
Was ist ein regulärer Ausdruck (Regex)?
Tatsächlich ist ein regulärer Ausdruck ein Muster zum Suchen einer Zeichenfolge im Text. In Java ist die ursprüngliche Darstellung dieses Musters immer ein String, also ein Objekt derStringKlasse. Es handelt sich jedoch nicht um irgendeine Zeichenfolge, die in einen regulären Ausdruck kompiliert werden kann, sondern nur um Zeichenfolgen, die den Regeln zum Erstellen regulärer Ausdrücke entsprechen.
Die Syntax ist in der Sprachspezifikation definiert. Reguläre Ausdrücke werden aus Buchstaben und Zahlen sowie aus Metazeichen geschrieben, bei denen es sich um Zeichen handelt, die in der Syntax regulärer Ausdrücke eine besondere Bedeutung haben. Zum Beispiel:
String regex = "java"; // The pattern is "java";
String regex = "\\d{3}"; // The pattern is three digits;
Erstellen regulärer Ausdrücke in Java
Das Erstellen eines regulären Ausdrucks in Java umfasst zwei einfache Schritte:- Schreiben Sie es als Zeichenfolge, die der Syntax regulärer Ausdrücke entspricht.
- Kompilieren Sie die Zeichenfolge in einen regulären Ausdruck.
PatternObjekt erstellen. Dazu müssen wir eine der beiden statischen Methoden der Klasse aufrufen: compile.
Die erste Methode benötigt ein Argument – ein String-Literal, das den regulären Ausdruck enthält, während die zweite ein zusätzliches Argument benötigt, das die Mustervergleichseinstellungen bestimmt:
public static Pattern compile (String literal)
public static Pattern compile (String literal, int flags)
flagsParameters ist in der Klasse definiert Patternund steht uns als statische Klassenvariablen zur Verfügung. Zum Beispiel:
Pattern pattern = Pattern.compile("java", Pattern.CASE_INSENSITIVE); // Pattern-matching will be case insensitive.
PatternKlasse ein Konstruktor für reguläre Ausdrücke. Unter der Haube ruft die compileMethode den Patternprivaten Konstruktor der Klasse auf, um eine kompilierte Darstellung zu erstellen. Dieser Objekterstellungsmechanismus wird auf diese Weise implementiert, um unveränderliche Objekte zu erstellen. Beim Erstellen eines regulären Ausdrucks wird seine Syntax überprüft. Wenn die Zeichenfolge Fehler enthält, PatternSyntaxExceptionwird ein generiert.Syntax für reguläre Ausdrücke
Die Syntax regulärer Ausdrücke basiert auf den<([{\^-=$!|]})?*+.>Zeichen, die mit Buchstaben kombiniert werden können. Abhängig von ihrer Rolle können sie in mehrere Gruppen eingeteilt werden:| Metazeichen | Beschreibung |
|---|---|
| ^ | Anfang einer Zeile |
| $ | Ende einer Zeile |
| \B | Wortgrenze |
| \B | Nicht-Wortgrenze |
| \A | Beginn der Eingabe |
| \G | Ende des vorherigen Spiels |
| \Z | Ende der Eingabe |
| \z | Ende der Eingabe |
| Metazeichen | Beschreibung |
|---|---|
| \D | Ziffer |
| \D | nicht numerisch |
| \S | Leerzeichen |
| \S | Nicht-Leerzeichen |
| \w | alphanumerisches Zeichen oder Unterstrich |
| \W | jedes Zeichen außer Buchstaben, Zahlen und Unterstrich |
| . | irgendein Charakter |
| Metazeichen | Beschreibung |
|---|---|
| \T | Tabulatorzeichen |
| \N | Newline-Zeichen |
| \R | Wagenrücklauf |
| \F | Zeilenvorschubzeichen |
| \u0085 | Zeichen der nächsten Zeile |
| \u2028 | Zeilentrenner |
| \u2029 | Absatztrennzeichen |
| Metazeichen | Beschreibung |
|---|---|
| [ABC] | eines der aufgeführten Zeichen (a, b oder c) |
| [^abc] | alle anderen als die aufgeführten Zeichen (nicht a, b oder c) |
| [a-zA-Z] | zusammengeführte Bereiche (lateinische Zeichen von a bis z, Groß- und Kleinschreibung wird nicht beachtet) |
| [Anzeige[mp]] | Vereinigung von Zeichen (von a bis d und von m bis p) |
| [az&&[def]] | Schnittpunkt der Zeichen (d, e, f) |
| [az&&[^bc]] | Subtraktion von Zeichen (a, dz) |
| Metazeichen | Beschreibung |
|---|---|
| ? | einer oder keiner |
| * | Null oder mehrmals |
| + | einmal oder mehrmals |
| {N} | n mal |
| {N,} | n oder öfter |
| {n,m} | mindestens n-mal und höchstens m-mal |

Gierige Quantoren
Eine Sache, die Sie über Quantifizierer wissen sollten, ist, dass es sie in drei verschiedenen Varianten gibt: gierig, besitzergreifend und widerstrebend. Sie machen einen Quantor possessiv, indem Sie nach dem Quantor ein „ “-Zeichen hinzufügen+. Sie machen es widerwillig, indem Sie „ ?“ hinzufügen. Zum Beispiel:
"A.+a" // greedy
"A.++a" // possessive
"A.+?a" // reluctant
public static void main(String[] args) {
String text = "Fred Anna Alexander";
Pattern pattern = Pattern.compile("A.+a");
Matcher matcher = pattern.matcher(text);
while (matcher.find()) {
System.out.println(text.substring(matcher.start(), matcher.end()));
}
}
Anna Alexa
A.+a“ wird der Mustervergleich wie folgt durchgeführt:
-
Das erste Zeichen im angegebenen Muster ist der lateinische Buchstabe
A.Matchervergleicht es mit jedem Zeichen des Textes, beginnend mit Index Null. Das ZeichenFbefindet sich in unserem Text am Index Null undMatcherdurchläuft daher die Zeichen, bis es mit dem Muster übereinstimmt. In unserem Beispiel befindet sich dieses Zeichen an Index 5.![Reguläre Ausdrücke in Java - 2]()
-
Sobald eine Übereinstimmung mit dem ersten Zeichen des Musters gefunden wird,
Matcherwird nach einer Übereinstimmung mit dem zweiten Zeichen gesucht. In unserem Fall ist es das.Zeichen „ “, das für ein beliebiges Zeichen steht.![Reguläre Ausdrücke in Java - 3]()
Der Charakter
nsteht an sechster Stelle. Es eignet sich auf jeden Fall als Übereinstimmung mit „jedem Zeichen“. -
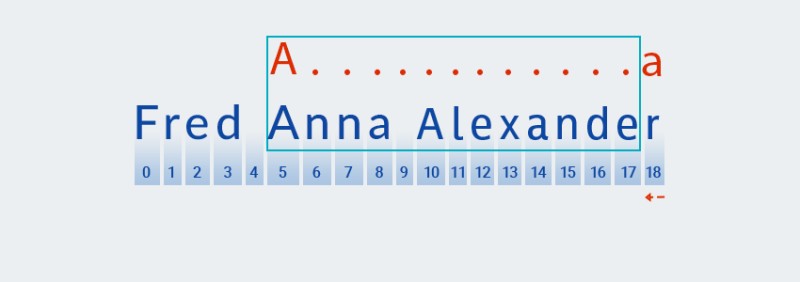
Matcherfährt mit der Prüfung des nächsten Zeichens des Musters fort. In unserem Muster ist es im Quantor enthalten, der für das vorhergehende Zeichen gilt: „.+“. Da die Anzahl der Wiederholungen von „beliebigem Zeichen“ in unserem Muster ein oder mehrere Male beträgt,Matchernimmt wiederholt das nächste Zeichen aus der Zeichenfolge und vergleicht es mit dem Muster, solange es mit „beliebigem Zeichen“ übereinstimmt. In unserem Beispiel – bis zum Ende der Zeichenfolge (von Index 7 bis Index 18).![Reguläre Ausdrücke in Java - 4]()
Im Grunde genommen
Matcherverschlingt es die Saite bis zum Ende – genau das ist mit „gierig“ gemeint. -
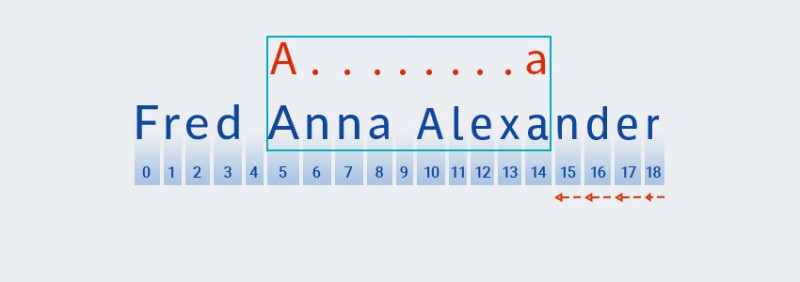
Nachdem Matcher das Ende des Texts erreicht und die Prüfung für den
A.+Teil „ “ des Musters abgeschlossen hat, beginnt er mit der Prüfung für den Rest des Musters:a. Es gibt keinen weiteren Text mehr, daher wird die Prüfung mit einem „Rückschritt“ fortgesetzt, beginnend mit dem letzten Zeichen:![Reguläre Ausdrücke in Java - 5]()
-
Matcher„merkt“ sich die Anzahl der Wiederholungen im „.+“-Teil des Musters. An diesem Punkt wird die Anzahl der Wiederholungen um eins reduziert und das größere Muster mit dem Text verglichen, bis eine Übereinstimmung gefunden wird:![Reguläre Ausdrücke in Java - 6]()



Possessive Quantoren
Possessive Quantoren sind den gierigen Quantoren sehr ähnlich. Der Unterschied besteht darin, dass, wenn Text bis zum Ende der Zeichenfolge erfasst wurde, beim „Zurückziehen“ kein Mustervergleich erfolgt. Mit anderen Worten: Die ersten drei Stufen sind die gleichen wie bei gierigen Quantoren. Nachdem der gesamte String erfasst wurde, fügt der Matcher den Rest des Musters zu dem hinzu, was er berücksichtigt, und vergleicht ihn mit dem erfassten String. In unserem BeispielA.++afindet die Hauptmethode unter Verwendung des regulären Ausdrucks „ “ keine Übereinstimmung. 
Widerstrebende Quantifizierer
-
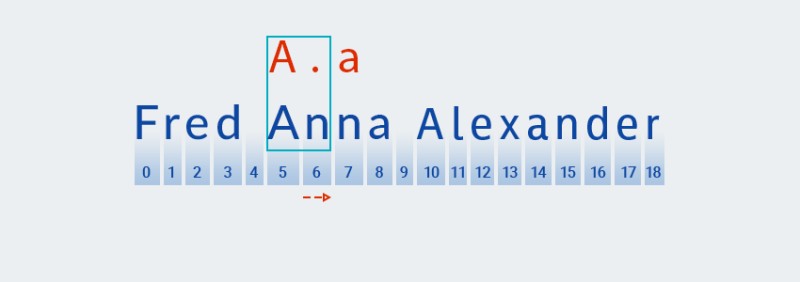
Für diese Quantifizierer sucht der Code wie bei der Greedy-Variante nach einer Übereinstimmung basierend auf dem ersten Zeichen des Musters:
![Reguläre Ausdrücke in Java - 8]()
-
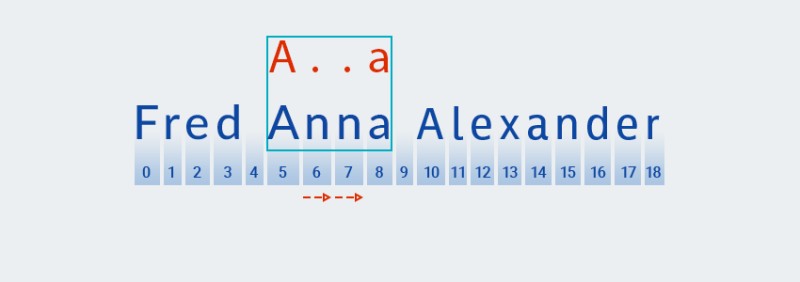
Dann sucht es nach einer Übereinstimmung mit dem nächsten Zeichen des Musters (einem beliebigen Zeichen):
![Reguläre Ausdrücke in Java - 9]()
-
Im Gegensatz zum gierigen Mustervergleich wird beim widerstrebenden Mustervergleich nach der kürzesten Übereinstimmung gesucht. Dies bedeutet, dass nach dem Finden einer Übereinstimmung mit dem zweiten Zeichen des Musters (ein Punkt, der dem Zeichen an Position 6 im Text entspricht) geprüft wird,
Matcherob der Text mit dem Rest des Musters – dem Zeichen „ “, übereinstimmta.![Reguläre Ausdrücke in Java - 10]()
-
Der Text stimmt nicht mit dem Muster überein (dh er enthält das Zeichen „
n“ an Index 7), daherMatcherwird ein weiteres „beliebiges Zeichen“ hinzugefügt, da der Quantor ein oder mehrere angibt. Anschließend wird das Muster erneut mit dem Text an den Positionen 5 bis 8 verglichen:![Reguläre Ausdrücke in Java - 11]()


In unserem Fall wurde eine Übereinstimmung gefunden, aber wir sind noch nicht am Ende des Textes angelangt. Daher beginnt der Mustervergleich ab Position 9 erneut, dh mit einem ähnlichen Algorithmus wird nach dem ersten Zeichen des Musters gesucht und dies bis zum Ende des Textes wiederholt.

mainerhält die Methode bei Verwendung des Musters „ “ das folgende Ergebnis A.+?a: Anna Alexa Wie Sie an unserem Beispiel sehen können, führen verschiedene Arten von Quantoren für dasselbe Muster zu unterschiedlichen Ergebnissen. Denken Sie also daran und wählen Sie die richtige Sorte basierend auf Ihren Wünschen.Escapezeichen in regulären Ausdrücken
Da ein regulärer Ausdruck in Java bzw. seine ursprüngliche Darstellung ein String-Literal ist, müssen wir Java-Regeln für String-Literale berücksichtigen. Insbesondere das Backslash-Zeichen „\“ in Zeichenfolgenliteralen im Java-Quellcode wird als Steuerzeichen interpretiert, das dem Compiler mitteilt, dass das nächste Zeichen etwas Besonderes ist und auf besondere Weise interpretiert werden muss. Zum Beispiel:
String s = "The root directory is \nWindows"; // Move "Windows" to a new line
String s = "The root directory is \u00A7Windows"; // Insert a paragraph symbol before "Windows"
\“-Zeichen verwenden (z. B. zur Angabe von Metazeichen), die Backslashes wiederholen müssen, um sicherzustellen, dass der Java-Bytecode-Compiler die Zeichenfolge nicht falsch interpretiert. Zum Beispiel:
String regex = "\\s"; // Pattern for matching a whitespace character
String regex = "\"Windows\""; // Pattern for matching "Windows"
String regex = "How\\?"; // Pattern for matching "How?"
Methoden der Pattern-Klasse
DiePatternKlasse verfügt über weitere Methoden zum Arbeiten mit regulären Ausdrücken:
-
String pattern()‒ gibt die ursprüngliche Zeichenfolgendarstellung des regulären Ausdrucks zurück, die zum Erstellen desPatternObjekts verwendet wurde:Pattern pattern = Pattern.compile("abc"); System.out.println(pattern.pattern()); // "abc" -
static boolean matches(String regex, CharSequence input)– ermöglicht es Ihnen, den als Regex übergebenen regulären Ausdruck mit dem als übergebenen Text zu vergleicheninput. Kehrt zurück:true – wenn der Text mit dem Muster übereinstimmt;
false – wenn nicht;Zum Beispiel:
System.out.println(Pattern.matches("A.+a","Anna")); // true System.out.println(Pattern.matches("A.+a","Fred Anna Alexander")); // false -
int flags()‒ gibt den Wert desflagsParametersatzes des Musters zurück, als das Muster erstellt wurde, oder 0, wenn der Parameter nicht festgelegt wurde. Zum Beispiel:Pattern pattern = Pattern.compile("abc"); System.out.println(pattern.flags()); // 0 Pattern pattern = Pattern.compile("abc",Pattern.CASE_INSENSITIVE); System.out.println(pattern.flags()); // 2 -
String[] split(CharSequence text, int limit)– teilt den übergebenen Text in einStringArray auf. DerlimitParameter gibt die maximale Anzahl der im Text gesuchten Treffer an:- wenn
limit > 0‒limit-1passt; - wenn
limit < 0‒ alle Übereinstimmungen im Text - Wenn
limit = 0‒ alle Übereinstimmungen im Text vorliegen, werden leere Zeichenfolgen am Ende des Arrays verworfen.
Zum Beispiel:
public static void main(String[] args) { String text = "Fred Anna Alexa"; Pattern pattern = Pattern.compile("\\s"); String[] strings = pattern.split(text,2); for (String s : strings) { System.out.println(s); } System.out.println("---------"); String[] strings1 = pattern.split(text); for (String s : strings1) { System.out.println(s); } }Konsolenausgabe:
Fred Anna Alexa --------- Fred Anna AlexaIm Folgenden betrachten wir eine weitere Methode der Klasse, die zum Erstellen eines
MatcherObjekts verwendet wird. - wenn
Methoden der Matcher-Klasse
Instanzen derMatcherKlasse werden erstellt, um einen Mustervergleich durchzuführen. Matcherist die „Suchmaschine“ für reguläre Ausdrücke.
Um eine Suche durchzuführen, müssen wir ihr zwei Dinge geben: ein Muster und einen Startindex. Um ein MatcherObjekt zu erstellen, Patternstellt die Klasse die folgende Methode zur Verfügung: рublic Matcher matcher(CharSequence input) Die Methode benötigt eine Zeichenfolge, die durchsucht wird.
Dies ist eine Instanz einer Klasse, die die CharSequenceSchnittstelle implementiert. StringSie können nicht nur ein , sondern auch ein StringBuffer, StringBuilder, Segmentoder übergeben CharBuffer. Das Muster ist ein PatternObjekt, für das die matcherMethode aufgerufen wird. Beispiel für die Erstellung eines Matchers:
Pattern p = Pattern.compile("a*b"); // Create a compiled representation of the regular expression
Matcher m = p.matcher("aaaaab"); // Create a "search engine" to search the text "aaaaab" for the pattern "a*b"

boolean find()Methode sucht nach der nächsten Übereinstimmung im Text.
Mit dieser Methode und einer Schleifenanweisung können wir einen gesamten Text als Teil eines Ereignismodells analysieren. Mit anderen Worten: Wir können notwendige Operationen durchführen, wenn ein Ereignis eintritt, also wenn wir eine Übereinstimmung im Text finden. Beispielsweise können wir die Klassen int start()und int end()Methoden dieser Klasse verwenden, um die Position einer Übereinstimmung im Text zu bestimmen.
String replaceFirst(String replacement)Und wir können die Methoden und verwenden String replaceAll(String replacement), um Übereinstimmungen durch den Wert des Ersetzungsparameters zu ersetzen. Zum Beispiel:
public static void main(String[] args) {
String text = "Fred Anna Alexa";
Pattern pattern = Pattern.compile("A.+?a");
Matcher matcher = pattern.matcher(text);
while (matcher.find()) {
int start=matcher.start();
int end=matcher.end();
System.out.println("Match found: " + text.substring(start, end) + " from index "+ start + " through " + (end-1));
}
System.out.println(matcher.replaceFirst("Ira"));
System.out.println(matcher.replaceAll("Mary"));
System.out.println(text);
}
Match found: Anna from index 5 through 8
Match found: Alexa from index 10 through 14
Fred Ira Alexa
Fred Mary Mary
Fred Anna Alexa
replaceFirstund replaceAllein neues StringObjekt erstellen – eine Zeichenfolge, in der Musterübereinstimmungen im Originaltext durch den Text ersetzt werden, der als Argument an die Methode übergeben wird.
Darüber hinaus ersetzt die replaceFirstMethode nur die erste Übereinstimmung, aber die replaceAllMethode ersetzt alle Übereinstimmungen im Text. Der Originaltext bleibt unverändert. Die häufigsten Regex-Operationen der Klassen Patternund sind direkt in die Klasse integriert. Dies sind Methoden wie , , , und.
Aber unter der Haube nutzen diese Methoden die Klassen und . Wenn Sie also in einem Programm Text ersetzen oder Zeichenfolgen vergleichen möchten, ohne zusätzlichen Code zu schreiben, verwenden Sie die Methoden vonMatcher String split matches replaceFirst replaceAll Pattern Matcher StringKlasse. Wenn Sie erweiterte Funktionen benötigen, denken Sie an die Klassen Patternund Matcher.
Abschluss
In einem Java-Programm wird ein regulärer Ausdruck durch eine Zeichenfolge definiert, die bestimmte Mustervergleichsregeln befolgt. Beim Ausführen von Code kompiliert die Java-Maschine diese Zeichenfolge in einPatternObjekt und verwendet ein MatcherObjekt, um Übereinstimmungen im Text zu finden.
Wie ich eingangs sagte, schieben die Leute reguläre Ausdrücke oft auf später, weil sie sie für ein schwieriges Thema halten. Wenn Sie jedoch die grundlegende Syntax, Metazeichen und Zeichen-Escapezeichen verstehen und Beispiele für reguläre Ausdrücke studieren, werden Sie feststellen, dass diese viel einfacher sind, als sie auf den ersten Blick erscheinen.|
Mehr Lektüre: |
|---|
GO TO FULL VERSION