
வழக்கமான வெளிப்பாடு (regex) என்றால் என்ன?
உண்மையில், ஒரு வழக்கமான வெளிப்பாடு என்பது உரையில் ஒரு சரத்தைக் கண்டறிவதற்கான ஒரு வடிவமாகும். ஜாவாவில், இந்த வடிவத்தின் அசல் பிரதிநிதித்துவம் எப்போதும் ஒரு சரம், அதாவது வகுப்பின் பொருள்String. இருப்பினும், இது வழக்கமான வெளிப்பாடாக தொகுக்கக்கூடிய எந்த சரமும் அல்ல - வழக்கமான வெளிப்பாடுகளை உருவாக்குவதற்கான விதிகளுக்கு இணங்கக்கூடிய சரங்கள் மட்டுமே. தொடரியல் மொழி விவரக்குறிப்பில் வரையறுக்கப்பட்டுள்ளது. வழக்கமான வெளிப்பாடுகள் எழுத்துகள் மற்றும் எண்களைப் பயன்படுத்தி எழுதப்படுகின்றன, அதே போல் மெட்டாக்ராக்டர்கள், அவை வழக்கமான வெளிப்பாடு தொடரியல் சிறப்புப் பொருளைக் கொண்ட எழுத்துக்களாகும். உதாரணத்திற்கு:
String regex = "java"; // The pattern is "java";
String regex = "\\d{3}"; // The pattern is three digits;
ஜாவாவில் வழக்கமான வெளிப்பாடுகளை உருவாக்குதல்
ஜாவாவில் வழக்கமான வெளிப்பாட்டை உருவாக்குவது இரண்டு எளிய படிகளை உள்ளடக்கியது:- வழக்கமான வெளிப்பாடு தொடரியல் இணங்கும் ஒரு சரமாக எழுதவும்;
- சரத்தை வழக்கமான வெளிப்பாடாக தொகுக்கவும்;
Patternஎந்த ஜாவா நிரலிலும், ஒரு பொருளை உருவாக்குவதன் மூலம் வழக்கமான வெளிப்பாடுகளுடன் வேலை செய்யத் தொடங்குகிறோம் . இதைச் செய்ய, வகுப்பின் இரண்டு நிலையான முறைகளில் ஒன்றை நாம் அழைக்க வேண்டும்: compile. முதல் முறை ஒரு வாதத்தை எடுக்கும் - வழக்கமான வெளிப்பாட்டைக் கொண்ட ஒரு சரம், இரண்டாவது முறை-பொருந்தும் அமைப்புகளைத் தீர்மானிக்கும் கூடுதல் வாதத்தை எடுக்கும்:
public static Pattern compile (String literal)
public static Pattern compile (String literal, int flags)
flagsவரையறுக்கப்பட்டுள்ளது Patternமற்றும் நிலையான வகுப்பு மாறிகளாக நமக்குக் கிடைக்கிறது. உதாரணத்திற்கு:
Pattern pattern = Pattern.compile("java", Pattern.CASE_INSENSITIVE); // Pattern-matching will be case insensitive.
Patternவகுப்பு என்பது வழக்கமான வெளிப்பாடுகளுக்கான கட்டமைப்பாகும். ஹூட்டின் கீழ், தொகுக்கப்பட்ட பிரதிநிதித்துவத்தை உருவாக்க இந்த compileமுறை வகுப்பின் தனிப்பட்ட கட்டமைப்பாளரை அழைக்கிறது . Patternஇந்த பொருள்-உருவாக்கம் பொறிமுறையானது மாறாத பொருட்களை உருவாக்குவதற்காக இந்த வழியில் செயல்படுத்தப்படுகிறது. வழக்கமான வெளிப்பாடு உருவாக்கப்படும் போது, அதன் தொடரியல் சரிபார்க்கப்படும். சரத்தில் பிழைகள் இருந்தால், a PatternSyntaxExceptionஉருவாக்கப்படும்.
வழக்கமான வெளிப்பாடு தொடரியல்
வழக்கமான வெளிப்பாடு தொடரியல் எழுத்துக்களை சார்ந்துள்ளது<([{\^-=$!|]})?*+.>, அவை எழுத்துக்களுடன் இணைக்கப்படலாம். அவற்றின் பங்கைப் பொறுத்து, அவை பல குழுக்களாகப் பிரிக்கப்படுகின்றன:
| மெட்டா கேரக்டர் | விளக்கம் |
|---|---|
| ^ | ஒரு வரியின் ஆரம்பம் |
| $ | ஒரு வரியின் முடிவு |
| \b | வார்த்தை எல்லை |
| \B | வார்த்தை அல்லாத எல்லை |
| \A | உள்ளீட்டின் ஆரம்பம் |
| \G | முந்தைய போட்டியின் முடிவு |
| \Z | உள்ளீட்டின் முடிவு |
| \z | உள்ளீட்டின் முடிவு |
| மெட்டா கேரக்டர் | விளக்கம் |
|---|---|
| \d | இலக்கம் |
| \D | இலக்கமற்ற |
| \s | வெண்வெளி எழுத்து |
| \S | வெள்ளைவெளி அல்லாத எழுத்து |
| \w | எண்ணெழுத்து எழுத்து அல்லது அடிக்கோடு |
| \W | எழுத்துக்கள், எண்கள் மற்றும் அடிக்கோடினைத் தவிர எந்த எழுத்தும் |
| . | எந்த பாத்திரம் |

| மெட்டா கேரக்டர் | விளக்கம் |
|---|---|
| \t | தாவல் எழுத்து |
| \n | புதிய வரி எழுத்து |
| \r | வண்டி திரும்புதல் |
| \f | வரிவடிவம் பாத்திரம் |
| \u0085 | அடுத்த வரி பாத்திரம் |
| \u2028 | வரி பிரிப்பான் |
| \u2029 | பத்தி பிரிப்பான் |
| மெட்டா கேரக்டர் | விளக்கம் |
|---|---|
| [abc] | பட்டியலிடப்பட்ட எழுத்துக்களில் ஏதேனும் (a, b, அல்லது c) |
| [^abc] | பட்டியலிடப்பட்டவை தவிர வேறு எந்த எழுத்தும் (a, b அல்லது c அல்ல) |
| [a-zA-Z] | இணைக்கப்பட்ட வரம்புகள் (a முதல் z வரையிலான லத்தீன் எழுத்துக்கள், கேஸ் சென்சிட்டிவ்) |
| [ad[mp]] | எழுத்துகளின் ஒன்றியம் (a முதல் d வரை மற்றும் m முதல் p வரை) |
| [az&&[def]] | எழுத்துக்களின் குறுக்குவெட்டு (d, e, f) |
| [az&&[^bc]] | எழுத்துக்களின் கழித்தல் (a, dz) |
| மெட்டா கேரக்டர் | விளக்கம் |
|---|---|
| ? | ஒன்று அல்லது இல்லை |
| * | பூஜ்யம் அல்லது அதற்கு மேற்பட்ட முறை |
| + | ஒன்று அல்லது அதற்கு மேற்பட்ட முறை |
| {n} | n முறை |
| {n,} | n அல்லது அதற்கு மேற்பட்ட முறை |
| {n,m} | குறைந்தபட்சம் n முறை மற்றும் m முறைக்கு மேல் இல்லை |
பேராசை கொண்ட அளவுகோல்கள்
அளவுகோல்களைப் பற்றி நீங்கள் தெரிந்து கொள்ள வேண்டிய ஒன்று, அவை மூன்று வெவ்வேறு வகைகளில் வருகின்றன: பேராசை, உடைமை மற்றும் தயக்கம்.+குவாண்டிஃபையருக்குப் பிறகு ஒரு " " எழுத்தைச் சேர்ப்பதன் மூலம் நீங்கள் ஒரு குவாண்டிஃபையரை உடைமையாக்குகிறீர்கள் . " "ஐச் சேர்ப்பதன் மூலம் அதை தயக்கமடையச் செய்கிறீர்கள் ?. உதாரணத்திற்கு:
"A.+a" // greedy
"A.++a" // possessive
"A.+?a" // reluctant
public static void main(String[] args) {
String text = "Fred Anna Alexander";
Pattern pattern = Pattern.compile("A.+a");
Matcher matcher = pattern.matcher(text);
while (matcher.find()) {
System.out.println(text.substring(matcher.start(), matcher.end()));
}
}
Anna Alexa
A.+a"க்கு, முறை-பொருத்தம் பின்வருமாறு செய்யப்படுகிறது:
-
குறிப்பிடப்பட்ட வடிவத்தில் முதல் எழுத்து லத்தீன் எழுத்து
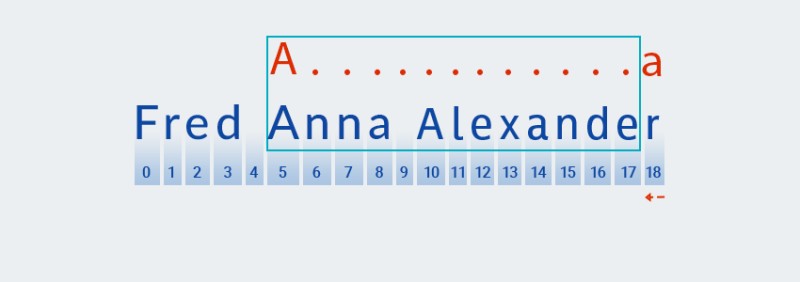
A.Matcherகுறியீட்டு பூஜ்ஜியத்திலிருந்து தொடங்கி, உரையின் ஒவ்வொரு எழுத்துடனும் ஒப்பிடுகிறது. எழுத்துFஎங்கள் உரையில் குறியீட்டு பூஜ்ஜியத்தில் உள்ளது, எனவேMatcherஅது வடிவத்துடன் பொருந்தும் வரை எழுத்துகள் மூலம் மீண்டும் மீண்டும் வருகிறது. எங்கள் எடுத்துக்காட்டில், இந்த எழுத்து குறியீட்டு 5 இல் காணப்படுகிறது.![ஜாவாவில் வழக்கமான வெளிப்பாடுகள் - 2]()
-
வடிவத்தின் முதல் எழுத்துடன் பொருத்தம் கண்டறியப்பட்டதும்,
Matcherஅதன் இரண்டாவது எழுத்துடன் பொருத்தத்தைத் தேடுகிறது. எங்கள் விஷயத்தில், இது "."எழுத்து, எந்த ஒரு பாத்திரத்தையும் குறிக்கிறது.![ஜாவாவில் வழக்கமான வெளிப்பாடுகள் - 3]()
பாத்திரம்
nஆறாவது இடத்தில் உள்ளது. இது நிச்சயமாக "எந்தவொரு பாத்திரத்திற்கும்" பொருத்தமாக இருக்கும். -
Matcherவடிவத்தின் அடுத்த எழுத்தை சரிபார்க்க தொடர்கிறது. எங்கள் வடிவத்தில், இது முந்தைய எழுத்துக்கு பொருந்தும் அளவுகோலில் சேர்க்கப்பட்டுள்ளது: ".+". நமது பேட்டர்னில் "எந்த எழுத்தும்" மீண்டும் மீண்டும் வருவதின் எண்ணிக்கை ஒன்று அல்லது அதற்கு மேற்பட்ட முறை என்பதால்,Matcherசரத்திலிருந்து அடுத்த எழுத்தை மீண்டும் மீண்டும் எடுத்து, அது "எந்த எழுத்துடன்" பொருந்துகிறதோ, அந்த வடிவத்திற்கு எதிராக அதைச் சரிபார்க்கவும். எங்கள் எடுத்துக்காட்டில் - சரத்தின் இறுதி வரை (இன்டெக்ஸ் 7 முதல் இன்டெக்ஸ் 18 வரை).![ஜாவாவில் வழக்கமான வெளிப்பாடுகள் - 4]()
அடிப்படையில்,
Matcherசரத்தை இறுதிவரை கொப்பளிக்கிறது - இது துல்லியமாக "பேராசை" என்பதன் பொருள். -
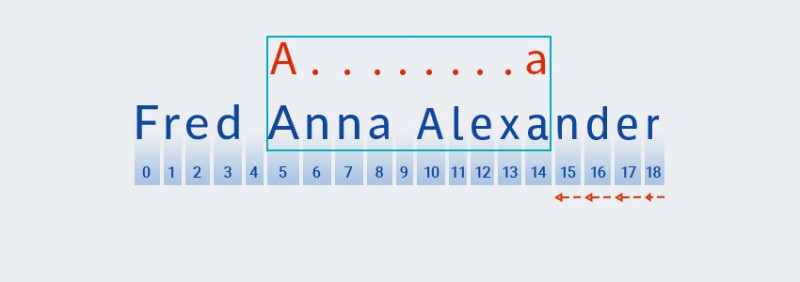
மேட்சர் உரையின் முடிவை அடைந்து, பேட்டர்னின் "" பகுதியைச் சரிபார்த்த பிறகு
A.+, அது மீதமுள்ள பேட்டர்னைச் சரிபார்க்கத் தொடங்குகிறது:a. முன்னோக்கி எந்த உரையும் இல்லை, எனவே காசோலை கடைசி எழுத்தில் இருந்து "பேக் ஆஃப்" மூலம் தொடர்கிறது:![ஜாவாவில் வழக்கமான வெளிப்பாடுகள் - 5]()
-
Matcher.+வடிவத்தின் " " பகுதியில் மீண்டும் மீண்டும் எண்ணிக்கையை "நினைவில் கொள்கிறது" . இந்த கட்டத்தில், இது மீண்டும் மீண்டும் செய்யும் எண்ணிக்கையை ஒன்று குறைக்கிறது மற்றும் ஒரு பொருத்தம் கண்டறியப்படும் வரை உரைக்கு எதிராக பெரிய வடிவத்தை சரிபார்க்கிறது:![ஜாவாவில் வழக்கமான வெளிப்பாடுகள் - 6]()



உடைமை அளவுகோல்கள்
உடைமை அளவுகோல்கள் பேராசை கொண்டவை போன்றவை. வித்தியாசம் என்னவென்றால், சரத்தின் இறுதிவரை உரை எடுக்கப்பட்டால், "பேக் ஆஃப்" செய்யும் போது பேட்டர்ன்-மேட்ச் இல்லை. வேறு வார்த்தைகளில் கூறுவதானால், முதல் மூன்று நிலைகளும் பேராசை கொண்ட அளவுகோல்களைப் போலவே இருக்கும். முழு சரத்தையும் கைப்பற்றிய பிறகு, மேட்ச் செய்பவர் அது கருத்தில் கொண்டவற்றுடன் மீதமுள்ள வடிவத்தைச் சேர்த்து, கைப்பற்றப்பட்ட சரத்துடன் ஒப்பிடுகிறார். எங்கள் எடுத்துக்காட்டில், "A.++a" வழக்கமான வெளிப்பாட்டைப் பயன்படுத்தி, முக்கிய முறை எந்தப் பொருத்தத்தையும் காணவில்லை. 
தயக்கம் காட்டுபவர்கள்
-
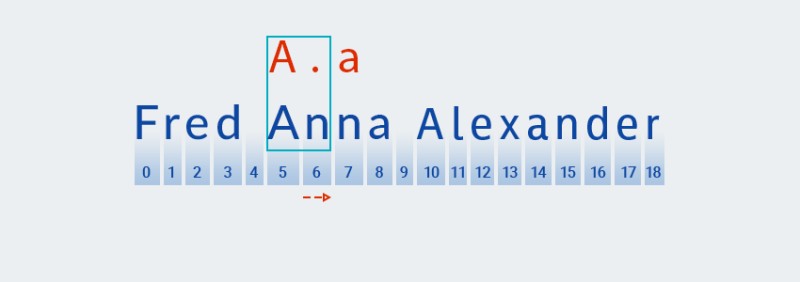
இந்த அளவுகோல்களுக்கு, பேராசை கொண்ட வகையைப் போலவே, குறியீடு வடிவத்தின் முதல் எழுத்தின் அடிப்படையில் ஒரு பொருத்தத்தைத் தேடுகிறது:
![ஜாவாவில் வழக்கமான வெளிப்பாடுகள் - 8]()
-
பின்னர் அது மாதிரியின் அடுத்த எழுத்துடன் (எந்த எழுத்தும்) பொருத்தத்தைத் தேடுகிறது:
![ஜாவாவில் வழக்கமான வெளிப்பாடுகள் - 9]()
-
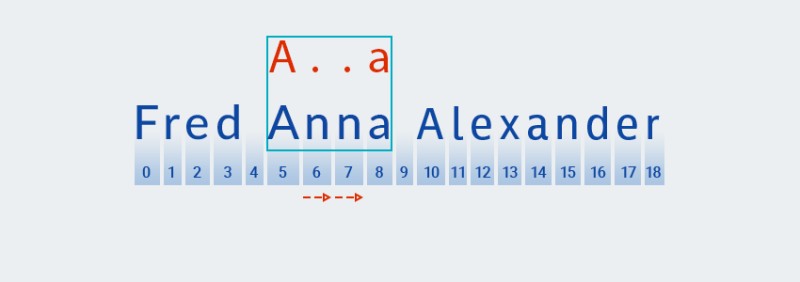
பேராசை கொண்ட மாதிரி-பொருத்தம் போலல்லாமல், தயக்கத்துடன் மாதிரி-பொருத்தத்தில் குறுகிய பொருத்தம் தேடப்படுகிறது. இதன் பொருள், பேட்டர்னின் இரண்டாவது எழுத்துடன் (உரையில் 6வது இடத்தில் உள்ள எழுத்துக்கு ஒத்திருக்கும் ஒரு காலகட்டம்,
Matcherஉரையானது மீதமுள்ள வடிவத்துடன் பொருந்துகிறதா என்பதைச் சரிபார்க்கிறது - "a"![ஜாவாவில் வழக்கமான வெளிப்பாடுகள் - 10]()
-
உரையானது வடிவத்துடன் பொருந்தவில்லை (அதாவது இது
nகுறியீட்டு 7 இல் " " என்ற எழுத்தைக் கொண்டுள்ளது), எனவேMatcherமேலும் ஒன்று "எந்த எழுத்துகளையும்" சேர்க்கிறது, ஏனெனில் அளவுகோல் ஒன்று அல்லது அதற்கு மேற்பட்டதைக் குறிக்கிறது. பின்னர் அது மீண்டும் வடிவத்தை 5 முதல் 8 நிலைகளில் உள்ள உரையுடன் ஒப்பிடுகிறது:![ஜாவாவில் வழக்கமான வெளிப்பாடுகள் - 11]()


எங்கள் விஷயத்தில், ஒரு பொருத்தம் கண்டறியப்பட்டது, ஆனால் நாங்கள் இன்னும் உரையின் முடிவை அடையவில்லை. எனவே, பேட்டர்ன்-பொருத்தம் நிலை 9 இலிருந்து மறுதொடக்கம் செய்யப்படுகிறது, அதாவது மாதிரியின் முதல் எழுத்து ஒரே மாதிரியான அல்காரிதத்தைப் பயன்படுத்துவதைத் தேடுகிறது, மேலும் இது உரையின் இறுதி வரை மீண்டும் நிகழும்.

main"" வடிவத்தைப் பயன்படுத்தும் போது இந்த முறை பின்வரும் முடிவைப் பெறுகிறது A.+?a: அண்ணா அலெக்சா எங்கள் எடுத்துக்காட்டில் இருந்து நீங்கள் பார்க்க முடியும், வெவ்வேறு வகையான அளவீடுகள் ஒரே மாதிரிக்கு வெவ்வேறு முடிவுகளைத் தருகின்றன. எனவே இதை மனதில் வைத்து, நீங்கள் தேடுவதைப் பொறுத்து சரியான வகையைத் தேர்ந்தெடுக்கவும்.
வழக்கமான வெளிப்பாடுகளில் எஸ்கேப்பிங் கேரக்டர்கள்
ஜாவாவில் ஒரு வழக்கமான வெளிப்பாடு, அல்லது அதற்கு மாறாக, அதன் அசல் பிரதிநிதித்துவம், ஒரு சரம் இலக்கியமாக இருப்பதால், சரம் எழுத்துகள் தொடர்பான ஜாவா விதிகளை நாம் கணக்கிட வேண்டும். குறிப்பாக,\ஜாவா மூலக் குறியீட்டில் உள்ள ஸ்ட்ரிங் லிட்டரலில் உள்ள பின்சாய்வு எழுத்து "" ஒரு கட்டுப்பாட்டு எழுத்து என விளக்கப்படுகிறது, இது அடுத்த எழுத்து சிறப்பு மற்றும் ஒரு சிறப்பு வழியில் விளக்கப்பட வேண்டும் என்று கம்பைலருக்குக் கூறுகிறது. உதாரணத்திற்கு:
String s = "The root directory is \nWindows"; // Move "Windows" to a new line
String s = "The root directory is \u00A7Windows"; // Insert a paragraph symbol before "Windows"
\" எழுத்துக்களை (அதாவது மெட்டாக்ராக்டர்களைக் குறிக்க) பயன்படுத்தும் சரம் எழுத்துகள், ஜாவா பைட்கோட் கம்பைலர் சரத்தை தவறாகப் புரிந்து கொள்ளாமல் இருப்பதை உறுதிசெய்ய பின்சாய்வுகளை மீண்டும் செய்ய வேண்டும். உதாரணத்திற்கு:
String regex = "\\s"; // Pattern for matching a whitespace character
String regex = "\"Windows\""; // Pattern for matching "Windows"
String regex = "How\\?"; // Pattern for matching "How?"
வடிவ வகுப்பின் முறைகள்
Patternவழக்கமான வெளிப்பாடுகளுடன் வேலை செய்வதற்கான பிற முறைகள் வகுப்பில் உள்ளன :
-
String pattern()‒ பொருளை உருவாக்கப் பயன்படுத்தப்படும் வழக்கமான வெளிப்பாட்டின் அசல் சரம் பிரதிநிதித்துவத்தை வழங்குகிறதுPattern:Pattern pattern = Pattern.compile("abc"); System.out.println(pattern.pattern()); // "abc" -
static boolean matches(String regex, CharSequence input)- என அனுப்பப்பட்ட உரைக்கு எதிராக ரெஜெக்ஸாக அனுப்பப்பட்ட வழக்கமான வெளிப்பாட்டை சரிபார்க்க உங்களை அனுமதிக்கிறதுinput. வருமானம்:உண்மை - உரை வடிவத்துடன் பொருந்தினால்;
பொய் - அது இல்லை என்றால்;உதாரணத்திற்கு:
System.out.println(Pattern.matches("A.+a","Anna")); // true System.out.println(Pattern.matches("A.+a","Fred Anna Alexander")); // false -
int flags()‒ பேட்டர்ன் உருவாக்கப்பட்ட போது பேட்டர்ன் அளவுரு தொகுப்பின் மதிப்பைflagsஅல்லது அளவுரு அமைக்கப்படாவிட்டால் 0 ஐ வழங்குகிறது. உதாரணத்திற்கு:Pattern pattern = Pattern.compile("abc"); System.out.println(pattern.flags()); // 0 Pattern pattern = Pattern.compile("abc",Pattern.CASE_INSENSITIVE); System.out.println(pattern.flags()); // 2 -
String[] split(CharSequence text, int limit)- அனுப்பப்பட்ட உரையை அணிவரிசையாகப் பிரிக்கிறதுString.limitஉரையில் தேடப்பட்ட பொருத்தங்களின் அதிகபட்ச எண்ணிக்கையை அளவுரு குறிக்கிறது :- பொருந்தினால் ;
limit > 0_limit-1 limit < 0உரையில் உள்ள அனைத்தும் பொருந்தினால்- ‒ உரையில் உள்ள அனைத்து பொருத்தங்களும் இருந்தால்
limit = 0, வரிசையின் முடிவில் உள்ள வெற்று சரங்கள் நிராகரிக்கப்படும்;
உதாரணத்திற்கு:
public static void main(String[] args) { String text = "Fred Anna Alexa"; Pattern pattern = Pattern.compile("\\s"); String[] strings = pattern.split(text,2); for (String s : strings) { System.out.println(s); } System.out.println("---------"); String[] strings1 = pattern.split(text); for (String s : strings1) { System.out.println(s); } }கன்சோல் வெளியீடு:
Fred Anna Alexa --------- Fred Anna Alexaஒரு பொருளை உருவாக்கப் பயன்படுத்தப்படும் மற்றொரு வகுப்பின் முறைகளை கீழே கருத்தில் கொள்வோம்
Matcher. - பொருந்தினால் ;
மேட்சர் வகுப்பின் முறைகள்
வகுப்பின் நிகழ்வுகள்Matcherபேட்டர்ன்-மேட்ச்சிங் செய்ய உருவாக்கப்பட்டன. Matcherவழக்கமான வெளிப்பாடுகளுக்கான "தேடுபொறி" ஆகும். ஒரு தேடலைச் செய்ய, நாம் அதற்கு இரண்டு விஷயங்களைக் கொடுக்க வேண்டும்: ஒரு முறை மற்றும் தொடக்கக் குறியீடு. Matcherஒரு பொருளை உருவாக்க , Patternவகுப்பு பின்வரும் முறையை வழங்குகிறது: рublic Matcher matcher(CharSequence input) முறை ஒரு எழுத்து வரிசையை எடுக்கும், அது தேடப்படும். இது இடைமுகத்தை செயல்படுத்தும் ஒரு வகுப்பின் உதாரணம் CharSequence. நீங்கள் ஒரு String, ஆனால் a StringBuffer, StringBuilder, Segmentஅல்லது CharBuffer. முறை என்பது ஒரு Patternபொருளாகும், அதில் matcherமுறை அழைக்கப்படுகிறது. பொருத்தியை உருவாக்குவதற்கான எடுத்துக்காட்டு:
Pattern p = Pattern.compile("a*b"); // Create a compiled representation of the regular expression
Matcher m = p.matcher("aaaaab"); // Create a "search engine" to search the text "aaaaab" for the pattern "a*b"

boolean find()முறை உரையில் அடுத்த பொருத்தத்தைத் தேடுகிறது. நிகழ்வு மாதிரியின் ஒரு பகுதியாக முழு உரையையும் பகுப்பாய்வு செய்ய இந்த முறை மற்றும் லூப் அறிக்கையைப் பயன்படுத்தலாம். வேறு வார்த்தைகளில் கூறுவதானால், ஒரு நிகழ்வு நிகழும்போது, அதாவது உரையில் ஒரு பொருத்தத்தைக் கண்டறியும்போது தேவையான செயல்பாடுகளை நாம் செய்யலாம். எடுத்துக்காட்டாக, உரையில் பொருத்தத்தின் நிலையைத் தீர்மானிக்க இந்த வகுப்பையும் முறைகளையும் int start()பயன்படுத்தலாம் . மற்றும் மாற்று அளவுருவின் மதிப்புடன் பொருத்தங்களை மாற்றுவதற்கு மற்றும் முறைகளைப் int end()பயன்படுத்தலாம் . உதாரணத்திற்கு: String replaceFirst(String replacement)String replaceAll(String replacement)
public static void main(String[] args) {
String text = "Fred Anna Alexa";
Pattern pattern = Pattern.compile("A.+?a");
Matcher matcher = pattern.matcher(text);
while (matcher.find()) {
int start=matcher.start();
int end=matcher.end();
System.out.println("Match found: " + text.substring(start, end) + " from index "+ start + " through " + (end-1));
}
System.out.println(matcher.replaceFirst("Ira"));
System.out.println(matcher.replaceAll("Mary"));
System.out.println(text);
}
Match found: Anna from index 5 through 8
Match found: Alexa from index 10 through 14
Fred Ira Alexa
Fred Mary Mary
Fred Anna Alexa
replaceFirstமற்றும் replaceAllமுறைகள் ஒரு புதிய பொருளை உருவாக்குகின்றன என்பதை எடுத்துக்காட்டு தெளிவுபடுத்துகிறது String- அசல் உரையில் உள்ள மாதிரி பொருத்தங்கள் ஒரு வாதமாக முறைக்கு அனுப்பப்பட்ட உரையால் மாற்றப்படும். கூடுதலாக, replaceFirstமுறை முதல் பொருத்தத்தை மட்டுமே மாற்றுகிறது, ஆனால் இந்த replaceAllமுறை உரையில் உள்ள அனைத்து பொருத்தங்களையும் மாற்றுகிறது. அசல் உரை மாறாமல் உள்ளது. மற்றும் வகுப்புகளின் அடிக்கடி Patternரீஜெக்ஸ் Matcherசெயல்பாடுகள் வகுப்பிலேயே கட்டமைக்கப்படுகின்றன String. splitஇவை , matches, replaceFirstமற்றும் போன்ற முறைகள் replaceAll. ஆனால் ஹூட்டின் கீழ், இந்த முறைகள் Patternமற்றும் Matcherவகுப்புகளைப் பயன்படுத்துகின்றன. எனவே நீங்கள் எந்த கூடுதல் குறியீட்டையும் எழுதாமல் ஒரு நிரலில் உரையை மாற்றவோ அல்லது சரங்களை ஒப்பிடவோ விரும்பினால், முறைகளைப் பயன்படுத்தவும்Stringவர்க்கம். உங்களுக்கு மேம்பட்ட அம்சங்கள் தேவைப்பட்டால், Patternமற்றும் Matcherவகுப்புகளை நினைவில் கொள்ளுங்கள்.
முடிவுரை
ஒரு ஜாவா நிரலில், வழக்கமான வெளிப்பாடு என்பது குறிப்பிட்ட வடிவ-பொருத்த விதிகளுக்குக் கீழ்ப்படியும் ஒரு சரத்தால் வரையறுக்கப்படுகிறது. குறியீட்டை இயக்கும் போது, ஜாவா இயந்திரம் இந்த சரத்தை ஒரு பொருளாக தொகுத்து , உரையில் உள்ள பொருத்தங்களைக் கண்டறியPatternஒரு பொருளைப் பயன்படுத்துகிறது . Matcherநான் ஆரம்பத்தில் சொன்னது போல், மக்கள் பெரும்பாலும் வழக்கமான வெளிப்பாடுகளை பின்னர் தள்ளி வைக்கிறார்கள், அவை கடினமான தலைப்பு என்று கருதுகின்றனர். ஆனால் அடிப்படை தொடரியல், மெட்டாக்ராக்டர்கள் மற்றும் எழுத்து தப்பித்தல் மற்றும் வழக்கமான வெளிப்பாடுகளின் எடுத்துக்காட்டுகளைப் படித்தால், அவை முதல் பார்வையில் தோன்றுவதை விட மிகவும் எளிமையானவை என்பதை நீங்கள் காண்பீர்கள்.
|
மேலும் வாசிப்பு: |
|---|
GO TO FULL VERSION