
Ce este o expresie regulată (regex)?
De fapt, o expresie regulată este un model pentru găsirea unui șir în text. În Java, reprezentarea originală a acestui model este întotdeauna un șir, adică un obiect alStringclasei. Cu toate acestea, nu este orice șir care poate fi compilat într-o expresie regulată - doar șiruri care se conformează regulilor de creare a expresiilor regulate. Sintaxa este definită în specificația limbajului. Expresiile regulate sunt scrise folosind litere și cifre, precum și metacaractere, care sunt caractere care au o semnificație specială în sintaxa expresiilor regulate. De exemplu:
String regex = "java"; // The pattern is "java";
String regex = "\\d{3}"; // The pattern is three digits;
Crearea expresiilor regulate în Java
Crearea unei expresii regulate în Java implică doi pași simpli:- scrieți-l ca șir care respectă sintaxa expresiilor regulate;
- compilați șirul într-o expresie regulată;
Patternobiect. Pentru a face acest lucru, trebuie să apelăm una dintre cele două metode statice ale clasei: compile. Prima metodă ia un argument - un literal șir care conține expresia regulată, în timp ce a doua ia un argument suplimentar care determină setările de potrivire a modelului:
public static Pattern compile (String literal)
public static Pattern compile (String literal, int flags)
flagsparametrului este definită în Patternclasă și ne este disponibilă ca variabile statice de clasă. De exemplu:
Pattern pattern = Pattern.compile("java", Pattern.CASE_INSENSITIVE); // Pattern-matching will be case insensitive.
Patternclasa este un constructor pentru expresii regulate. Sub capotă, compilemetoda apelează Patternconstructorul privat al clasei pentru a crea o reprezentare compilată. Acest mecanism de creare a obiectelor este implementat în acest fel pentru a crea obiecte imuabile. Când este creată o expresie regulată, sintaxa acesteia este verificată. Dacă șirul conține erori, atunci PatternSyntaxExceptionse generează a.
Sintaxa expresiei regulate
Sintaxa expresiilor regulate se bazează pe<([{\^-=$!|]})?*+.>caractere, care pot fi combinate cu litere. În funcție de rolul lor, acestea pot fi împărțite în mai multe grupuri:
| Metacaracter | Descriere |
|---|---|
| ^ | începutul unei linii |
| $ | capăt de linie |
| \b | limita de cuvinte |
| \B | graniță non-cuvânt |
| \A | începutul intrării |
| \G | finalul meciului precedent |
| \Z | sfârşitul intrării |
| \z | sfârşitul intrării |
| Metacaracter | Descriere |
|---|---|
| \d | cifră |
| \D | non-cifră |
| \s | caracter de spațiu alb |
| \S | caracter fără spații albe |
| \w | caracter alfanumeric sau liniuță de subliniere |
| \W | orice caracter, cu excepția literelor, numerelor și liniuței de subliniere |
| . | orice personaj |

| Metacaracter | Descriere |
|---|---|
| \t | caracterul tabulatorului |
| \n | caracter newline |
| \r | retur transport |
| \f | caracter de avans de linie |
| \u0085 | caracterul din rândul următor |
| \u2028 | separator de linii |
| \u2029 | separator de paragraf |
| Metacaracter | Descriere |
|---|---|
| [abc] | oricare dintre caracterele enumerate (a, b sau c) |
| [^abc] | orice alt caracter decât cele enumerate (nu a, b sau c) |
| [a-zA-Z] | intervale îmbinate (caractere latine de la a la z, fără diferențiere între majuscule și minuscule) |
| [anunț[mp]] | unirea caracterelor (de la a la d și de la m la p) |
| [az&&[def]] | intersecția caracterelor (d, e, f) |
| [az&&[^bc]] | scăderea caracterelor (a, dz) |
| Metacaracter | Descriere |
|---|---|
| ? | unul sau niciunul |
| * | zero sau de mai multe ori |
| + | una sau mai multe ori |
| {n} | de n ori |
| {n,} | de n sau de mai multe ori |
| {n,m} | de cel puțin n ori și de cel mult de m ori |
Cuantificatori lacomi
Un lucru pe care ar trebui să-l știți despre cuantificatori este că vin în trei soiuri diferite: lacom, posesiv și reticent. Faceți un cuantificator posesiv adăugând un+caracter „ ” după cuantificator. Îl faci reticent adăugând „ ?”. De exemplu:
"A.+a" // greedy
"A.++a" // possessive
"A.+?a" // reluctant
public static void main(String[] args) {
String text = "Fred Anna Alexander";
Pattern pattern = Pattern.compile("A.+a");
Matcher matcher = pattern.matcher(text);
while (matcher.find()) {
System.out.println(text.substring(matcher.start(), matcher.end()));
}
}
Anna Alexa
A.+a", potrivirea modelului se realizează după cum urmează:
-
Primul caracter din modelul specificat este litera latină
A.Matcherîl compară cu fiecare caracter al textului, începând de la indicele zero. CaracterulFse află la indexul zero în textul nostru, așa căMatcheriterează prin caractere până când se potrivește cu modelul. În exemplul nostru, acest caracter se găsește la indexul 5.![Expresii regulate în Java - 2]()
-
Odată ce este găsită o potrivire cu primul caracter al modelului,
Matchercaută o potrivire cu al doilea caracter al acestuia. În cazul nostru, este.caracterul " ", care reprezintă orice caracter.![Expresii regulate în Java - 3]()
Personajul
nse află pe poziţia a şasea. Cu siguranță se califică ca o potrivire pentru „orice personaj”. -
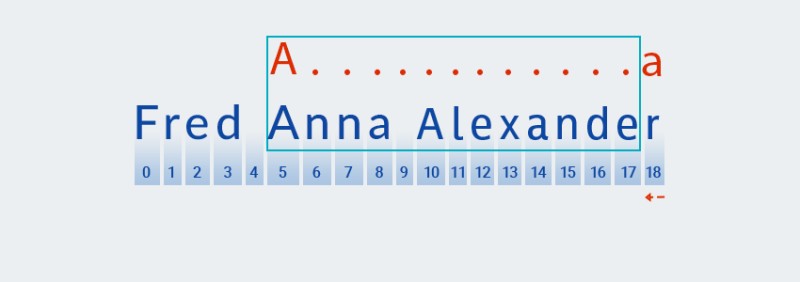
Matchercontinuă să verifice următorul caracter al modelului. În modelul nostru, este inclus în cuantificatorul care se aplică caracterului precedent: ".+". Deoarece numărul de repetări ale „orice caracter” din modelul nostru este de una sau mai multe ori,Matcheria în mod repetat următorul caracter din șir și îl verifică cu modelul atâta timp cât se potrivește cu „orice caracter”. În exemplul nostru — până la sfârșitul șirului (de la indexul 7 la indexul 18).![Expresii regulate în Java - 4]()
Practic,
Matcherînghite șirul până la capăt - tocmai asta se înțelege prin „lacom”. -
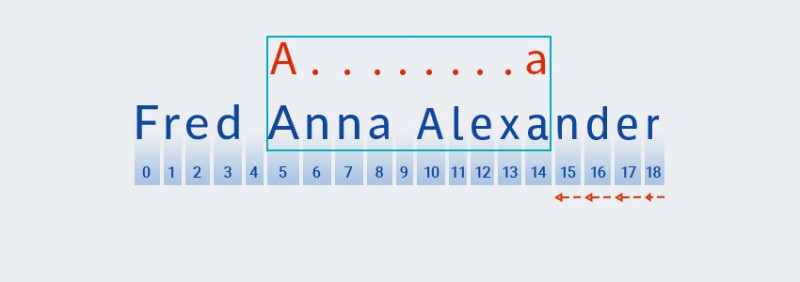
După ce Matcher ajunge la sfârșitul textului și termină verificarea pentru
A.+partea „ ” a modelului, începe să verifice restul modelului:a. Nu mai există text în continuare, așa că verificarea continuă prin „întoarcere”, începând de la ultimul caracter:![Expresii regulate în Java - 5]()
-
Matcher„își amintește” numărul de repetări din.+partea „ ” a modelului. În acest moment, reduce numărul de repetări cu una și verifică modelul mai mare cu textul până când se găsește o potrivire:![Expresii regulate în Java - 6]()



Cuantificatori posesivi
Cuantificatorii posesivi seamănă mult cu cei lacomi. Diferența este că atunci când textul a fost capturat până la sfârșitul șirului, nu există nicio potrivire a modelului în timp ce „retrai”. Cu alte cuvinte, primele trei etape sunt aceleași ca pentru cuantificatorii lacomi. După capturarea întregului șir, potrivitorul adaugă restul modelului la ceea ce are în vedere și îl compară cu șirul capturat. În exemplul nostru, folosind expresia regulată "A.++a", metoda principală nu găsește nicio potrivire. 
Cuantificatoare reticente
-
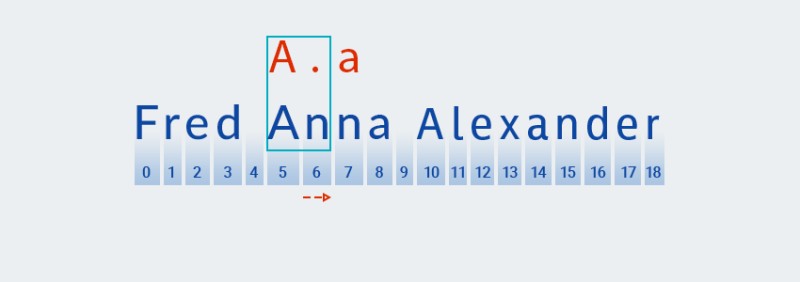
Pentru acești cuantificatori, ca și în cazul varietății lacomi, codul caută o potrivire bazată pe primul caracter al modelului:
![Expresii regulate în Java - 8]()
-
Apoi caută o potrivire cu următorul caracter al modelului (orice caracter):
![Expresii regulate în Java - 9]()
-
Spre deosebire de potrivirea lacomă de modele, cea mai scurtă potrivire este căutată în potrivirea de modele reticente. Aceasta înseamnă că după găsirea unei potriviri cu al doilea caracter al modelului (o punct, care corespunde caracterului de la poziția 6 din text,
Matcherverifică dacă textul se potrivește cu restul modelului - caracterul "a"![Expresii regulate în Java - 10]()
-
Textul nu se potrivește cu modelul (adică conține caracterul „
n” la indexul 7), așa căMatcheradaugă mai multe „orice caracter”, deoarece cuantificatorul indică unul sau mai multe. Apoi compară din nou modelul cu textul din pozițiile 5 până la 8:![Expresii regulate în Java - 11]()


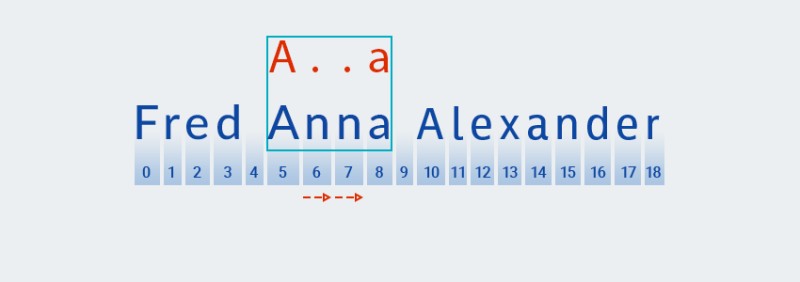
În cazul nostru, se găsește o potrivire, dar încă nu am ajuns la sfârșitul textului. Prin urmare, potrivirea modelului repornește din poziția 9, adică primul caracter al modelului este căutat folosind un algoritm similar și acesta se repetă până la sfârșitul textului.

mainmetoda obține următorul rezultat când se folosește modelul " A.+?a": Anna Alexa După cum puteți vedea din exemplul nostru, diferite tipuri de cuantificatoare produc rezultate diferite pentru același model. Așa că țineți cont de acest lucru și alegeți varietatea potrivită în funcție de ceea ce căutați.
Escape de caractere în expresiile regulate
Deoarece o expresie regulată în Java, sau mai degrabă, reprezentarea sa originală, este un șir literal, trebuie să luăm în considerare regulile Java cu privire la literalele șir. În special, caracterul backslash „\” din literalele șir din codul sursă Java este interpretat ca un caracter de control care îi spune compilatorului că următorul caracter este special și trebuie interpretat într-un mod special. De exemplu:
String s = "The root directory is \nWindows"; // Move "Windows" to a new line
String s = "The root directory is \u00A7Windows"; // Insert a paragraph symbol before "Windows"
\caractere " " (adică pentru a indica metacaracterele) trebuie să repete barele oblice inverse pentru a se asigura că compilatorul Java bytecode nu interpretează greșit șirul. De exemplu:
String regex = "\\s"; // Pattern for matching a whitespace character
String regex = "\"Windows\""; // Pattern for matching "Windows"
String regex = "How\\?"; // Pattern for matching "How?"
Metode ale clasei Pattern
ClasaPatternare alte metode de lucru cu expresii regulate:
-
String pattern()‒ returnează reprezentarea originală a șirului expresiei regulate, utilizată pentru a crea obiectulPattern:Pattern pattern = Pattern.compile("abc"); System.out.println(pattern.pattern()); // "abc" -
static boolean matches(String regex, CharSequence input)– vă permite să verificați expresia regulată transmisă ca regex față de textul transmis cainput. Se intoarce:true – dacă textul se potrivește cu modelul;
fals – dacă nu;De exemplu:
System.out.println(Pattern.matches("A.+a","Anna")); // true System.out.println(Pattern.matches("A.+a","Fred Anna Alexander")); // false -
int flags()‒ returnează valoareaflagssetului de parametri ai modelului când modelul a fost creat sau 0 dacă parametrul nu a fost setat. De exemplu:Pattern pattern = Pattern.compile("abc"); System.out.println(pattern.flags()); // 0 Pattern pattern = Pattern.compile("abc",Pattern.CASE_INSENSITIVE); System.out.println(pattern.flags()); // 2 -
String[] split(CharSequence text, int limit)– împarte textul transmis într-oStringmatrice. Parametrullimitindică numărul maxim de potriviri căutate în text:- dacă
limit > 0‒limit-1se potrivește; - dacă
limit < 0‒ toate se potrivesc în text - dacă
limit = 0‒ toate se potrivesc în text, șirurile goale de la sfârșitul matricei sunt aruncate;
De exemplu:
public static void main(String[] args) { String text = "Fred Anna Alexa"; Pattern pattern = Pattern.compile("\\s"); String[] strings = pattern.split(text,2); for (String s : strings) { System.out.println(s); } System.out.println("---------"); String[] strings1 = pattern.split(text); for (String s : strings1) { System.out.println(s); } }Ieșire din consolă:
Fred Anna Alexa --------- Fred Anna AlexaMai jos vom lua în considerare o altă dintre metodele clasei utilizate pentru a crea un
Matcherobiect. - dacă
Metode ale clasei Matcher
Instanțele claseiMatchersunt create pentru a efectua potrivirea modelelor. Matchereste „motorul de căutare” pentru expresiile regulate. Pentru a efectua o căutare, trebuie să îi dăm două lucruri: un model și un index de pornire. Pentru a crea un Matcherobiect, Patternclasa oferă următoarea metodă: рublic Matcher matcher(CharSequence input) Metoda ia o secvență de caractere, care va fi căutată. Aceasta este o instanță a unei clase care implementează CharSequenceinterfața. Puteți trece nu numai un String, ci și un StringBuffer, StringBuilder, Segment, sau CharBuffer. Modelul este un Patternobiect pe care matchereste apelată metoda. Exemplu de creare a unui potrivire:

Pattern p = Pattern.compile("a*b"); // Create a compiled representation of the regular expression
Matcher m = p.matcher("aaaaab"); // Create a "search engine" to search the text "aaaaab" for the pattern "a*b"
boolean find()caută următoarea potrivire în text. Putem folosi această metodă și o instrucțiune buclă pentru a analiza un text întreg ca parte a unui model de eveniment. Cu alte cuvinte, putem efectua operațiunile necesare atunci când are loc un eveniment, adică atunci când găsim o potrivire în text. De exemplu, putem folosi aceste clase int start()și int end()metode pentru a determina poziția unei potriviri în text. Și putem folosi metodele String replaceFirst(String replacement)și String replaceAll(String replacement)pentru a înlocui potrivirile cu valoarea parametrului de înlocuire. De exemplu:
public static void main(String[] args) {
String text = "Fred Anna Alexa";
Pattern pattern = Pattern.compile("A.+?a");
Matcher matcher = pattern.matcher(text);
while (matcher.find()) {
int start=matcher.start();
int end=matcher.end();
System.out.println("Match found: " + text.substring(start, end) + " from index "+ start + " through " + (end-1));
}
System.out.println(matcher.replaceFirst("Ira"));
System.out.println(matcher.replaceAll("Mary"));
System.out.println(text);
}
Match found: Anna from index 5 through 8
Match found: Alexa from index 10 through 14
Fred Ira Alexa
Fred Mary Mary
Fred Anna Alexa
replaceFirstși replaceAllcreează un nou Stringobiect - un șir în care potrivirile de model din textul original sunt înlocuite cu textul transmis metodei ca argument. În plus, replaceFirstmetoda înlocuiește doar prima potrivire, dar replaceAllmetoda înlocuiește toate potrivirile din text. Textul original rămâne neschimbat. Cele mai frecvente operațiuni regex ale claselor Patternși Matchersunt integrate chiar în Stringclasă. Acestea sunt metode precum split, matches, replaceFirstși replaceAll. Dar sub capotă, aceste metode folosesc clasele Patternși Matcher. Deci, dacă doriți să înlocuiți text sau să comparați șiruri de caractere într-un program fără a scrie niciun cod suplimentar, utilizați metodeleStringclasă. Dacă aveți nevoie de funcții mai avansate, amintiți-vă cursurile Patternși Matcher.
Concluzie
Într-un program Java, o expresie regulată este definită de un șir care respectă reguli specifice de potrivire a modelelor. La executarea codului, mașina Java compilează acest șir într-unPatternobiect și folosește un Matcherobiect pentru a găsi potriviri în text. După cum am spus la început, oamenii deseori amână expresiile obișnuite pentru mai târziu, considerându-le un subiect dificil. Dar dacă înțelegeți sintaxa de bază, metacaracterele și evadarea caracterelor și studiați exemple de expresii regulate, atunci veți descoperi că sunt mult mai simple decât par la prima vedere.
|
Mai multe lecturi: |
|---|
GO TO FULL VERSION