
Biểu thức chính quy (regex) là gì?
Trên thực tế, một biểu thức chính quy là một mẫu để tìm một chuỗi trong văn bản. Trong Java, biểu diễn gốc của mẫu này luôn là một chuỗi, tức là một đối tượng của lớpString. Tuy nhiên, không phải bất kỳ chuỗi nào cũng có thể được biên dịch thành biểu thức chính quy — chỉ những chuỗi tuân theo quy tắc tạo biểu thức chính quy. Cú pháp được xác định trong đặc tả ngôn ngữ. Biểu thức chính quy được viết bằng các chữ cái và số, cũng như siêu ký tự, là những ký tự có ý nghĩa đặc biệt trong cú pháp biểu thức chính quy. Ví dụ:
String regex = "java"; // The pattern is "java";
String regex = "\\d{3}"; // The pattern is three digits;
Tạo biểu thức chính quy trong Java
Tạo một biểu thức chính quy trong Java bao gồm hai bước đơn giản:- viết nó dưới dạng một chuỗi tuân thủ cú pháp biểu thức chính quy;
- biên dịch chuỗi thành biểu thức chính quy;
Patternđối tượng. Để làm điều này, chúng ta cần gọi một trong hai phương thức tĩnh của lớp: compile. Phương thức đầu tiên nhận một đối số — một chuỗi ký tự chứa biểu thức chính quy, trong khi phương thức thứ hai nhận một đối số bổ sung xác định cài đặt khớp mẫu:
public static Pattern compile (String literal)
public static Pattern compile (String literal, int flags)
flagstham số được định nghĩa trong Patternlớp và có sẵn cho chúng tôi dưới dạng các biến lớp tĩnh. Ví dụ:
Pattern pattern = Pattern.compile("java", Pattern.CASE_INSENSITIVE); // Pattern-matching will be case insensitive.
Patternlớp là một hàm tạo cho các biểu thức chính quy. Về cơ bản, compilephương thức này gọi Patternhàm tạo riêng của lớp để tạo một biểu diễn được biên dịch. Cơ chế tạo đối tượng này được triển khai theo cách này để tạo các đối tượng không thể thay đổi. Khi một biểu thức chính quy được tạo, cú pháp của nó sẽ được kiểm tra. Nếu chuỗi chứa lỗi, thì a PatternSyntaxExceptionđược tạo.
cú pháp biểu thức chính quy
Cú pháp biểu thức chính quy dựa trên<([{\^-=$!|]})?*+.>các ký tự, có thể được kết hợp với các chữ cái. Tùy thuộc vào vai trò của họ, họ có thể được chia thành nhiều nhóm:
| siêu ký tự | Sự miêu tả |
|---|---|
| ^ | bắt đầu của một dòng |
| $ | kết thúc một dòng |
| \ b | Ranh giới từ |
| \B | ranh giới phi từ |
| \MỘT | đầu của đầu vào |
| \ G | kết thúc trận đấu trước |
| \Z | kết thúc đầu vào |
| \z | kết thúc đầu vào |
| siêu ký tự | Sự miêu tả |
|---|---|
| \d | chữ số |
| \Đ | không có chữ số |
| \S | ký tự khoảng trắng |
| \S | ký tự không phải khoảng trắng |
| \w | ký tự chữ và số hoặc dấu gạch dưới |
| \W | bất kỳ ký tự nào ngoại trừ chữ cái, số và dấu gạch dưới |
| . | ký tự bất kỳ |

| siêu ký tự | Sự miêu tả |
|---|---|
| \t | ký tự tab |
| \N | ký tự dòng mới |
| \ r | vận chuyển trở lại |
| \f | ký tự nguồn cấp dữ liệu |
| \u0085 | ký tự dòng tiếp theo |
| \u2028 | dấu tách dòng |
| \u2029 | dấu tách đoạn |
| siêu ký tự | Sự miêu tả |
|---|---|
| [abc] | bất kỳ ký tự nào được liệt kê (a, b hoặc c) |
| [^abc] | bất kỳ ký tự nào khác với những ký tự được liệt kê (không phải a, b hoặc c) |
| [a-zA-Z] | phạm vi được hợp nhất (ký tự Latinh từ a đến z, không phân biệt chữ hoa chữ thường) |
| [quảng cáo[mp]] | liên kết các ký tự (từ a đến d và từ m đến p) |
| [az&&[def]] | giao điểm của các ký tự (d, e, f) |
| [az&&[^bc]] | phép trừ các ký tự (a, dz) |
| siêu ký tự | Sự miêu tả |
|---|---|
| ? | một hoặc không |
| * | không hoặc nhiều lần |
| + | một hoặc nhiều lần |
| {N} | n lần |
| {N,} | n lần trở lên |
| {n,m} | ít nhất n lần và không quá m lần |
định lượng tham lam
Một điều bạn nên biết về các từ định lượng là chúng có ba loại khác nhau: tham lam, chiếm hữu và miễn cưỡng. Bạn tạo một bộ định lượng sở hữu bằng cách thêm một+ký tự " " sau bộ định lượng. Bạn làm cho nó miễn cưỡng bằng cách thêm " ?". Ví dụ:
"A.+a" // greedy
"A.++a" // possessive
"A.+?a" // reluctant
public static void main(String[] args) {
String text = "Fred Anna Alexander";
Pattern pattern = Pattern.compile("A.+a");
Matcher matcher = pattern.matcher(text);
while (matcher.find()) {
System.out.println(text.substring(matcher.start(), matcher.end()));
}
}
Anna Alexa
A.+a", khớp mẫu được thực hiện như sau:
-
Ký tự đầu tiên trong mẫu được chỉ định là chữ cái Latinh
A.Matcherso sánh nó với từng ký tự của văn bản, bắt đầu từ chỉ số 0. Ký tựFnằm ở chỉ mục 0 trong văn bản của chúng ta, vì vậyMatcherhãy lặp qua các ký tự cho đến khi nó khớp với mẫu. Trong ví dụ của chúng tôi, ký tự này được tìm thấy ở chỉ số 5.![Biểu thức chính quy trong Java - 2]()
-
Sau khi tìm thấy kết quả khớp với ký tự đầu tiên của mẫu,
Matcherhãy tìm kết quả khớp với ký tự thứ hai của nó. Trong trường hợp của chúng tôi, đó là.ký tự " ", viết tắt của bất kỳ ký tự nào.![Biểu thức chính quy trong Java - 3]()
Nhân vật
nở vị trí thứ sáu. Nó chắc chắn đủ điều kiện để khớp với "bất kỳ ký tự nào". -
Matchertiến hành kiểm tra ký tự tiếp theo của mẫu. Trong mẫu của chúng tôi, nó được bao gồm trong bộ định lượng áp dụng cho ký tự trước: ".+". Bởi vì số lần lặp lại của "ký tự bất kỳ" trong mẫu của chúng ta là một hoặc nhiều lần,Matcherliên tục lấy ký tự tiếp theo từ chuỗi và kiểm tra ký tự đó với mẫu miễn là ký tự đó khớp với "ký tự bất kỳ". Trong ví dụ của chúng tôi — cho đến khi kết thúc chuỗi (từ chỉ mục 7 đến chỉ mục 18).![Biểu thức chính quy trong Java - 4]()
Về cơ bản,
Matcherngấu nghiến sợi dây cho đến hết - đây chính xác là ý nghĩa của từ "tham lam". -
Sau khi Matcher đến cuối văn bản và hoàn tất việc kiểm tra
A.+phần " " của mẫu, nó sẽ bắt đầu kiểm tra phần còn lại của mẫu:a. Không có thêm văn bản nào ở phía trước, vì vậy quá trình kiểm tra tiếp tục bằng cách "lùi lại", bắt đầu từ ký tự cuối cùng:![Biểu thức chính quy trong Java - 5]()
-
Matcher"nhớ" số lần lặp lại trong.+phần " " của mẫu. Tại thời điểm này, nó giảm số lần lặp lại xuống một và kiểm tra mẫu lớn hơn so với văn bản cho đến khi tìm thấy kết quả khớp:![Biểu thức chính quy trong Java - 6]()



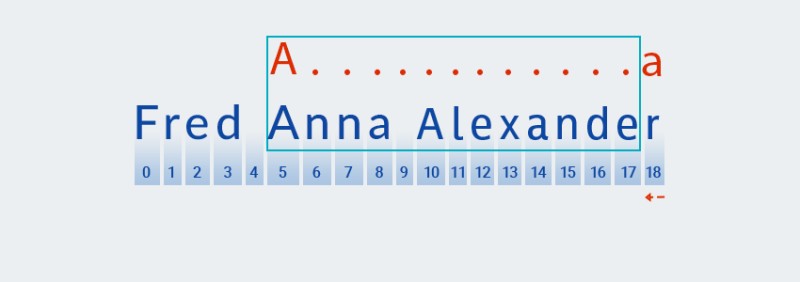
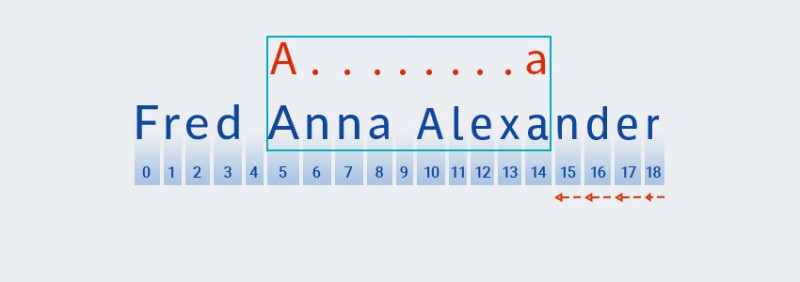
lượng từ sở hữu
Các định lượng sở hữu rất giống với những định lượng tham lam. Sự khác biệt là khi văn bản đã được bắt vào cuối chuỗi, sẽ không có mẫu khớp trong khi "lùi lại". Nói cách khác, ba giai đoạn đầu giống như đối với các bộ định lượng tham lam. Sau khi chụp toàn bộ chuỗi, trình so khớp thêm phần còn lại của mẫu vào những gì nó đang xem xét và so sánh nó với chuỗi đã chụp. Trong ví dụ của chúng tôi, sử dụng cụm từ thông dụng "A.++a", phương thức chính không tìm thấy kết quả khớp. 
định lượng miễn cưỡng
-
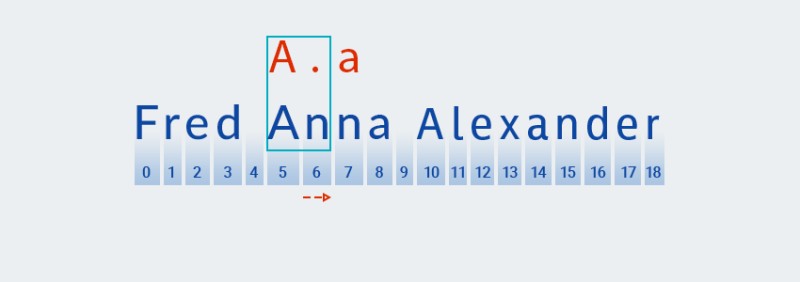
Đối với các bộ định lượng này, cũng như với sự đa dạng tham lam, mã sẽ tìm kiếm kết quả khớp dựa trên ký tự đầu tiên của mẫu:
![Biểu thức chính quy trong Java - 8]()
-
Sau đó, nó tìm kiếm sự trùng khớp với ký tự tiếp theo của mẫu (bất kỳ ký tự nào):
![Biểu thức chính quy trong Java - 9]()
-
Không giống như khớp mẫu tham lam, khớp ngắn nhất được tìm kiếm trong khớp mẫu miễn cưỡng. Điều này có nghĩa là sau khi tìm thấy kết quả khớp với ký tự thứ hai của mẫu (dấu chấm, tương ứng với ký tự ở vị trí 6 trong văn bản, hãy
Matcherkiểm tra xem văn bản có khớp với phần còn lại của mẫu hay không — ký tự "a"![Biểu thức chính quy trong Java - 10]()
-
Văn bản không khớp với mẫu (nghĩa là nó chứa ký tự "
n" ở chỉ số 7), vì vậyMatcherhãy thêm một "ký tự bất kỳ", bởi vì bộ định lượng chỉ ra một hoặc nhiều. Sau đó, nó lại so sánh mẫu với văn bản ở các vị trí từ 5 đến 8:![Biểu thức chính quy trong Java - 11]()


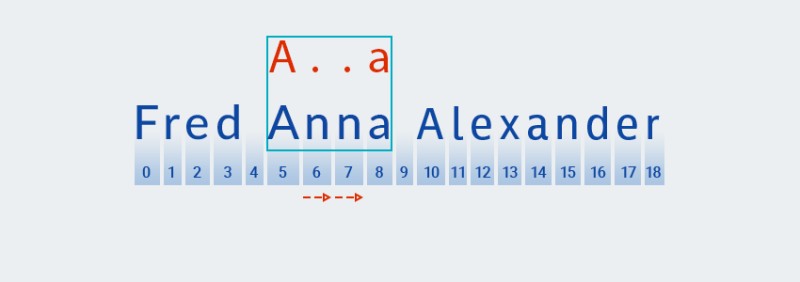
Trong trường hợp của chúng tôi, một kết quả phù hợp được tìm thấy, nhưng chúng tôi chưa đi đến cuối văn bản. Do đó, quá trình khớp mẫu bắt đầu lại từ vị trí 9, tức là ký tự đầu tiên của mẫu được tìm kiếm bằng thuật toán tương tự và điều này lặp lại cho đến hết văn bản.

mainphương pháp thu được kết quả sau khi sử dụng mẫu " A.+?a": Anna Alexa Như bạn có thể thấy từ ví dụ của chúng tôi, các loại bộ định lượng khác nhau tạo ra các kết quả khác nhau cho cùng một mẫu. Vì vậy, hãy ghi nhớ điều này và chọn loại phù hợp dựa trên những gì bạn đang tìm kiếm.
Thoát ký tự trong biểu thức chính quy
Bởi vì một biểu thức chính quy trong Java, hay đúng hơn, biểu diễn ban đầu của nó, là một chuỗi ký tự, nên chúng ta cần tính đến các quy tắc Java liên quan đến chuỗi ký tự. Cụ thể, ký tự gạch chéo ngược "\" trong chuỗi ký tự trong mã nguồn Java được hiểu là ký tự điều khiển cho trình biên dịch biết rằng ký tự tiếp theo là đặc biệt và phải được diễn giải theo cách đặc biệt. Ví dụ:
String s = "The root directory is \nWindows"; // Move "Windows" to a new line
String s = "The root directory is \u00A7Windows"; // Insert a paragraph symbol before "Windows"
\các ký tự " " (tức là để biểu thị các ký tự siêu dữ liệu) phải lặp lại các dấu gạch chéo ngược để đảm bảo rằng trình biên dịch mã byte Java không hiểu sai chuỗi. Ví dụ:
String regex = "\\s"; // Pattern for matching a whitespace character
String regex = "\"Windows\""; // Pattern for matching "Windows"
String regex = "How\\?"; // Pattern for matching "How?"
Các phương thức của lớp Pattern
Lớp nàyPatterncó các phương thức khác để làm việc với các biểu thức chính quy:
-
String pattern()- trả về biểu diễn chuỗi ban đầu của biểu thức chính quy được sử dụng để tạoPatternđối tượng:Pattern pattern = Pattern.compile("abc"); System.out.println(pattern.pattern()); // "abc" -
static boolean matches(String regex, CharSequence input)– cho phép bạn kiểm tra biểu thức chính quy được chuyển dưới dạng biểu thức chính quy so với văn bản được chuyển dưới dạnginput. Trả lại:đúng - nếu văn bản khớp với mẫu;
sai - nếu không;Ví dụ:
System.out.println(Pattern.matches("A.+a","Anna")); // true System.out.println(Pattern.matches("A.+a","Fred Anna Alexander")); // false -
int flags()– trả về giá trị củaflagsthông số đã thiết lập của mẫu khi mẫu được tạo hoặc 0 nếu thông số chưa được thiết lập. Ví dụ:Pattern pattern = Pattern.compile("abc"); System.out.println(pattern.flags()); // 0 Pattern pattern = Pattern.compile("abc",Pattern.CASE_INSENSITIVE); System.out.println(pattern.flags()); // 2 -
String[] split(CharSequence text, int limit)– chia văn bản đã truyền thành mộtStringmảng. Thamlimitsố cho biết số trận đấu tối đa được tìm kiếm trong văn bản:- nếu
limit > 0-limit-1khớp; - nếu
limit < 0- tất cả các kết quả phù hợp trong văn bản - nếu
limit = 0‒ tất cả các kết quả phù hợp trong văn bản, các chuỗi trống ở cuối mảng sẽ bị loại bỏ;
Ví dụ:
public static void main(String[] args) { String text = "Fred Anna Alexa"; Pattern pattern = Pattern.compile("\\s"); String[] strings = pattern.split(text,2); for (String s : strings) { System.out.println(s); } System.out.println("---------"); String[] strings1 = pattern.split(text); for (String s : strings1) { System.out.println(s); } }Đầu ra bảng điều khiển:
Fred Anna Alexa --------- Fred Anna AlexaDưới đây chúng ta sẽ xem xét một phương thức khác của lớp được sử dụng để tạo một
Matcherđối tượng. - nếu
Các phương thức của lớp Matcher
Các thể hiện củaMatcherlớp được tạo để thực hiện so khớp mẫu. Matcherlà "công cụ tìm kiếm" cho các biểu thức chính quy. Để thực hiện tìm kiếm, chúng ta cần cung cấp cho nó hai thứ: mẫu và chỉ mục bắt đầu. Để tạo một Matcherđối tượng, Patternlớp cung cấp phương thức sau: рublic Matcher matcher(CharSequence input) Phương thức nhận một chuỗi ký tự sẽ được tìm kiếm. Đây là một thể hiện của một lớp thực hiện CharSequencegiao diện. Bạn có thể vượt qua không chỉ a String, mà còn cả a StringBuffer, StringBuilder, Segment, hoặc CharBuffer. Mẫu là một Patternđối tượng mà matcherphương thức được gọi. Ví dụ về tạo đối sánh:
Pattern p = Pattern.compile("a*b"); // Create a compiled representation of the regular expression
Matcher m = p.matcher("aaaaab"); // Create a "search engine" to search the text "aaaaab" for the pattern "a*b"

boolean find()thức tìm kiếm kết quả khớp tiếp theo trong văn bản. Chúng ta có thể sử dụng phương pháp này và một câu lệnh lặp để phân tích toàn bộ văn bản như một phần của mô hình sự kiện. Nói cách khác, chúng ta có thể thực hiện các thao tác cần thiết khi một sự kiện xảy ra, tức là khi chúng ta tìm thấy sự phù hợp trong văn bản. Ví dụ: chúng ta có thể sử dụng các phương thức int start()và của lớp này int end()để xác định vị trí của một đối sánh trong văn bản. Và chúng ta có thể sử dụng các phương thức String replaceFirst(String replacement)và String replaceAll(String replacement)để thay thế các kết quả khớp với giá trị của tham số thay thế. Ví dụ:
public static void main(String[] args) {
String text = "Fred Anna Alexa";
Pattern pattern = Pattern.compile("A.+?a");
Matcher matcher = pattern.matcher(text);
while (matcher.find()) {
int start=matcher.start();
int end=matcher.end();
System.out.println("Match found: " + text.substring(start, end) + " from index "+ start + " through " + (end-1));
}
System.out.println(matcher.replaceFirst("Ira"));
System.out.println(matcher.replaceAll("Mary"));
System.out.println(text);
}
Match found: Anna from index 5 through 8
Match found: Alexa from index 10 through 14
Fred Ira Alexa
Fred Mary Mary
Fred Anna Alexa
replaceFirstvà replaceAlltạo một Stringđối tượng mới — một chuỗi trong đó mẫu khớp với văn bản gốc được thay thế bằng văn bản được truyền cho phương thức dưới dạng đối số. Ngoài ra, replaceFirstphương thức này chỉ thay thế kết quả khớp đầu tiên, nhưng replaceAllphương thức này sẽ thay thế tất cả các kết quả khớp trong văn bản. Văn bản gốc không thay đổi. Các hoạt động biểu thức chính quy thường xuyên nhất của lớp Patternvà Matcherđược tích hợp ngay trong Stringlớp. Đây là những phương pháp như split, matches, replaceFirst, và replaceAll. Nhưng về cơ bản, các phương thức này sử dụng các lớp Patternvà Matcher. Vì vậy, nếu bạn muốn thay thế văn bản hoặc so sánh các chuỗi trong một chương trình mà không cần viết thêm bất kỳ mã nào, hãy sử dụng các phương thức củaStringlớp học. Nếu bạn cần các tính năng nâng cao hơn, hãy nhớ các lớp Patternvà Matcher.
Phần kết luận
Trong một chương trình Java, một biểu thức chính quy được xác định bởi một chuỗi tuân theo các quy tắc khớp mẫu cụ thể. Khi thực thi mã, máy Java sẽ biên dịch chuỗi này thành mộtPatternđối tượng và sử dụng một Matcherđối tượng để tìm các kết quả khớp trong văn bản. Như tôi đã nói lúc đầu, mọi người thường bỏ qua các biểu thức chính quy để nói sau, coi chúng là một chủ đề khó. Nhưng nếu bạn hiểu cú pháp cơ bản, siêu ký tự và thoát ký tự, đồng thời nghiên cứu các ví dụ về biểu thức chính quy, thì bạn sẽ thấy chúng đơn giản hơn nhiều so với cái nhìn đầu tiên.
|
Đọc thêm: |
|---|
GO TO FULL VERSION