
एक नियमित अभिव्यक्ति (रेगेक्स) क्या है?
वास्तव में, एक रेगुलर एक्सप्रेशन पाठ में एक स्ट्रिंग खोजने के लिए एक प्रतिमान है। जावा में, इस पैटर्न का मूल प्रतिनिधित्व हमेशा एक स्ट्रिंग होता है, यानीStringक्लास का एक ऑब्जेक्ट। हालाँकि, यह कोई स्ट्रिंग नहीं है जिसे रेगुलर एक्सप्रेशन में संकलित किया जा सकता है - केवल वे स्ट्रिंग्स जो रेगुलर एक्सप्रेशन बनाने के नियमों के अनुरूप हैं। सिंटैक्स को भाषा विनिर्देश में परिभाषित किया गया है। अक्षरों और संख्याओं के साथ-साथ मेटाचैकर का उपयोग करके नियमित अभिव्यक्तियाँ लिखी जाती हैं, जो ऐसे वर्ण हैं जिनका नियमित अभिव्यक्ति सिंटैक्स में विशेष अर्थ होता है। उदाहरण के लिए:
String regex = "java"; // The pattern is "java";
String regex = "\\d{3}"; // The pattern is three digits;
जावा में नियमित अभिव्यक्ति बनाना
जावा में एक रेगुलर एक्सप्रेशन बनाने में दो सरल चरण शामिल हैं:- इसे एक स्ट्रिंग के रूप में लिखें जो रेगुलर एक्सप्रेशन सिंटैक्स का अनुपालन करता है;
- स्ट्रिंग को नियमित अभिव्यक्ति में संकलित करें;
Patternऑब्जेक्ट बनाकर काम करना शुरू करते हैं। ऐसा करने के लिए, हमें कक्षा के दो स्थिर तरीकों में से एक को कॉल करने की आवश्यकता है: compile. पहली विधि एक तर्क लेती है - एक स्ट्रिंग शाब्दिक जिसमें नियमित अभिव्यक्ति होती है, जबकि दूसरा एक अतिरिक्त तर्क लेता है जो पैटर्न-मिलान सेटिंग्स को निर्धारित करता है:
public static Pattern compile (String literal)
public static Pattern compile (String literal, int flags)
flagsमें परिभाषित की गई है Patternऔर स्थिर वर्ग चर के रूप में हमारे लिए उपलब्ध है। उदाहरण के लिए:
Pattern pattern = Pattern.compile("java", Pattern.CASE_INSENSITIVE); // Pattern-matching will be case insensitive.
Patternवर्ग नियमित अभिव्यक्ति के लिए एक निर्माता है। हुड के तहत, विधि संकलित प्रतिनिधित्व बनाने के लिए कक्षा के निजी कन्स्ट्रक्टर को compileकॉल करती है । Patternअपरिवर्तनीय वस्तुओं को बनाने के लिए इस वस्तु-निर्माण तंत्र को इस तरह कार्यान्वित किया जाता है। जब एक नियमित अभिव्यक्ति बनाई जाती है, तो इसका सिंटैक्स चेक किया जाता है। यदि स्ट्रिंग में त्रुटियां हैं, तो a PatternSyntaxExceptionउत्पन्न होता है।
रेगुलर एक्सप्रेशन सिंटैक्स
रेगुलर एक्सप्रेशन सिंटैक्स वर्णों पर निर्भर करता है<([{\^-=$!|]})?*+.>, जिसे अक्षरों के साथ जोड़ा जा सकता है। उनकी भूमिका के आधार पर, उन्हें कई समूहों में विभाजित किया जा सकता है:
| मेटाचैकर | विवरण |
|---|---|
| ^ | एक पंक्ति की शुरुआत |
| $ | एक पंक्ति का अंत |
| \बी | शब्द सीमा |
| \बी | गैर-शब्द सीमा |
| \ए | इनपुट की शुरुआत |
| \जी | पिछले मैच का अंत |
| \Z | इनपुट का अंत |
| \z | इनपुट का अंत |
| मेटाचैकर | विवरण |
|---|---|
| \डी | अंक |
| \डी | गैर-अंक |
| \एस | व्हाइटस्पेस चरित्र |
| \एस | गैर-सफ़ेद वर्ण |
| \w | अल्फ़ान्यूमेरिक वर्ण या अंडरस्कोर |
| \ डब्ल्यू | अक्षरों, संख्याओं और अंडरस्कोर को छोड़कर कोई भी वर्ण |
| . | कोई चरित्र |

| मेटाचैकर | विवरण |
|---|---|
| \टी | टैब चरित्र |
| \एन | न्यूलाइन चरित्र |
| \आर | कैरिज रिटर्न |
| \एफ | लाइनफीड चरित्र |
| \u0085 | अगली पंक्ति वर्ण |
| \u2028 | रेखा विभाजक |
| \u2029 | पैरा विभाजक |
| मेटाचैकर | विवरण |
|---|---|
| [एबीसी] | सूचीबद्ध वर्णों में से कोई भी (ए, बी, या सी) |
| [^ एबीसी] | सूचीबद्ध के अलावा कोई भी वर्ण (ए, बी, या सी नहीं) |
| [ए-जेडए-जेड] | मर्ज की गई श्रेणियां (लैटिन वर्ण a से z तक, केस असंवेदनशील) |
| [विज्ञापन [एमपी]] | वर्णों का संघ (a से d और m से p तक) |
| [az&&[डीईएफ़]] | वर्णों का प्रतिच्छेदन (डी, ई, एफ) |
| [az&&[^बीसी]] | वर्णों का घटाव (ए, डीजे) |
| मेटाचैकर | विवरण |
|---|---|
| ? | एक या कोई नहीं |
| * | शून्य या अधिक बार |
| + | एक या अधिक बार |
| {एन} | एन बार |
| {एन,} | एन या अधिक बार |
| {एन, एम} | कम से कम n बार और m से अधिक बार नहीं |
लालची क्वांटिफायर
क्वांटिफायर के बारे में आपको एक बात पता होनी चाहिए कि वे तीन अलग-अलग किस्मों में आते हैं: लालची, स्वामित्व और अनिच्छुक।+क्वांटिफायर के बाद एक "" कैरेक्टर जोड़कर आप क्वांटिफायर को अधिकारपूर्ण बनाते हैं । ?आप " " जोड़कर इसे अनिच्छुक बनाते हैं । उदाहरण के लिए:
"A.+a" // greedy
"A.++a" // possessive
"A.+?a" // reluctant
public static void main(String[] args) {
String text = "Fred Anna Alexander";
Pattern pattern = Pattern.compile("A.+a");
Matcher matcher = pattern.matcher(text);
while (matcher.find()) {
System.out.println(text.substring(matcher.start(), matcher.end()));
}
}
Anna Alexa
A.+a" के लिए, पैटर्न-मैचिंग निम्नानुसार की जाती है:
-
निर्दिष्ट पैटर्न में पहला वर्ण लैटिन अक्षर है
A।Matcherपाठ के प्रत्येक वर्ण के साथ इसकी तुलना करता है, सूचकांक शून्य से शुरू करता है। हमारे पाठ में वर्णFसूचकांक शून्य पर है, इसलिएMatcherवर्णों के माध्यम से तब तक पुनरावृत्त होता है जब तक कि यह पैटर्न से मेल नहीं खाता। हमारे उदाहरण में, यह वर्ण अनुक्रमणिका 5 पर पाया जाता है।![जावा में रेगुलर एक्सप्रेशन - 2]()
-
एक बार पैटर्न के पहले वर्ण के साथ एक मैच मिल जाने के बाद,
Matcherइसके दूसरे वर्ण के साथ एक मैच की तलाश की जाती है। हमारे मामले में, यह "." वर्ण है, जो किसी भी वर्ण का प्रतिनिधित्व करता है।![जावा में रेगुलर एक्सप्रेशन - 3]()
वर्ण
nछठे स्थान पर है। यह निश्चित रूप से "किसी भी पात्र" के लिए एक मैच के रूप में योग्य है। -
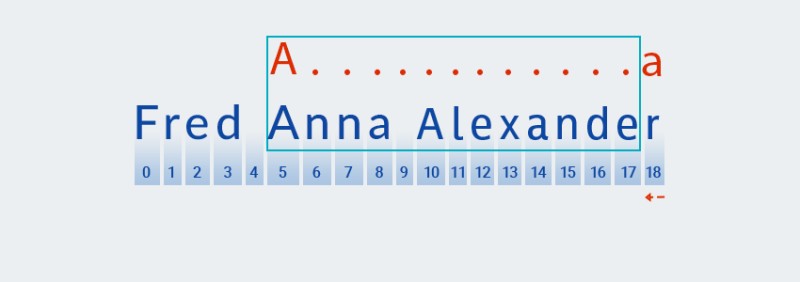
Matcherपैटर्न के अगले वर्ण की जांच करने के लिए आगे बढ़ता है। हमारे पैटर्न में, यह क्वांटिफायर में शामिल है जो पूर्ववर्ती वर्ण पर लागू होता है: ".+"। चूंकि हमारे पैटर्न में "किसी भी वर्ण" की पुनरावृत्ति की संख्या एक या अधिक बार होती है,Matcherबार-बार स्ट्रिंग से अगले वर्ण को लेता है और इसे पैटर्न के विरुद्ध तब तक जांचता है जब तक कि यह "किसी भी वर्ण" से मेल खाता हो। हमारे उदाहरण में - स्ट्रिंग के अंत तक (इंडेक्स 7 से इंडेक्स 18 तक)।![जावा में रेगुलर एक्सप्रेशन - 4]()
मूल रूप से,
Matcherस्ट्रिंग को अंत तक पकड़ता है - "लालची" का ठीक यही अर्थ है। -
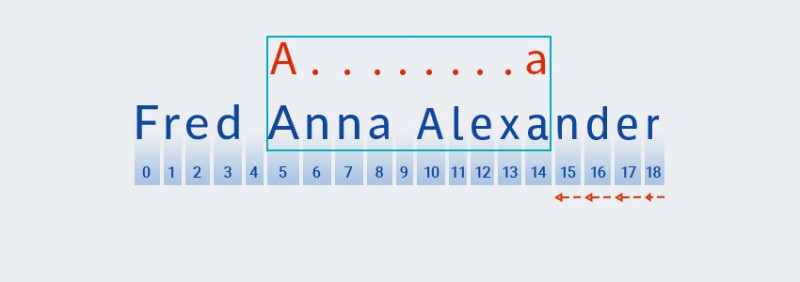
A.+जब मैचर टेक्स्ट के अंत तक पहुँच जाता है और पैटर्न के "" हिस्से की जाँच पूरी कर लेता है , तो यह बाकी पैटर्न के लिए जाँच करना शुरू कर देता है:a. आगे कोई पाठ नहीं जा रहा है, इसलिए चेक "बैक ऑफ" द्वारा आगे बढ़ता है, अंतिम वर्ण से शुरू होता है:![जावा में नियमित अभिव्यक्ति - 5]()
-
Matcher.+पैटर्न के "" भाग में दोहराव की संख्या को "याद" करता है । इस बिंदु पर, यह दोहराव की संख्या को एक से कम कर देता है और एक मैच मिलने तक टेक्स्ट के खिलाफ बड़े पैटर्न की जांच करता है:![जावा में नियमित अभिव्यक्ति - 6]()



कब्जे वाले क्वांटिफायर
स्वत्वबोधक क्वांटिफायर बहुत हद तक लालची क्वांटिफायर की तरह होते हैं। अंतर यह है कि जब पाठ स्ट्रिंग के अंत में कब्जा कर लिया गया है, तो "बैकिंग ऑफ" के दौरान कोई पैटर्न-मिलान नहीं होता है। दूसरे शब्दों में, पहले तीन चरण लालची क्वांटिफायर के समान हैं। संपूर्ण स्ट्रिंग को कैप्चर करने के बाद, मैचर शेष पैटर्न को उस चीज़ में जोड़ता है जिस पर वह विचार कर रहा है और इसकी तुलना कैप्चर की गई स्ट्रिंग से करता है। हमारे उदाहरण में, रेगुलर एक्सप्रेशन "A.++a" का उपयोग करते हुए, मुख्य विधि को कोई मिलान नहीं मिलता है। 
अनिच्छुक क्वांटिफायर
-
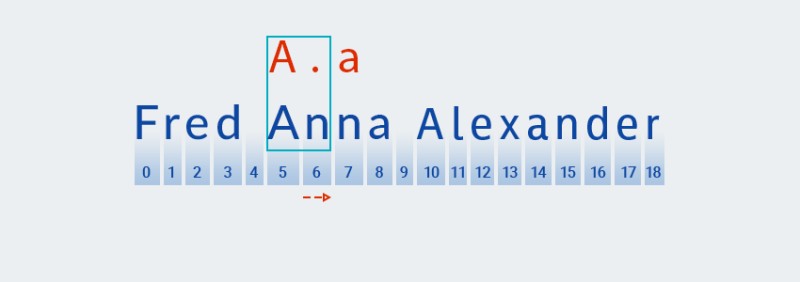
इन क्वांटिफायरों के लिए, लालची विविधता के साथ, कोड पैटर्न के पहले वर्ण के आधार पर एक मैच की तलाश करता है:
![जावा में नियमित अभिव्यक्ति - 8]()
-
फिर यह पैटर्न के अगले वर्ण (किसी भी वर्ण) के साथ मेल खाता है:
![जावा में नियमित अभिव्यक्ति - 9]()
-
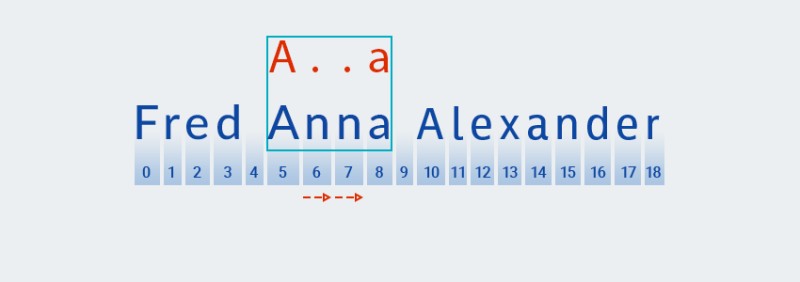
लालची पैटर्न-मिलान के विपरीत, अनिच्छुक पैटर्न-मिलान में सबसे छोटा मिलान खोजा जाता है। इसका मतलब यह है कि पैटर्न के दूसरे वर्ण (एक अवधि, जो पाठ में स्थिति 6 पर वर्ण से मेल खाती है, के साथ एक मैच खोजने के बाद, यह
Matcherजाँचता है कि क्या पाठ बाकी पैटर्न से मेल खाता है - वर्ण "a"![जावा में नियमित अभिव्यक्ति - 10]()
-
nपाठ पैटर्न से मेल नहीं खाता है (अर्थात इसमें इंडेक्स 7 पर वर्ण "" शामिल है ), इसलिएMatcherएक और "कोई वर्ण" जोड़ता है, क्योंकि क्वांटिफायर एक या अधिक इंगित करता है। फिर यह 5 से 8 की स्थिति में पाठ के साथ पैटर्न की फिर से तुलना करता है:![जावा में रेगुलर एक्सप्रेशन - 11]()


हमारे मामले में, एक मैच मिल गया है, लेकिन हम अभी तक टेक्स्ट के अंत तक नहीं पहुंचे हैं। इसलिए, पैटर्न-मिलान स्थिति 9 से फिर से शुरू होता है, यानी समान एल्गोरिथ्म का उपयोग करके पैटर्न का पहला वर्ण खोजा जाता है और यह पाठ के अंत तक दोहराता है।

mainपैटर्न " A.+?a" का उपयोग करते समय विधि निम्नलिखित परिणाम प्राप्त करती है: अन्ना एलेक्सा जैसा कि आप हमारे उदाहरण से देख सकते हैं, विभिन्न प्रकार के क्वांटिफायर एक ही पैटर्न के लिए अलग-अलग परिणाम देते हैं। इसलिए इसे ध्यान में रखें और आप जो खोज रहे हैं उसके आधार पर सही किस्म चुनें।
रेगुलर एक्सप्रेशंस में एस्केपिंग कैरेक्टर्स
क्योंकि जावा में एक नियमित अभिव्यक्ति, या बल्कि, इसका मूल प्रतिनिधित्व, एक स्ट्रिंग शाब्दिक है, हमें स्ट्रिंग शाब्दिक के संबंध में जावा नियमों को ध्यान में रखना होगा।\विशेष रूप से, जावा स्रोत कोड में स्ट्रिंग अक्षर में बैकस्लैश वर्ण " " को एक नियंत्रण वर्ण के रूप में व्याख्या किया जाता है जो संकलक को बताता है कि अगला वर्ण विशेष है और विशेष तरीके से व्याख्या की जानी चाहिए। उदाहरण के लिए:
String s = "The root directory is \nWindows"; // Move "Windows" to a new line
String s = "The root directory is \u00A7Windows"; // Insert a paragraph symbol before "Windows"
\वर्णों का उपयोग करते हैं (यानी मेटाचैकर को इंगित करने के लिए) बैकस्लैश को दोहराना चाहिए ताकि यह सुनिश्चित हो सके कि जावा बाइटकोड कंपाइलर स्ट्रिंग की गलत व्याख्या नहीं करता है। उदाहरण के लिए:
String regex = "\\s"; // Pattern for matching a whitespace character
String regex = "\"Windows\""; // Pattern for matching "Windows"
String regex = "How\\?"; // Pattern for matching "How?"
पैटर्न वर्ग के तरीके
कक्षाPatternमें रेगुलर एक्सप्रेशंस के साथ काम करने के अन्य तरीके हैं:
-
String pattern()- ऑब्जेक्ट बनाने के लिए उपयोग की जाने वाली नियमित अभिव्यक्ति का मूल स्ट्रिंग प्रतिनिधित्व लौटाता हैPattern:Pattern pattern = Pattern.compile("abc"); System.out.println(pattern.pattern()); // "abc" -
static boolean matches(String regex, CharSequence input)- आपको पास किए गए टेक्स्ट के खिलाफ रेगेक्स के रूप में पारित नियमित अभिव्यक्ति की जांच करने देता हैinput। रिटर्न:सच - अगर टेक्स्ट पैटर्न से मेल खाता है;
अगर नहीं है तो ग़लत;उदाहरण के लिए:
System.out.println(Pattern.matches("A.+a","Anna")); // true System.out.println(Pattern.matches("A.+a","Fred Anna Alexander")); // false -
int flags()- जब पैटर्न बनाया गया था तब पैटर्न के पैरामीटर सेट का मान लौटाता हैflagsया पैरामीटर सेट नहीं होने पर 0 देता है। उदाहरण के लिए:Pattern pattern = Pattern.compile("abc"); System.out.println(pattern.flags()); // 0 Pattern pattern = Pattern.compile("abc",Pattern.CASE_INSENSITIVE); System.out.println(pattern.flags()); // 2 -
String[] split(CharSequence text, int limit)- पारित पाठ को एकStringसरणी में विभाजित करता है। पैरामीटरlimitपाठ में खोजे गए मिलानों की अधिकतम संख्या इंगित करता है:- अगर
limit > 0-limit-1मेल खाता है; - अगर
limit < 0- पाठ में सभी मेल खाते हैं - यदि
limit = 0- पाठ में सभी मिलान, सरणी के अंत में खाली स्ट्रिंग्स को छोड़ दिया जाता है;
उदाहरण के लिए:
public static void main(String[] args) { String text = "Fred Anna Alexa"; Pattern pattern = Pattern.compile("\\s"); String[] strings = pattern.split(text,2); for (String s : strings) { System.out.println(s); } System.out.println("---------"); String[] strings1 = pattern.split(text); for (String s : strings1) { System.out.println(s); } }कंसोल आउटपुट:
Fred Anna Alexa --------- Fred Anna AlexaMatcherनीचे हम ऑब्जेक्ट बनाने के लिए उपयोग की जाने वाली कक्षा की अन्य विधियों पर विचार करेंगे । - अगर
मैचर वर्ग के तरीके
Matcherपैटर्न-मिलान करने के लिए कक्षा के उदाहरण बनाए जाते हैं। Matcherरेगुलर एक्सप्रेशन के लिए "खोज इंजन" है। कोई खोज करने के लिए, हमें उसे दो चीज़ें देनी होंगी: एक पैटर्न और एक प्रारंभिक अनुक्रमणिका। ऑब्जेक्ट बनाने के लिए Matcher, Patternवर्ग निम्न विधि प्रदान करता है: рublic Matcher matcher(CharSequence input) विधि एक वर्ण अनुक्रम लेती है, जिसे खोजा जाएगा। यह एक वर्ग का एक उदाहरण है जो CharSequenceइंटरफ़ेस को लागू करता है। आप न केवल a पास कर सकते हैं String, बल्कि a StringBuffer, StringBuilder,, Segmentया भी पास कर सकते हैं CharBuffer। पैटर्न एक Patternवस्तु है जिस पर matcherविधि को कहा जाता है। मैचर बनाने का उदाहरण:
Pattern p = Pattern.compile("a*b"); // Create a compiled representation of the regular expression
Matcher m = p.matcher("aaaaab"); // Create a "search engine" to search the text "aaaaab" for the pattern "a*b"

boolean find()पाठ में अगले मैच की तलाश करती है। हम एक घटना मॉडल के हिस्से के रूप में पूरे पाठ का विश्लेषण करने के लिए इस पद्धति और एक लूप स्टेटमेंट का उपयोग कर सकते हैं। दूसरे शब्दों में, जब कोई घटना घटित होती है, यानी जब हमें पाठ में कोई मेल मिलता है, तो हम आवश्यक संचालन कर सकते हैं। उदाहरण के लिए, हम टेक्स्ट में मिलान की स्थिति निर्धारित करने के लिए इस वर्ग int start()और विधियों का उपयोग कर सकते हैं। int end()और हम प्रतिस्थापन पैरामीटर के मान के साथ मिलानों को प्रतिस्थापित करने के लिए String replaceFirst(String replacement)और विधियों का उपयोग कर सकते हैं। String replaceAll(String replacement)उदाहरण के लिए:
public static void main(String[] args) {
String text = "Fred Anna Alexa";
Pattern pattern = Pattern.compile("A.+?a");
Matcher matcher = pattern.matcher(text);
while (matcher.find()) {
int start=matcher.start();
int end=matcher.end();
System.out.println("Match found: " + text.substring(start, end) + " from index "+ start + " through " + (end-1));
}
System.out.println(matcher.replaceFirst("Ira"));
System.out.println(matcher.replaceAll("Mary"));
System.out.println(text);
}
Match found: Anna from index 5 through 8
Match found: Alexa from index 10 through 14
Fred Ira Alexa
Fred Mary Mary
Fred Anna Alexa
replaceFirstऔर replaceAllविधियां एक नई Stringवस्तु बनाती हैं - एक स्ट्रिंग जिसमें मूल पाठ में पैटर्न मिलान को तर्क के रूप में विधि को पारित पाठ द्वारा प्रतिस्थापित किया जाता है। इसके अतिरिक्त, replaceFirstविधि केवल पहले मिलान को प्रतिस्थापित करती है, लेकिन replaceAllविधि पाठ में सभी मिलानों को प्रतिस्थापित करती है। मूल पाठ अपरिवर्तित रहता है। और कक्षाओं के सबसे लगातार रेगेक्स ऑपरेशन सीधे कक्षा में बनाए जाते हैं Pattern। ये तरीके हैं जैसे , , , और । लेकिन हुड के तहत, ये विधियां और कक्षाओं का उपयोग करती हैं। इसलिए यदि आप बिना कोई अतिरिक्त कोड लिखे किसी प्रोग्राम में टेक्स्ट को बदलना चाहते हैं या स्ट्रिंग्स की तुलना करना चाहते हैं, तो इसके तरीकों का उपयोग करेंMatcherStringsplitmatchesreplaceFirstreplaceAllPatternMatcherStringकक्षा। यदि आपको अधिक उन्नत सुविधाओं की आवश्यकता है, तो Patternऔर Matcherकक्षाओं को याद रखें।
निष्कर्ष
जावा प्रोग्राम में, एक नियमित अभिव्यक्ति को एक स्ट्रिंग द्वारा परिभाषित किया जाता है जो विशिष्ट पैटर्न-मिलान नियमों का पालन करता है। कोड निष्पादित करते समय, जावा मशीन इस स्ट्रिंग कोPatternऑब्जेक्ट में संकलित करती है और Matcherटेक्स्ट में मिलान खोजने के लिए ऑब्जेक्ट का उपयोग करती है। जैसा कि मैंने शुरुआत में कहा था, लोग नियमित अभिव्यक्तियों को बाद के लिए टाल देते हैं, यह देखते हुए कि यह एक कठिन विषय है। लेकिन यदि आप बुनियादी सिंटैक्स, मेटाचैकर और कैरेक्टर एस्केपिंग को समझते हैं, और रेगुलर एक्सप्रेशंस के उदाहरणों का अध्ययन करते हैं, तो आप पाएंगे कि वे पहली नज़र में दिखने की तुलना में बहुत सरल हैं।
|
अधिक पढ़ना: |
|---|
GO TO FULL VERSION