
रेग्युलर एक्सप्रेशन (रेजेक्स) म्हणजे काय?
खरं तर, रेग्युलर एक्सप्रेशन हा मजकूरातील स्ट्रिंग शोधण्याचा नमुना आहे. Java मध्ये, या पॅटर्नचे मूळ प्रतिनिधित्व नेहमी एक स्ट्रिंग असते, म्हणजे वर्गाची एक वस्तूString. तथापि, ही कोणतीही स्ट्रिंग नाही जी नियमित अभिव्यक्तीमध्ये संकलित केली जाऊ शकते — फक्त स्ट्रिंग जे नियमित अभिव्यक्ती तयार करण्याच्या नियमांचे पालन करतात. वाक्यरचना भाषेच्या विशिष्टतेमध्ये परिभाषित केली आहे. रेग्युलर एक्स्प्रेशन्स अक्षरे आणि संख्या, तसेच मेटा कॅरेक्टर्स वापरून लिहिली जातात, जी रेग्युलर एक्सप्रेशन सिंटॅक्समध्ये विशेष अर्थ असलेले वर्ण आहेत. उदाहरणार्थ:
String regex = "java"; // The pattern is "java";
String regex = "\\d{3}"; // The pattern is three digits;
Java मध्ये रेग्युलर एक्सप्रेशन तयार करणे
Java मध्ये नियमित अभिव्यक्ती तयार करण्यासाठी दोन सोप्या चरणांचा समावेश आहे:- रेग्युलर एक्सप्रेशन सिंटॅक्सचे पालन करणारी स्ट्रिंग म्हणून लिहा;
- स्ट्रिंग नियमित अभिव्यक्तीमध्ये संकलित करा;
Patternऑब्जेक्ट तयार करून रेग्युलर एक्सप्रेशनसह कार्य करण्यास सुरवात करतो. हे करण्यासाठी, आपल्याला वर्गाच्या दोन स्थिर पद्धतींपैकी एक कॉल करणे आवश्यक आहे: compile. पहिली पद्धत एक युक्तिवाद घेते — नियमित अभिव्यक्ती असलेली स्ट्रिंग शब्दशः, तर दुसरी एक अतिरिक्त युक्तिवाद घेते जी पॅटर्न-मॅचिंग सेटिंग्ज निर्धारित करते:
public static Pattern compile (String literal)
public static Pattern compile (String literal, int flags)
flagsपरिभाषित केली आहे Patternआणि आमच्यासाठी स्थिर वर्ग व्हेरिएबल्स म्हणून उपलब्ध आहे. उदाहरणार्थ:
Pattern pattern = Pattern.compile("java", Pattern.CASE_INSENSITIVE); // Pattern-matching will be case insensitive.
Patternवर्ग हा रेग्युलर एक्स्प्रेशनसाठी एक कन्स्ट्रक्टर आहे. हुड अंतर्गत, पद्धत संकलित प्रतिनिधित्व तयार करण्यासाठी वर्गाच्या खाजगी कन्स्ट्रक्टरला compileकॉल करते . Patternअपरिवर्तनीय वस्तू तयार करण्यासाठी ही ऑब्जेक्ट-निर्मिती यंत्रणा अशा प्रकारे लागू केली जाते. रेग्युलर एक्सप्रेशन तयार केल्यावर त्याची वाक्यरचना तपासली जाते. जर स्ट्रिंगमध्ये त्रुटी असतील, तर a PatternSyntaxExceptionव्युत्पन्न होईल.
नियमित अभिव्यक्ती वाक्यरचना
रेग्युलर एक्सप्रेशन सिंटॅक्स अक्षरांवर अवलंबून असते<([{\^-=$!|]})?*+.>, जे अक्षरांसह एकत्र केले जाऊ शकते. त्यांच्या भूमिकेनुसार, त्यांना अनेक गटांमध्ये विभागले जाऊ शकते:
| मेटाकॅरेक्टर | वर्णन |
|---|---|
| ^ | एका ओळीची सुरुवात |
| $ | एका ओळीचा शेवट |
| \b | शब्द सीमा |
| \B | शब्द नसलेली सीमा |
| \A | इनपुटची सुरुवात |
| \G | मागील सामन्याचा शेवट |
| \Z | इनपुटचा शेवट |
| \z | इनपुटचा शेवट |
| मेटाकॅरेक्टर | वर्णन |
|---|---|
| \d | अंक |
| \D | अंक नसलेला |
| \s | व्हाइटस्पेस वर्ण |
| \S | नॉन-व्हाइटस्पेस वर्ण |
| \w | अल्फान्यूमेरिक वर्ण किंवा अंडरस्कोर |
| \W | अक्षरे, संख्या आणि अंडरस्कोर वगळता कोणतेही वर्ण |
| . | कोणतेही पात्र |

| मेटाकॅरेक्टर | वर्णन |
|---|---|
| \ट | टॅब वर्ण |
| \n | नवीन पात्र |
| \r | कॅरेज रिटर्न |
| \f | लाइनफीड वर्ण |
| \u0085 | पुढील ओळीतील वर्ण |
| \u2028 | रेषा विभाजक |
| \u2029 | परिच्छेद विभाजक |
| मेटाकॅरेक्टर | वर्णन |
|---|---|
| [abc] | सूचीबद्ध वर्णांपैकी कोणतेही (a, b, किंवा c) |
| [^abc] | सूचीबद्ध केलेल्या व्यतिरिक्त कोणतेही वर्ण (a, b, किंवा c नाही) |
| [a-zA-Z] | विलीन केलेल्या श्रेणी (a ते z पर्यंत लॅटिन वर्ण, केस असंवेदनशील) |
| [जाहिरात [एमपी]] | वर्णांचे संघटन (a ते d आणि m ते p) |
| [az&&[def]] | वर्णांचे छेदनबिंदू (d, e, f) |
| [az&&[^bc]] | वर्णांची वजाबाकी (a, dz) |
| मेटाकॅरेक्टर | वर्णन |
|---|---|
| ? | एक किंवा काहीही नाही |
| * | शून्य किंवा अधिक वेळा |
| + | एक किंवा अधिक वेळा |
| {n} | n वेळा |
| {n,} | n किंवा अधिक वेळा |
| {n,m} | किमान n वेळा आणि m पेक्षा जास्त वेळा नाही |
लोभी परिमाणक
क्वांटिफायर्सबद्दल तुम्हाला एक गोष्ट माहित असणे आवश्यक आहे की ते तीन वेगवेगळ्या प्रकारांमध्ये येतात: लोभी, मालक आणि अनिच्छुक.+क्वांटिफायर नंतर " " वर्ण जोडून तुम्ही क्वांटिफायरला मालक बनवता . तुम्ही " " जोडून ते अनिच्छुक बनवता ?. उदाहरणार्थ:
"A.+a" // greedy
"A.++a" // possessive
"A.+?a" // reluctant
public static void main(String[] args) {
String text = "Fred Anna Alexander";
Pattern pattern = Pattern.compile("A.+a");
Matcher matcher = pattern.matcher(text);
while (matcher.find()) {
System.out.println(text.substring(matcher.start(), matcher.end()));
}
}
Anna Alexa
A.+a" साठी, पॅटर्न-मॅचिंग खालीलप्रमाणे केले जाते:
-
निर्दिष्ट पॅटर्नमधील पहिले वर्ण हे लॅटिन अक्षर आहे
A.Matcherअनुक्रमणिका शून्यापासून प्रारंभ करून मजकूराच्या प्रत्येक वर्णाशी त्याची तुलना करते. आमच्या मजकुरात वर्णFअनुक्रमणिका शून्यावर आहे, म्हणूनMatcherते पॅटर्नशी जुळत नाही तोपर्यंत वर्णांद्वारे पुनरावृत्ती होते. आमच्या उदाहरणात, हा वर्ण अनुक्रमणिका 5 वर आढळतो.![जावा मधील नियमित अभिव्यक्ती - 2]()
-
पॅटर्नच्या पहिल्या वर्णासह जुळणी आढळल्यानंतर,
Matcherत्याच्या दुसऱ्या वर्णासह जुळणी शोधते. आमच्या बाबतीत, हे "." वर्ण आहे, जे कोणत्याही वर्णासाठी आहे.![जावा मधील रेग्युलर एक्सप्रेशन्स - 3]()
पात्र
nसहाव्या स्थानावर आहे. हे निश्चितपणे "कोणत्याही पात्रासाठी" जुळणी म्हणून पात्र ठरते. -
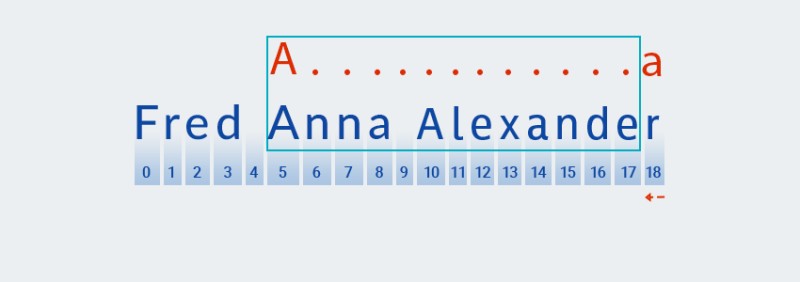
Matcherपॅटर्नचे पुढील वर्ण तपासण्यासाठी पुढे जा. आमच्या पॅटर्नमध्ये, हे क्वांटिफायरमध्ये समाविष्ट केले आहे जे आधीच्या वर्णाला लागू होते: ".+". आमच्या पॅटर्नमधील "कोणत्याही वर्ण" च्या पुनरावृत्तीची संख्या एक किंवा अधिक वेळा असल्याने,Matcherस्ट्रिंगमधून पुढील वर्ण वारंवार घेतो आणि जोपर्यंत ते "कोणत्याही वर्ण" शी जुळत आहे तोपर्यंत ते पॅटर्नच्या विरूद्ध तपासते. आमच्या उदाहरणात - स्ट्रिंगच्या शेवटपर्यंत (इंडेक्स 7 पासून इंडेक्स 18 पर्यंत).![जावा मधील नियमित अभिव्यक्ती - 4]()
मुळात,
Matcherस्ट्रिंग शेवटपर्यंत गुंडाळते — "लोभी" म्हणजे नेमके हेच आहे. -
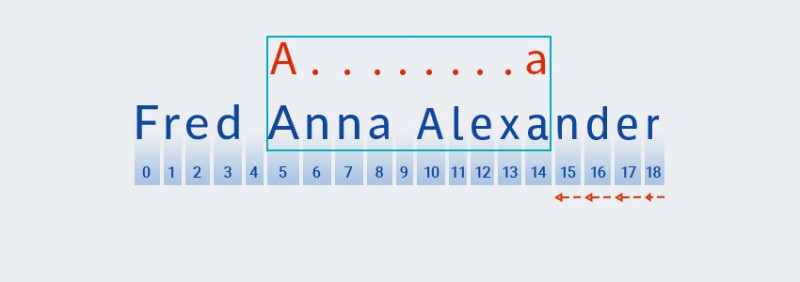
मॅचर मजकूराच्या शेवटी पोहोचल्यानंतर आणि पॅटर्नच्या " " भागाची तपासणी पूर्ण केल्यानंतर
A.+, तो उर्वरित नमुना तपासण्यास सुरुवात करतो:a. पुढे कोणताही मजकूर नाही, म्हणून चेक "बॅक ऑफ" करून पुढे जातो, शेवटच्या वर्णापासून सुरू होतो:![जावा मधील नियमित अभिव्यक्ती - 5]()
-
Matcher.+पॅटर्नच्या " " भागामध्ये पुनरावृत्तीची संख्या "लक्षात ठेवते" . या टप्प्यावर, ते पुनरावृत्तीची संख्या एकाने कमी करते आणि जोपर्यंत जुळणी सापडत नाही तोपर्यंत मजकूराच्या विरूद्ध मोठा नमुना तपासतो:![जावा मधील रेग्युलर एक्सप्रेशन्स - 6]()



पॉससिव्ह क्वांटिफायर
पझेसिव्ह क्वांटिफायर हे लोभी लोकांसारखे असतात. फरक असा आहे की जेव्हा मजकूर स्ट्रिंगच्या शेवटी कॅप्चर केला जातो, तेव्हा "बॅक ऑफ" करताना कोणतेही पॅटर्न-मॅचिंग नसते. दुसऱ्या शब्दांत, पहिले तीन टप्पे लोभी क्वांटिफायर्ससाठी समान आहेत. संपूर्ण स्ट्रिंग कॅप्चर केल्यानंतर, मॅचर उर्वरित पॅटर्न ज्याचा विचार करत आहे त्यात जोडतो आणि कॅप्चर केलेल्या स्ट्रिंगशी त्याची तुलना करतो. आमच्या उदाहरणात, रेग्युलर एक्स्प्रेशन "A.++a" वापरून, मुख्य पद्धतीला काही जुळत नाही. 
अनिच्छुक परिमाण
-
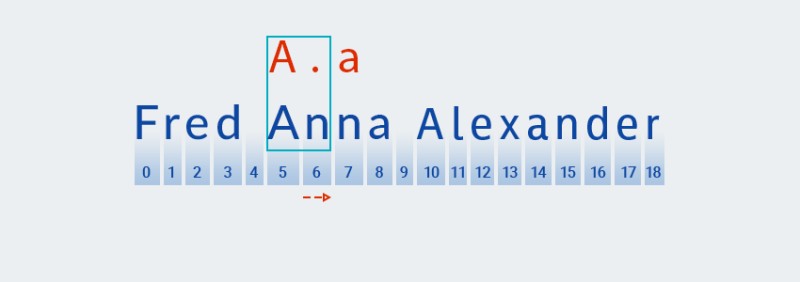
या क्वांटिफायरसाठी, लोभी विविधतेप्रमाणे, कोड पॅटर्नच्या पहिल्या वर्णावर आधारित जुळणी शोधतो:
![जावा मधील नियमित अभिव्यक्ती - 8]()
-
नंतर ते पॅटर्नच्या पुढील वर्ण (कोणतेही वर्ण) शी जुळणी शोधते:
![जावा मधील नियमित अभिव्यक्ती - 9]()
-
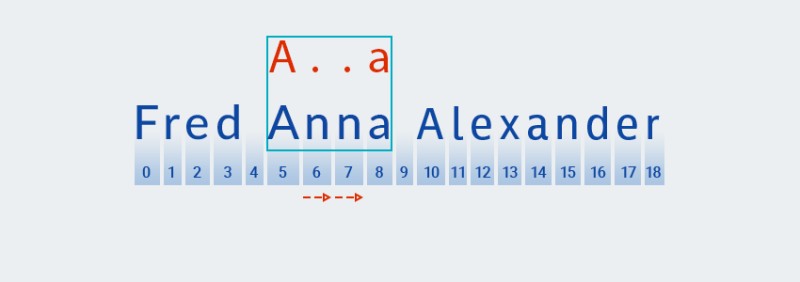
लोभी पॅटर्न-मॅचिंगच्या विपरीत, सर्वात लहान जुळणी अनिच्छुक पॅटर्न-मॅचिंगमध्ये शोधली जाते. याचा अर्थ असा की पॅटर्नच्या दुसर्या वर्णाशी जुळणी शोधल्यानंतर (एक कालावधी, जो मजकूरातील स्थान 6 वरील वर्णाशी संबंधित आहे,
Matcherमजकूर उर्वरित पॅटर्नशी जुळतो की नाही ते तपासतो — " "aअक्षर![जावा मधील रेग्युलर एक्सप्रेशन्स - 10]()
-
मजकूर पॅटर्नशी जुळत नाही (म्हणजे निर्देशांक 7 वर " " वर्ण आहे
n), म्हणूनMatcherआणखी एक "कोणताही वर्ण" जोडतो, कारण क्वांटिफायर एक किंवा अधिक सूचित करतो. मग ते पुन्हा 5 ते 8 पोझिशन्समधील मजकुराशी पॅटर्नची तुलना करते:![जावा मधील रेग्युलर एक्सप्रेशन्स - 11]()


आमच्या बाबतीत, एक जुळणी आढळली आहे, परंतु आम्ही अद्याप मजकूराच्या शेवटी पोहोचलो नाही. म्हणून, पॅटर्न-मॅचिंग पोझिशन 9 पासून रीस्टार्ट होते, म्हणजे पॅटर्नचा पहिला वर्ण समान अल्गोरिदम वापरण्यासाठी पाहिला जातो आणि मजकूराच्या शेवटपर्यंत हे पुनरावृत्ती होते.

mainपॅटर्न " " वापरताना पद्धत खालील परिणाम प्राप्त करते A.+?a: अॅना अलेक्सा तुम्ही आमच्या उदाहरणावरून पाहू शकता की, वेगवेगळ्या प्रकारचे क्वांटिफायर एकाच पॅटर्नसाठी वेगवेगळे परिणाम देतात. त्यामुळे हे लक्षात ठेवा आणि तुम्ही जे शोधत आहात त्यावर आधारित योग्य विविधता निवडा.
रेग्युलर एक्स्प्रेशन्समध्ये एस्केपिंग कॅरेक्टर्स
जावामधील रेग्युलर एक्सप्रेशन, किंवा त्याऐवजी, त्याचे मूळ प्रतिनिधित्व हे स्ट्रिंग लिटरल असल्यामुळे, आम्हाला स्ट्रिंग लिटरलशी संबंधित जावा नियमांचा विचार करणे आवश्यक आहे. विशेषतः,\जावा सोर्स कोडमधील स्ट्रिंग लिटरल्समधील बॅकस्लॅश कॅरेक्टर " " चा एक कंट्रोल कॅरेक्टर म्हणून अर्थ लावला जातो जो कंपायलरला सांगते की पुढील कॅरेक्टर स्पेशल आहे आणि त्याचा विशिष्ट पद्धतीने अर्थ लावला पाहिजे. उदाहरणार्थ:
String s = "The root directory is \nWindows"; // Move "Windows" to a new line
String s = "The root directory is \u00A7Windows"; // Insert a paragraph symbol before "Windows"
\" अक्षरे वापरणाऱ्या स्ट्रिंग लिटरल्सने (म्हणजे मेटाकॅरेक्टर्स दर्शवण्यासाठी) बॅकस्लॅशची पुनरावृत्ती करणे आवश्यक आहे हे सुनिश्चित करण्यासाठी की Java bytecode कंपाइलर स्ट्रिंगचा चुकीचा अर्थ लावत नाही. उदाहरणार्थ:
String regex = "\\s"; // Pattern for matching a whitespace character
String regex = "\"Windows\""; // Pattern for matching "Windows"
String regex = "How\\?"; // Pattern for matching "How?"
नमुना वर्गाच्या पद्धती
Patternरेग्युलर एक्स्प्रेशनसह काम करण्यासाठी वर्गाकडे इतर पद्धती आहेत :
-
String pattern()‒ ऑब्जेक्ट तयार करण्यासाठी वापरल्या जाणार्या रेग्युलर एक्स्प्रेशनचे मूळ स्ट्रिंग प्रतिनिधित्व परत करतेPattern:Pattern pattern = Pattern.compile("abc"); System.out.println(pattern.pattern()); // "abc" -
static boolean matches(String regex, CharSequence input)– तुम्हाला रेग्युलर एक्सप्रेशन म्हणून पास केलेल्या मजकुराच्या विरुद्ध रेग्युलर एक्सप्रेशन तपासू देतेinput. परतावा:खरे - जर मजकूर पॅटर्नशी जुळत असेल;
असत्य - तसे नसल्यास;उदाहरणार्थ:
System.out.println(Pattern.matches("A.+a","Anna")); // true System.out.println(Pattern.matches("A.+a","Fred Anna Alexander")); // false -
int flags()‒ पॅटर्न तयार केल्यावर पॅटर्नच्या पॅरामीटर सेटचे मूल्यflagsकिंवा पॅरामीटर सेट केले नसल्यास 0 मिळवते. उदाहरणार्थ:Pattern pattern = Pattern.compile("abc"); System.out.println(pattern.flags()); // 0 Pattern pattern = Pattern.compile("abc",Pattern.CASE_INSENSITIVE); System.out.println(pattern.flags()); // 2 -
String[] split(CharSequence text, int limit)- पास केलेला मजकूर अॅरेमध्ये विभाजित करतोString. पॅरामीटरlimitमजकूरात शोधलेल्या जुळण्यांची कमाल संख्या दर्शवते:- जर
limit > 0-limit-1जुळते; - जर
limit < 0- मजकूरातील सर्व जुळतात - जर
limit = 0- मजकूरातील सर्व जुळण्या, अॅरेच्या शेवटी रिक्त स्ट्रिंग टाकून दिल्या जातात;
उदाहरणार्थ:
public static void main(String[] args) { String text = "Fred Anna Alexa"; Pattern pattern = Pattern.compile("\\s"); String[] strings = pattern.split(text,2); for (String s : strings) { System.out.println(s); } System.out.println("---------"); String[] strings1 = pattern.split(text); for (String s : strings1) { System.out.println(s); } }कन्सोल आउटपुट:
Fred Anna Alexa --------- Fred Anna Alexaखाली आपण ऑब्जेक्ट तयार करण्यासाठी वापरल्या जाणार्या क्लासच्या इतर पद्धतींचा विचार करू
Matcher. - जर
मॅचर वर्गाच्या पद्धती
Matcherपॅटर्न-मॅचिंग करण्यासाठी वर्गाची उदाहरणे तयार केली जातात. Matcherनियमित अभिव्यक्तीसाठी "शोध इंजिन" आहे. शोध करण्यासाठी, आम्हाला दोन गोष्टी द्याव्या लागतील: एक नमुना आणि प्रारंभिक अनुक्रमणिका. ऑब्जेक्ट तयार करण्यासाठी Matcher, Patternवर्ग खालील पद्धत प्रदान करतो: рublic Matcher matcher(CharSequence input) पद्धत एक वर्ण क्रम घेते, ज्याचा शोध घेतला जाईल. इंटरफेस लागू करणाऱ्या वर्गाचे हे उदाहरण आहे CharSequence. तुम्ही फक्त a नाही Stringतर a StringBuffer, StringBuilder, Segment, किंवा सुद्धा पास करू शकता CharBuffer. नमुना एक Patternऑब्जेक्ट आहे ज्यावर matcherपद्धत म्हणतात. मॅचर तयार करण्याचे उदाहरण:
Pattern p = Pattern.compile("a*b"); // Create a compiled representation of the regular expression
Matcher m = p.matcher("aaaaab"); // Create a "search engine" to search the text "aaaaab" for the pattern "a*b"

boolean find()मजकूरात पुढील जुळणी शोधते. इव्हेंट मॉडेलचा भाग म्हणून संपूर्ण मजकूराचे विश्लेषण करण्यासाठी आपण ही पद्धत आणि लूप स्टेटमेंट वापरू शकतो. दुसऱ्या शब्दांत, जेव्हा एखादी घटना घडते, म्हणजे जेव्हा आपल्याला मजकुरात जुळणी आढळते तेव्हा आम्ही आवश्यक ऑपरेशन्स करू शकतो. उदाहरणार्थ, मजकूरातील जुळणीची स्थिती निश्चित करण्यासाठी आम्ही हा वर्ग int start()आणि पद्धती वापरू शकतो. आणि बदली पॅरामीटरच्या मूल्यासह जुळण्या बदलण्यासाठी आणि पद्धती int end()वापरू शकतो . उदाहरणार्थ: String replaceFirst(String replacement)String replaceAll(String replacement)
public static void main(String[] args) {
String text = "Fred Anna Alexa";
Pattern pattern = Pattern.compile("A.+?a");
Matcher matcher = pattern.matcher(text);
while (matcher.find()) {
int start=matcher.start();
int end=matcher.end();
System.out.println("Match found: " + text.substring(start, end) + " from index "+ start + " through " + (end-1));
}
System.out.println(matcher.replaceFirst("Ira"));
System.out.println(matcher.replaceAll("Mary"));
System.out.println(text);
}
Match found: Anna from index 5 through 8
Match found: Alexa from index 10 through 14
Fred Ira Alexa
Fred Mary Mary
Fred Anna Alexa
replaceFirstआणि replaceAllपद्धती एक नवीन Stringऑब्जेक्ट तयार करतात — एक स्ट्रिंग ज्यामध्ये मूळ मजकुरातील पॅटर्न जुळते ते आर्ग्युमेंट म्हणून मेथडला पाठवलेल्या मजकुराने बदलले जाते. याव्यतिरिक्त, replaceFirstपद्धत केवळ पहिल्या जुळणीची जागा घेते, परंतु replaceAllपद्धत मजकूरातील सर्व जुळण्या पुनर्स्थित करते. मूळ मजकूर अपरिवर्तित राहतो. आणि वर्गांची सर्वाधिक वारंवार होणारी regex ऑपरेशन्स अगदी वर्गात तयार Patternकेली Matcherजातात String. या पद्धती आहेत जसे की split, matches, replaceFirst, आणि replaceAll. परंतु हुड अंतर्गत, या पद्धती Patternआणि Matcherवर्ग वापरतात. त्यामुळे तुम्हाला कोणताही अतिरिक्त कोड न लिहिता मजकूर बदलायचा असेल किंवा प्रोग्राममधील स्ट्रिंग्सची तुलना करायची असेल, तर या पद्धती वापरा.Stringवर्ग तुम्हाला अधिक प्रगत वैशिष्ट्यांची आवश्यकता असल्यास, Patternआणि Matcherवर्ग लक्षात ठेवा.
निष्कर्ष
जावा प्रोग्राममध्ये, रेग्युलर एक्सप्रेशनची व्याख्या विशिष्ट पॅटर्न-जुळणाऱ्या नियमांचे पालन करणाऱ्या स्ट्रिंगद्वारे केली जाते. कोड कार्यान्वित करताना, Java मशीन ही स्ट्रिंग ऑब्जेक्टमध्ये संकलित करतेPatternआणि Matcherमजकूरातील जुळणी शोधण्यासाठी ऑब्जेक्ट वापरते. मी सुरुवातीला म्हटल्याप्रमाणे, लोक बरेचदा रेग्युलर एक्स्प्रेशन्स नंतरसाठी थांबवतात, त्यांना कठीण विषय समजतात. परंतु जर तुम्हाला मूलभूत वाक्यरचना, मेटाकॅरेक्टर्स आणि कॅरेक्टर एस्केपिंग समजले आणि रेग्युलर एक्स्प्रेशन्सच्या उदाहरणांचा अभ्यास केला, तर तुम्हाला ते पहिल्या दृष्टीक्षेपात दिसण्यापेक्षा ते खूपच सोपे असल्याचे दिसून येईल.
|
अधिक वाचन: |
|---|
GO TO FULL VERSION