
什麼是正則表達式(regex)?
事實上,正則表達式是一種用於在文本中查找字符串的模式。在Java中,這種模式的原始表示總是一個字符串,即類的一個對象String。然而,並不是任何字符串都可以編譯成正則表達式——只有符合創建正則表達式規則的字符串。語法在語言規範中定義。正則表達式是使用字母和數字以及元字符編寫的,元字符是在正則表達式語法中具有特殊含義的字符。例如:
String regex = "java"; // The pattern is "java";
String regex = "\\d{3}"; // The pattern is three digits;
在 Java 中創建正則表達式
在 Java 中創建正則表達式包括兩個簡單的步驟:- 將其寫成符合正則表達式語法的字符串;
- 將字符串編譯成正則表達式;
Pattern。為此,我們需要調用該類的兩個靜態方法之一:compile。第一個方法接受一個參數——一個包含正則表達式的字符串文字,而第二個方法接受一個額外的參數來確定模式匹配設置:
public static Pattern compile (String literal)
public static Pattern compile (String literal, int flags)
flags中定義Pattern,並作為靜態類變量提供給我們。例如:
Pattern pattern = Pattern.compile("java", Pattern.CASE_INSENSITIVE); // Pattern-matching will be case insensitive.
Pattern是正則表達式的構造函數。在幕後,該compile方法調用Pattern類的私有構造函數來創建編譯表示。這種對象創建機制以這種方式實現,以創建不可變對象。創建正則表達式時,會檢查其語法。如果字符串包含錯誤,則PatternSyntaxException生成 a。
正則表達式語法
正則表達式語法依賴於<([{\^-=$!|]})?*+.>字符,字符可以與字母組合。根據他們的角色,他們可以分為幾組:
| 元字符 | 描述 |
|---|---|
| ^ | 一行的開頭 |
| $ | 行尾 |
| \b | 單詞邊界 |
| \B | 非詞邊界 |
| \A | 輸入的開始 |
| \G | 上一場比賽結束 |
| \Z | 輸入結束 |
| \z | 輸入結束 |
| 元字符 | 描述 |
|---|---|
| \d | 數字 |
| \D | 非數字 |
| \s | 空白字符 |
| \S | 非空白字符 |
| \w | 字母數字字符或下劃線 |
| \W | 除字母、數字和下劃線外的任何字符 |
| . | 任何字符 |
| 元字符 | 描述 |
|---|---|
| \t | 製表符 |
| \n | 換行符 |
| \r | 回車 |
| \F | 換行字符 |
| \u0085 | 下一行字符 |
| \u2028 | 行分隔符 |
| \u2029 | 段落分隔符 |
| 元字符 | 描述 |
|---|---|
| [abc] | 任何列出的字符(a、b 或 c) |
| [^abc] | 所列字符以外的任何字符(不是 a、b 或 c) |
| [a-zA-Z] | 合併範圍(從 a 到 z 的拉丁字符,不區分大小寫) |
| [廣告[mp]] | 字符並集(從 a 到 d 和從 m 到 p) |
| [az&&[def]] | 字符交集 (d, e, f) |
| [az&&[^bc]] | 字符減法 (a, dz) |

| 元字符 | 描述 |
|---|---|
| ? | 一個或一個 |
| * | 零次或多次 |
| + | 一次或多次 |
| {n} | n次 |
| {n,} | n次或更多次 |
| {n,m} | 至少n次且不超過m次 |
貪心量詞
關於量詞你應該知道的一件事是它們有三種不同的類型:貪婪的、佔有欲的和不情願的。+您可以通過在量詞後添加一個“”字符來使量詞具有所有格。你通過添加“”讓它變得不情願?。例如:
"A.+a" // greedy
"A.++a" // possessive
"A.+?a" // reluctant
public static void main(String[] args) {
String text = "Fred Anna Alexander";
Pattern pattern = Pattern.compile("A.+a");
Matcher matcher = pattern.matcher(text);
while (matcher.find()) {
System.out.println(text.substring(matcher.start(), matcher.end()));
}
}
Anna Alexa
A.+a”,模式匹配執行如下:
-
指定模式中的第一個字符是拉丁字母
A。Matcher將它與文本的每個字符進行比較,從索引零開始。該字符F在我們的文本中的索引為零,因此Matcher遍歷字符直到它與模式匹配。在我們的示例中,該字符位於索引 5 處。![Java 中的正則表達式 - 2]()
-
一旦找到與模式的第一個字符的匹配項,
Matcher就查找與其第二個字符的匹配項。在我們的例子中,它是“.”字符,代表任何字符。![Java 中的正則表達式 - 3]()
角色
n在第六個位置。它當然可以匹配“任何字符”。 -
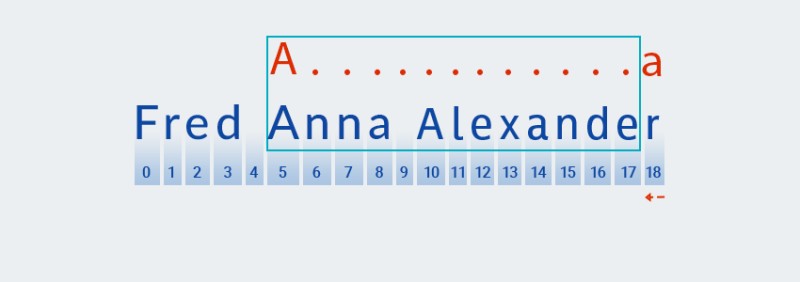
Matcher繼續檢查模式的下一個字符。在我們的模式中,它包含在適用於前面字符的量詞中:".+"。因為我們的模式中“任意字符”的重複次數是一次或多次,所以Matcher重複從字符串中取出下一個字符並與模式進行檢查,只要匹配“任意字符”即可。在我們的例子中——直到字符串的結尾(從索引 7 到索引 18)。![Java 中的正則表達式 - 4]()
基本上,
Matcher吞噬字符串直到最後——這正是“貪婪”的意思。 -
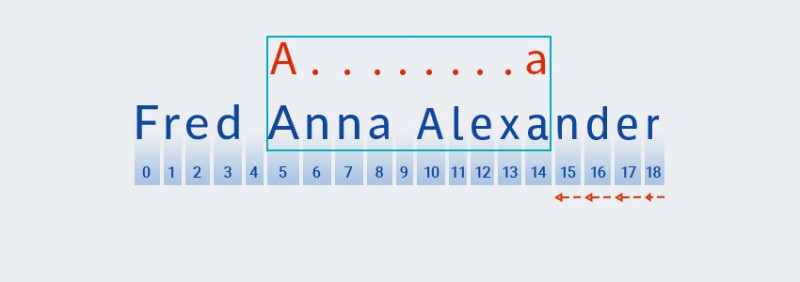
在 Matcher 到達文本末尾並完成模式的 " " 部分的檢查後
A.+,它開始檢查模式的其餘部分:a。後面沒有更多的文本,所以檢查從最後一個字符開始“後退”:![Java 中的正則表達式 - 5]()
-
Matcher.+“記住”模式中“ ”部分的重複次數。此時,它會將重複次數減一,並根據文本檢查較大的模式,直到找到匹配項:![Java 中的正則表達式 - 6]()



所有格量詞
所有格量詞很像貪婪的量詞。不同之處在於,當文本已被捕獲到字符串的末尾時,“後退”時沒有模式匹配。換句話說,前三個階段與貪婪量詞相同。捕獲整個字符串後,匹配器將模式的其餘部分添加到它正在考慮的內容中,並將其與捕獲的字符串進行比較。在我們的示例中,使用正則表達式“A.++a”,main 方法找不到匹配項。 
不情願的量詞
-
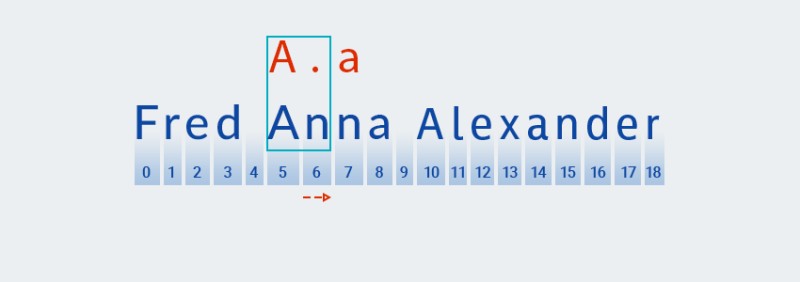
對於這些量詞,與貪婪變種一樣,代碼根據模式的第一個字符查找匹配項:
![Java 中的正則表達式 - 8]()
-
然後它尋找與模式的下一個字符(任何字符)的匹配項:
![Java 中的正則表達式 - 9]()
-
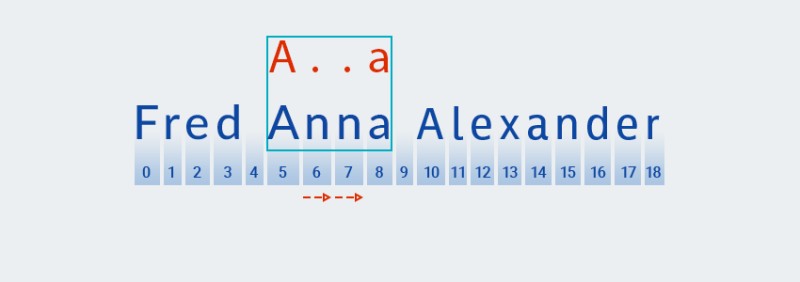
與貪心模式匹配不同,勉強模式匹配搜索最短匹配。這意味著在找到與模式的第二個字符(一個句點,對應於文本中位置 6 處的字符)的匹配項後,
Matcher檢查文本是否與模式的其餘部分匹配——字符“a”![Java 中的正則表達式 - 10]()
-
文本與模式不匹配(即它在索引 7 處包含字符“
n”),因此Matcher添加一個“任何字符”,因為量詞表示一個或多個。然後它再次將模式與位置 5 到 8 中的文本進行比較:![Java 中的正則表達式 - 11]()


在我們的例子中,找到了一個匹配項,但我們還沒有到達文本的末尾。因此,模式匹配從位置 9 重新開始,即使用類似的算法查找模式的第一個字符,並重複此過程直到文本結束。

main方法在使用模式 " " 時獲得以下結果A.+?a: Anna Alexa 從我們的示例中可以看出,不同類型的量詞對同一模式產生不同的結果。所以請記住這一點,並根據您的需求選擇合適的品種。
在正則表達式中轉義字符
因為 Java 中的正則表達式,或者更確切地說,它的原始表示是字符串文字,所以我們需要考慮有關字符串文字的 Java 規則。特別是,\Java 源代碼中字符串文字中的反斜杠字符“”被解釋為一個控製字符,它告訴編譯器下一個字符是特殊的,必須以特殊的方式進行解釋。例如:
String s = "The root directory is \nWindows"; // Move "Windows" to a new line
String s = "The root directory is \u00A7Windows"; // Insert a paragraph symbol before "Windows"
\”字符(即表示元字符)的字符串文字必須重複反斜杠以確保 Java 字節碼編譯器不會誤解字符串。例如:
String regex = "\\s"; // Pattern for matching a whitespace character
String regex = "\"Windows\""; // Pattern for matching "Windows"
String regex = "How\\?"; // Pattern for matching "How?"
模式類的方法
該類Pattern還有其他處理正則表達式的方法:
-
String pattern()‒ 返回用於創建Pattern對象的正則表達式的原始字符串表示形式:Pattern pattern = Pattern.compile("abc"); System.out.println(pattern.pattern()); // "abc" -
static boolean matches(String regex, CharSequence input)– 讓您檢查作為 regex 傳遞的正則表達式與作為input. 退貨:true——如果文本與模式匹配;
false——如果沒有;例如:
System.out.println(Pattern.matches("A.+a","Anna")); // true System.out.println(Pattern.matches("A.+a","Fred Anna Alexander")); // false -
int flags()flags‒ 返回創建模式時模式參數集的值,如果未設置參數,則返回 0。例如:Pattern pattern = Pattern.compile("abc"); System.out.println(pattern.flags()); // 0 Pattern pattern = Pattern.compile("abc",Pattern.CASE_INSENSITIVE); System.out.println(pattern.flags()); // 2 -
String[] split(CharSequence text, int limit)– 將傳遞的文本拆分為一個String數組。該limit參數表示在文本中搜索的最大匹配數:- 如果
limit > 0-limit-1匹配; - if
limit < 0‒ 文本中的所有匹配項 - if
limit = 0‒ 文本中的所有匹配項,數組末尾的空字符串將被丟棄;
例如:
public static void main(String[] args) { String text = "Fred Anna Alexa"; Pattern pattern = Pattern.compile("\\s"); String[] strings = pattern.split(text,2); for (String s : strings) { System.out.println(s); } System.out.println("---------"); String[] strings1 = pattern.split(text); for (String s : strings1) { System.out.println(s); } }控制台輸出:
Fred Anna Alexa --------- Fred Anna Alexa下面我們將考慮用於創建
Matcher對象的類的另一個方法。 - 如果
匹配器類的方法
Matcher創建該類的實例以執行模式匹配。Matcher是正則表達式的“搜索引擎”。要執行搜索,我們需要給它兩個東西:一個模式和一個起始索引。為了創建一個Matcher對象,該類Pattern提供了以下方法: рublic Matcher matcher(CharSequence input) 該方法採用一個字符序列,將對其進行搜索。這是實現接口的類的實例CharSequence。您不僅可以傳遞 a String,還可以傳遞StringBuffer、StringBuilder、Segment或CharBuffer。模式是調用方法Pattern的對象。matcher創建匹配器的示例:
Pattern p = Pattern.compile("a*b"); // Create a compiled representation of the regular expression
Matcher m = p.matcher("aaaaab"); // Create a "search engine" to search the text "aaaaab" for the pattern "a*b"
boolean find()方法在文本中查找下一個匹配項。我們可以使用此方法和循環語句來分析整個文本作為事件模型的一部分。換句話說,我們可以在事件發生時執行必要的操作,即當我們在文本中找到匹配項時。例如,我們可以使用此類的int start()和int end()方法來確定匹配項在文本中的位置。並且我們可以使用String replaceFirst(String replacement)和String replaceAll(String replacement)方法將匹配項替換為替換參數的值。例如:

public static void main(String[] args) {
String text = "Fred Anna Alexa";
Pattern pattern = Pattern.compile("A.+?a");
Matcher matcher = pattern.matcher(text);
while (matcher.find()) {
int start=matcher.start();
int end=matcher.end();
System.out.println("Match found: " + text.substring(start, end) + " from index "+ start + " through " + (end-1));
}
System.out.println(matcher.replaceFirst("Ira"));
System.out.println(matcher.replaceAll("Mary"));
System.out.println(text);
}
Match found: Anna from index 5 through 8
Match found: Alexa from index 10 through 14
Fred Ira Alexa
Fred Mary Mary
Fred Anna Alexa
replaceFirst和replaceAll方法創建了一個新String對象——一個字符串,其中原始文本中的模式匹配被作為參數傳遞給該方法的文本替換。此外,該replaceFirst方法僅替換第一個匹配項,但該replaceAll方法替換文本中的所有匹配項。原文保持不變。和類最頻繁的正Pattern則Matcher表達式操作直接內置到String類中。這些是諸如split、matches、replaceFirst和 之類的方法replaceAll。但在幕後,這些方法使用Pattern和Matcher類。因此,如果您想在程序中替換文本或比較字符串而不編寫任何額外代碼,請使用String班級。如果您需要更高級的功能,請記住Pattern和Matcher類。
結論
在 Java 程序中,正則表達式由遵循特定模式匹配規則的字符串定義。執行代碼時,Java 機器將這個字符串編譯成對象Pattern,並使用Matcher對像在文本中查找匹配項。正如我在開頭所說的,人們經常把正則表達式擱置一旁,認為它們是一個困難的話題。但是如果您了解基本語法、元字符和字符轉義,並研究正則表達式的示例,那麼您會發現它們比乍看起來要簡單得多。
|
更多閱讀: |
|---|
GO TO FULL VERSION