ig).![Reguláris kifejezések Java nyelven - 4]()
Alapvetően
Matcherfelzabálja a húrt a végéig – pontosan ezt jelenti a „kapzsi”. -
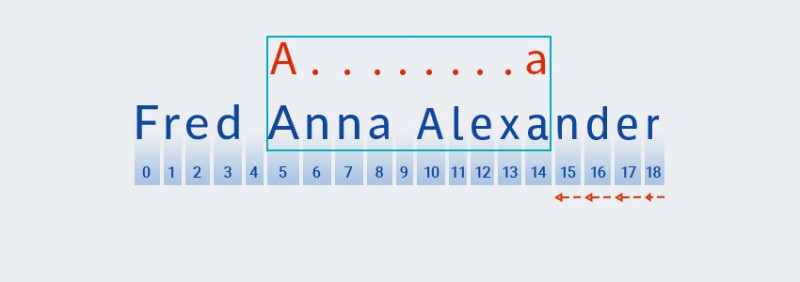
A.+Miután a Matcher eléri a szöveg végét, és befejezi a minta " " részének ellenőrzését , elkezdi ellenőrizni a minta többi részét:a. Nincs több szöveg, így az ellenőrzés az utolsó karaktertől kezdődően „hátrálással” folytatódik:![Reguláris kifejezések Java nyelven - 5]()
-
Matcher"emlékezik" az ismétlések számára a.+minta " " részében. Ezen a ponton eggyel csökkenti az ismétlések számát, és a nagyobb mintát a szöveghez hasonlítja, amíg egyezést nem talál:![Reguláris kifejezések Java nyelven - 6]()



Birtokos kvantorok
A birtokos kvantorok sokban hasonlítanak a mohókra. A különbség az, hogy amikor a szöveget a karakterlánc végéig rögzítik, a "hátrálás" során nincs mintaillesztés. Más szóval, az első három szakasz ugyanaz, mint a mohó kvantorok esetében. A teljes karakterlánc rögzítése után az illesztő hozzáadja a minta többi részét ahhoz, amit figyelembe vesz, és összehasonlítja a rögzített karakterlánccal. Példánkban a "A.++a" reguláris kifejezés használatával a fő metódus nem talál egyezést. 
Vonakodó kvantorok
-
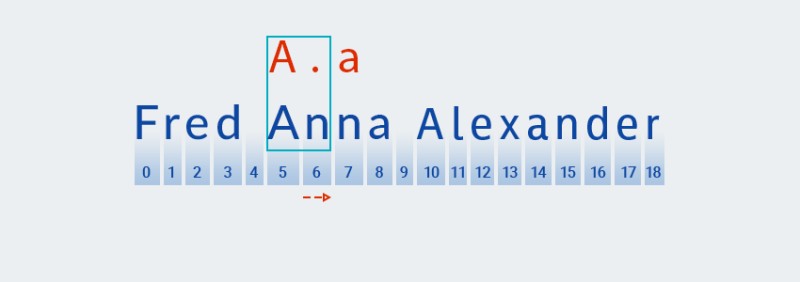
Ezeknél a kvantoroknál, akárcsak a mohó változatnál, a kód a minta első karaktere alapján keres egyezést:
![Reguláris kifejezések Java nyelven - 8]()
-
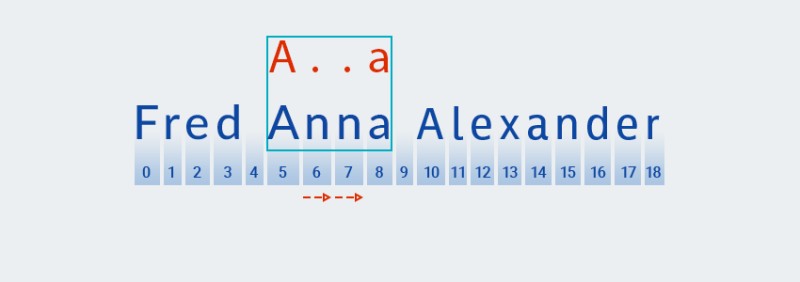
Ezután egyezést keres a minta következő karakterével (bármely karakterrel):
![Reguláris kifejezések Java nyelven - 9]()
-
Ellentétben a mohó mintaillesztéssel, a legrövidebb egyezést kell keresni a kelletlen mintaillesztésnél. Ez azt jelenti, hogy miután talált egyezést a minta második karakterével (egy pont, amely a szöveg 6. pozíciójában lévő karakternek felel meg,
Matcherellenőrzi, hogy a szöveg egyezik-e a minta többi részével - a " "akarakterrel![Reguláris kifejezések Java nyelven - 10]()
-
A szöveg nem egyezik a mintával (azaz tartalmazza a " " karaktert a
n7-es indexnél), ezértMatcherad hozzá még egy "bármelyik karaktert", mivel a kvantor egy vagy több karaktert jelez. Ezután ismét összehasonlítja a mintát az 5–8. pozícióban lévő szöveggel:![Reguláris kifejezések Java nyelven - 11]()


Esetünkben egyezés található, de még nem értünk a szöveg végére. Ezért a mintaillesztés a 9-es pozícióból indul újra, azaz a minta első karakterét hasonló algoritmussal keresik, és ez ismétlődik a szöveg végéig.

mainmódszer a következő eredményt kapja a " " minta használatakor A.+?a: Anna Alexa Amint a példánkból látható, a különböző típusú kvantorok ugyanarra a mintára eltérő eredményeket adnak. Ezért tartsa ezt szem előtt, és válassza ki a megfelelő fajtát az alapján, amit keres.
Menekülő karakterek reguláris kifejezésekben
Mivel a Java-ban egy reguláris kifejezés, pontosabban annak eredeti ábrázolása karakterlánc-literál, figyelembe kell vennünk a Java-szabályokat a karakterlánc-literálokra vonatkozóan. A Java forráskódban található karakterlánc-\literálokban található " " fordított perjel vezérlőkarakterként értelmeződik, amely közli a fordítóval, hogy a következő karakter különleges, és különleges módon kell értelmezni. Például:
String s = "The root directory is \nWindows"; // Move "Windows" to a new line
String s = "The root directory is \u00A7Windows"; // Insert a paragraph symbol before "Windows"
\" karaktereket használó karakterláncoknak (vagyis a metakarakterek jelzésére) meg kell ismételni a fordított perjeleket, hogy a Java bájtkód-fordító ne értelmezze félre a karakterláncot. Például:
String regex = "\\s"; // Pattern for matching a whitespace character
String regex = "\"Windows\""; // Pattern for matching "Windows"
String regex = "How\\?"; // Pattern for matching "How?"
A Pattern osztály módszerei
AzPatternosztálynak más módszerei is vannak a reguláris kifejezésekkel való munkavégzéshez:
-
String pattern()‒ az objektum létrehozásához használt reguláris kifejezés eredeti karakterlánc-reprezentációját adja visszaPattern:Pattern pattern = Pattern.compile("abc"); System.out.println(pattern.pattern()); // "abc" -
static boolean matches(String regex, CharSequence input)– lehetővé teszi a reguláris kifejezésként átadott reguláris kifejezés összehasonlítását a ként átadott szöveggelinput. Visszaküldések:igaz – ha a szöveg megegyezik a mintával;
hamis – ha nem;Például:
System.out.println(Pattern.matches("A.+a","Anna")); // true System.out.println(Pattern.matches("A.+a","Fred Anna Alexander")); // false -
int flags()‒ visszaadja a minta paraméterkészletének értékétflagsa minta létrehozásakor, vagy 0-t, ha a paraméter nem volt beállítva. Például:Pattern pattern = Pattern.compile("abc"); System.out.println(pattern.flags()); // 0 Pattern pattern = Pattern.compile("abc",Pattern.CASE_INSENSITIVE); System.out.println(pattern.flags()); // 2 -
String[] split(CharSequence text, int limit)– tömbbe bontja az átadott szövegetString. Alimitparaméter a szövegben keresett egyezések maximális számát jelzi:- ha
limit > 0‒limit-1egyezik; - ha
limit < 0‒ minden egyezés a szövegben - ha
limit = 0‒ minden egyezés a szövegben, a tömb végén lévő üres karakterláncok el lesznek vetve;
Például:
public static void main(String[] args) { String text = "Fred Anna Alexa"; Pattern pattern = Pattern.compile("\\s"); String[] strings = pattern.split(text,2); for (String s : strings) { System.out.println(s); } System.out.println("---------"); String[] strings1 = pattern.split(text); for (String s : strings1) { System.out.println(s); } }Konzol kimenet:
Fred Anna Alexa --------- Fred Anna AlexaAz alábbiakban az osztály egy másik objektum létrehozására használt metódusát tekintjük át
Matcher. - ha
A Matcher osztály módszerei
Az osztály példányaiMatchera mintaillesztés végrehajtására jönnek létre. Matchera reguláris kifejezések "keresője". A keresés végrehajtásához két dolgot kell megadnunk: egy mintát és egy kezdő indexet. MatcherEgy objektum létrehozásához az Patternosztály a következő metódust kínálja: рublic Matcher matcher(CharSequence input) A metódus egy karaktersorozatot vesz fel, amelyben a rendszer megkeresi. Ez egy olyan osztály példánya, amely megvalósítja az CharSequenceinterfészt. StringNem csak a , hanem a StringBuffer, StringBuilder, Segment, vagy -t is átadhatja CharBuffer. A minta egy Patternobjektum, amelyen a matchermetódus meghívásra kerül. Példa egyező létrehozására:
Pattern p = Pattern.compile("a*b"); // Create a compiled representation of the regular expression
Matcher m = p.matcher("aaaaab"); // Create a "search engine" to search the text "aaaaab" for the pattern "a*b"

boolean find()metódus a következő egyezést keresi a szövegben. Ezzel a módszerrel és egy ciklusutasítással elemezhetünk egy teljes szöveget egy eseménymodell részeként. Vagyis akkor tudjuk végrehajtani a szükséges műveleteket, amikor egy esemény bekövetkezik, azaz ha egyezést találunk a szövegben. Például ennek az osztálynak int start()és int end()metódusainak a segítségével meghatározhatjuk az egyezés pozícióját a szövegben. String replaceFirst(String replacement)A és metódusokkal pedig lecserélhetjük String replaceAll(String replacement)az egyezéseket a helyettesítő paraméter értékére. Például:
public static void main(String[] args) {
String text = "Fred Anna Alexa";
Pattern pattern = Pattern.compile("A.+?a");
Matcher matcher = pattern.matcher(text);
while (matcher.find()) {
int start=matcher.start();
int end=matcher.end();
System.out.println("Match found: " + text.substring(start, end) + " from index "+ start + " through " + (end-1));
}
System.out.println(matcher.replaceFirst("Ira"));
System.out.println(matcher.replaceAll("Mary"));
System.out.println(text);
}
Match found: Anna from index 5 through 8
Match found: Alexa from index 10 through 14
Fred Ira Alexa
Fred Mary Mary
Fred Anna Alexa
replaceFirstés replaceAllmetódusok egy új Stringobjektumot hoznak létre – egy karakterláncot, amelyben az eredeti szövegben található mintaegyezéseket a metódusnak argumentumként átadott szöveg helyettesíti. Ezenkívül a replaceFirstmetódus csak az első egyezést cseréli le, de a replaceAllmetódus lecseréli az összes egyezést a szövegben. Az eredeti szöveg változatlan marad. A Patternés Matcherosztályok leggyakoribb regex műveletei közvetlenül az Stringosztályba vannak beépítve. Ezek olyan módszerek, mint a split, matches, replaceFirstés replaceAll. De a motorháztető alatt ezek a módszerek a Patternés Matcherosztályokat használják. Tehát ha szöveget szeretne lecserélni vagy karakterláncokat összehasonlítani egy programban anélkül, hogy külön kódot írna, használja a módszertStringosztály. Ha fejlettebb funkciókra van szüksége, emlékezzen a Patternés Matcherosztályokra.
Következtetés
A Java programokban a reguláris kifejezéseket egy karakterlánc határozza meg, amely bizonyos mintaillesztési szabályoknak engedelmeskedik. A kód végrehajtásakor a Java gép ezt a karakterláncot objektummá fordítjaPattern, és egy Matcherobjektumot használ a szövegben található egyezések megtalálásához. Ahogy az elején mondtam, az emberek gyakran későbbre halasztják a reguláris kifejezéseket, mivel nehéz témának tartják őket. De ha megérti az alapvető szintaxist, a metakaraktereket és a karakteres kihagyást, és tanulmányozza a reguláris kifejezésekre vonatkozó példákat, akkor azt fogja tapasztalni, hogy ezek sokkal egyszerűbbek, mint amilyennek első pillantásra tűnnek.
|
További olvasnivalók: |
|---|
GO TO FULL VERSION