
Hvad er et regulært udtryk (regex)?
Faktisk er et regulært udtryk et mønster til at finde en streng i tekst. I Java er den oprindelige repræsentation af dette mønster altid en streng, altså et objekt i klassenString. Det er dog ikke en hvilken som helst streng, der kan kompileres til et regulært udtryk - kun strenge, der overholder reglerne for at skabe regulære udtryk. Syntaksen er defineret i sprogspecifikationen. Regulære udtryk skrives ved hjælp af bogstaver og tal samt metategn, som er tegn, der har særlig betydning i regulære udtrykssyntaks. For eksempel:
String regex = "java"; // The pattern is "java";
String regex = "\\d{3}"; // The pattern is three digits;
Oprettelse af regulære udtryk i Java
Oprettelse af et regulært udtryk i Java involverer to enkle trin:- skriv det som en streng, der overholder regulære udtryks syntaks;
- kompiler strengen til et regulært udtryk;
Patternobjekt. For at gøre dette skal vi kalde en af klassens to statiske metoder: compile. Den første metode tager et argument - en streng-literal, der indeholder det regulære udtryk, mens den anden tager et ekstra argument, der bestemmer indstillingerne for mønstertilpasning:
public static Pattern compile (String literal)
public static Pattern compile (String literal, int flags)
flagsparameteren er defineret i Patternklasse og er tilgængelig for os som statiske klassevariable. For eksempel:
Pattern pattern = Pattern.compile("java", Pattern.CASE_INSENSITIVE); // Pattern-matching will be case insensitive.
Patterner klassen en konstruktør for regulære udtryk. Under hætten compilekalder metoden Patternklassens private konstruktør for at skabe en kompileret repræsentation. Denne objektskabelsesmekanisme er implementeret på denne måde for at skabe uforanderlige objekter. Når et regulært udtryk oprettes, kontrolleres dets syntaks. Hvis strengen indeholder fejl, PatternSyntaxExceptiongenereres a.
Syntaks for regulære udtryk
Syntaks for regulære udtryk afhænger af<([{\^-=$!|]})?*+.>tegnene, som kan kombineres med bogstaver. Afhængigt af deres rolle kan de opdeles i flere grupper:
| Metakarakter | Beskrivelse |
|---|---|
| ^ | begyndelsen af en linje |
| $ | slutningen af en linje |
| \b | ordgrænse |
| \B | ikke-ord grænse |
| \EN | begyndelsen af input |
| \G | slutningen af den forrige kamp |
| \Z | slutningen af input |
| \z | slutningen af input |
| Metakarakter | Beskrivelse |
|---|---|
| \d | ciffer |
| \D | ikke-cifret |
| \s | blanktegn |
| \S | tegn uden mellemrum |
| \w | alfanumerisk tegn eller understregning |
| \W | ethvert tegn undtagen bogstaver, tal og understregning |
| . | enhver karakter |

| Metakarakter | Beskrivelse |
|---|---|
| \t | tabulatortegn |
| \n | nylinjekarakter |
| \r | vogn retur |
| \f | linefeed karakter |
| \u0085 | næste linje tegn |
| \u2028 | linjeadskiller |
| \u2029 | afsnitsadskiller |
| Metakarakter | Beskrivelse |
|---|---|
| [abc] | nogen af de angivne tegn (a, b eller c) |
| [^abc] | ethvert tegn ud over de angivne (ikke a, b eller c) |
| [a-zA-Z] | flettede områder (latinske tegn fra a til z, ufølsom mellem store og små bogstaver) |
| [annonce[mp]] | forening af tegn (fra a til d og fra m til p) |
| [az&&[def]] | skæringspunkt mellem tegn (d, e, f) |
| [az&&[^bc]] | subtraktion af tegn (a, dz) |
| Metakarakter | Beskrivelse |
|---|---|
| ? | en eller ingen |
| * | nul eller flere gange |
| + | en eller flere gange |
| {n} | n gange |
| {n,} | n eller flere gange |
| {n,m} | mindst n gange og ikke mere end m gange |
Grådige kvantificerere
En ting du bør vide om kvantificerere er, at de findes i tre forskellige varianter: grådige, besiddende og tilbageholdende. Du gør en kvantifier besiddende ved at tilføje et "+"-tegn efter kvantifieren. Du gør det tilbageholdende ved at tilføje " ?". For eksempel:
"A.+a" // greedy
"A.++a" // possessive
"A.+?a" // reluctant
public static void main(String[] args) {
String text = "Fred Anna Alexander";
Pattern pattern = Pattern.compile("A.+a");
Matcher matcher = pattern.matcher(text);
while (matcher.find()) {
System.out.println(text.substring(matcher.start(), matcher.end()));
}
}
Anna Alexa
A.+a" udføres mønstertilpasning som følger:
-
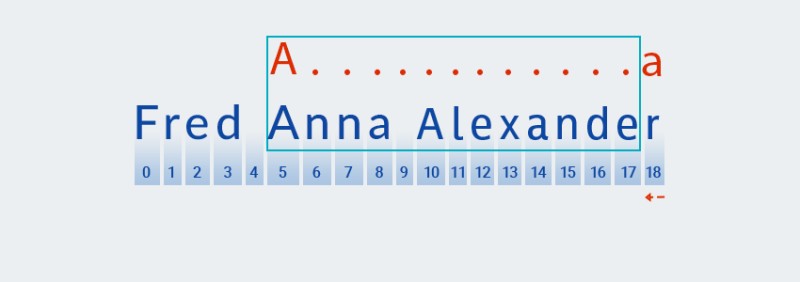
Det første tegn i det angivne mønster er det latinske bogstav
A.Matchersammenligner det med hvert tegn i teksten, startende fra indeks nul. TegnetFer ved indeks nul i vores tekst, såMatcherdet går gennem tegnene, indtil det matcher mønsteret. I vores eksempel findes denne karakter ved indeks 5.![Regulære udtryk i Java - 2]()
-
Når et match med mønsterets første karakter er fundet,
Matchersøger du efter et match med dets andet tegn. I vores tilfælde er det.tegnet " ", som står for et hvilket som helst tegn.![Regulære udtryk i Java - 3]()
Karakteren
ner i sjette position. Det kvalificerer sig bestemt som et match for "enhver karakter". -
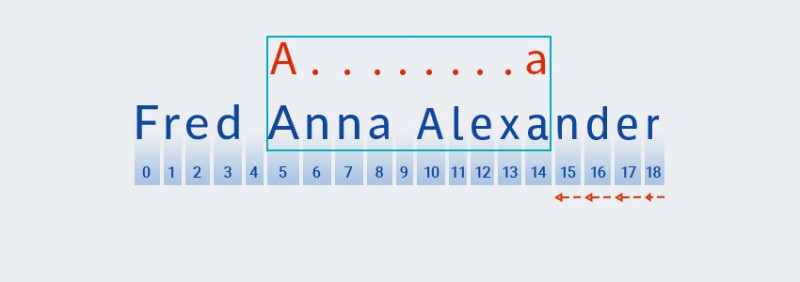
Matcherfortsætter med at kontrollere det næste tegn i mønsteret. I vores mønster er det inkluderet i kvantifieren, der gælder for det foregående tegn: ".+". Fordi antallet af gentagelser af "ethvert tegn" i vores mønster er en eller flere gange,Matchertager gentagne gange det næste tegn fra strengen og tjekker det mod mønsteret, så længe det matcher "et hvilket som helst tegn". I vores eksempel — indtil slutningen af strengen (fra indeks 7 til indeks 18).![Regulære udtryk i Java - 4]()
Dybest set
Matchersluger strengen til enden - det er præcis, hvad der menes med "grådig". -
Når Matcher når slutningen af teksten og afslutter kontrollen for "
A.+"-delen af mønsteret, begynder den at tjekke for resten af mønsteret:a. Der er ikke mere tekst fremadrettet, så kontrollen fortsætter med at "gå tilbage", begyndende fra det sidste tegn:![Regulære udtryk i Java - 5]()
-
Matcher"husker" antallet af gentagelser i ".+"-delen af mønsteret. På dette tidspunkt reducerer den antallet af gentagelser med én og kontrollerer det større mønster i forhold til teksten, indtil der er fundet et match:![Regulære udtryk i Java - 6]()



Besiddende kvantificatorer
Besiddende kvantificerere er meget som grådige. Forskellen er, at når teksten er blevet fanget til slutningen af strengen, er der ingen mønster-matching, mens "back off". Med andre ord er de tre første stadier de samme som for grådige kvantificerere. Efter at have fanget hele strengen, tilføjer matcheren resten af mønsteret til det, den overvejer, og sammenligner det med den fangede streng. I vores eksempel, ved at bruge det regulære udtryk "A.++a", finder hovedmetoden ingen overensstemmelse. 
Modvillige kvantificerere
-
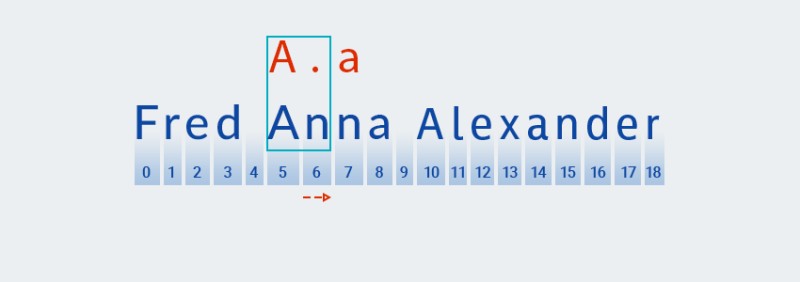
For disse kvantificerere, som med den grådige variant, leder koden efter et match baseret på det første tegn i mønsteret:
![Regulære udtryk i Java - 8]()
-
Derefter leder den efter et match med mønsterets næste tegn (enhver tegn):
![Regulære udtryk i Java - 9]()
-
I modsætning til grådig mønster-matchning, søges det korteste match i tilbageholdende mønster-matching. Det betyder, at efter at have fundet et match med mønsterets andet tegn (et punktum, som svarer til tegnet på position 6 i teksten,
Matcherkontrollerer det, om teksten matcher resten af mønsteret — tegnet "a"![Regulære udtryk i Java - 10]()
-
Teksten stemmer ikke overens med mønsteret (dvs. den indeholder tegnet "
n" ved indeks 7), såMatchertilføjer mere et "ethvert tegn", fordi kvantifieren angiver en eller flere. Derefter sammenligner den igen mønsteret med teksten i position 5 til 8:![Regulære udtryk i Java - 11]()


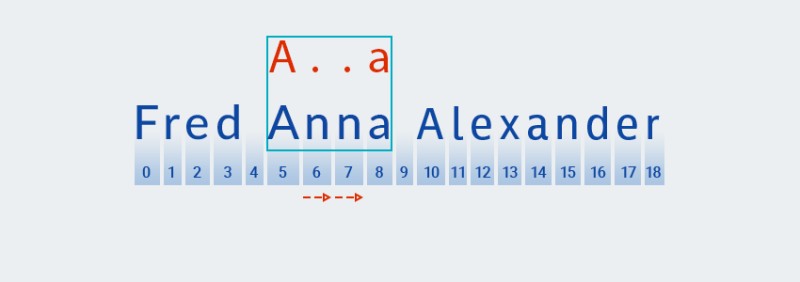
I vores tilfælde er der fundet et match, men vi er ikke nået til slutningen af teksten endnu. Derfor genstarter mønstertilpasningen fra position 9, dvs. mønsterets første tegn søges ved hjælp af en lignende algoritme, og denne gentages indtil slutningen af teksten.

mainopnår metoden følgende resultat, når A.+?adu bruger mønsteret " ": Anna Alexa Som du kan se fra vores eksempel, producerer forskellige typer kvantificerere forskellige resultater for det samme mønster. Så husk dette og vælg den rigtige variant baseret på, hvad du leder efter.
Undslippende tegn i regulære udtryk
Fordi et regulært udtryk i Java, eller rettere sagt, dets oprindelige repræsentation, er en streng-literal, skal vi tage højde for Java-regler vedrørende streng-literals. Især\tolkes backslash-tegnet " " i strengliteraler i Java-kildekoden som et kontroltegn, der fortæller compileren, at det næste tegn er specielt og skal fortolkes på en speciel måde. For eksempel:
String s = "The root directory is \nWindows"; // Move "Windows" to a new line
String s = "The root directory is \u00A7Windows"; // Insert a paragraph symbol before "Windows"
\"-tegn (dvs. for at angive metategn), skal gentage omvendte skråstreg for at sikre, at Java-bytekode-kompileren ikke misfortolker strengen. For eksempel:
String regex = "\\s"; // Pattern for matching a whitespace character
String regex = "\"Windows\""; // Pattern for matching "Windows"
String regex = "How\\?"; // Pattern for matching "How?"
Metoder i mønsterklassen
KlassenPatternhar andre metoder til at arbejde med regulære udtryk:
-
String pattern()‒ returnerer det regulære udtryks oprindelige strengrepræsentation, der blev brugt til at oprette objektetPattern:Pattern pattern = Pattern.compile("abc"); System.out.println(pattern.pattern()); // "abc" -
static boolean matches(String regex, CharSequence input)– lader dig kontrollere det regulære udtryk, der sendes som regex, i forhold til teksten, der sendes sominput. Vender tilbage:sand – hvis teksten matcher mønsteret;
falsk – hvis det ikke gør det;For eksempel:
System.out.println(Pattern.matches("A.+a","Anna")); // true System.out.println(Pattern.matches("A.+a","Fred Anna Alexander")); // false -
int flags()‒ returnerer værdien af mønsteretsflagsparametersæt, da mønsteret blev oprettet, eller 0, hvis parameteren ikke blev indstillet. For eksempel:Pattern pattern = Pattern.compile("abc"); System.out.println(pattern.flags()); // 0 Pattern pattern = Pattern.compile("abc",Pattern.CASE_INSENSITIVE); System.out.println(pattern.flags()); // 2 -
String[] split(CharSequence text, int limit)– opdeler den overførte tekst i etStringarray. Parameterenlimitangiver det maksimale antal matches, der søges efter i teksten:- hvis
limit > 0‒limit-1matcher; - hvis
limit < 0‒ alle matcher i teksten - hvis
limit = 0‒ alle matcher i teksten, kasseres tomme strenge i slutningen af arrayet;
For eksempel:
public static void main(String[] args) { String text = "Fred Anna Alexa"; Pattern pattern = Pattern.compile("\\s"); String[] strings = pattern.split(text,2); for (String s : strings) { System.out.println(s); } System.out.println("---------"); String[] strings1 = pattern.split(text); for (String s : strings1) { System.out.println(s); } }Konsoludgang:
Fred Anna Alexa --------- Fred Anna AlexaNedenfor vil vi overveje en anden af klassens metoder, der bruges til at skabe et
Matcherobjekt. - hvis
Metoder i Matcher-klassen
Forekomster afMatcherklassen oprettes for at udføre mønstermatchning. Matcherer "søgemaskinen" for regulære udtryk. For at udføre en søgning skal vi give den to ting: et mønster og et startindeks. For at oprette et Matcherobjekt Patterngiver klassen følgende metode: рublic Matcher matcher(CharSequence input) Metoden tager en tegnsekvens, som vil blive søgt. Dette er en forekomst af en klasse, der implementerer grænsefladen CharSequence. Du kan ikke kun bestå et String, men også et StringBuffer, StringBuilder, Segment, eller CharBuffer. Mønsteret er et Patternobjekt, som matchermetoden kaldes på. Eksempel på oprettelse af en matcher:
Pattern p = Pattern.compile("a*b"); // Create a compiled representation of the regular expression
Matcher m = p.matcher("aaaaab"); // Create a "search engine" to search the text "aaaaab" for the pattern "a*b"

boolean find()leder efter næste match i teksten. Vi kan bruge denne metode og en loop-sætning til at analysere en hel tekst som en del af en hændelsesmodel. Med andre ord kan vi udføre nødvendige operationer, når en hændelse indtræffer, altså når vi finder et match i teksten. For eksempel kan vi bruge denne klasses int start()og int end()metoder til at bestemme en kamps position i teksten. Og vi kan bruge metoderne String replaceFirst(String replacement)og String replaceAll(String replacement)til at erstatte matches med værdien af erstatningsparameteren. For eksempel:
public static void main(String[] args) {
String text = "Fred Anna Alexa";
Pattern pattern = Pattern.compile("A.+?a");
Matcher matcher = pattern.matcher(text);
while (matcher.find()) {
int start=matcher.start();
int end=matcher.end();
System.out.println("Match found: " + text.substring(start, end) + " from index "+ start + " through " + (end-1));
}
System.out.println(matcher.replaceFirst("Ira"));
System.out.println(matcher.replaceAll("Mary"));
System.out.println(text);
}
Match found: Anna from index 5 through 8
Match found: Alexa from index 10 through 14
Fred Ira Alexa
Fred Mary Mary
Fred Anna Alexa
replaceFirstog replaceAllskaber et nyt Stringobjekt - en streng, hvor mønstermatches i den originale tekst erstattes af teksten, der sendes til metoden som et argument. Derudover replaceFirsterstatter metoden kun det første match, men replaceAllmetoden erstatter alle matchene i teksten. Den originale tekst forbliver uændret. Klassernes Patternog Matcherklassernes hyppigste regex-operationer er indbygget direkte i Stringklassen. Det er metoder som split, matches, replaceFirst, og replaceAll. Men under motorhjelmen bruger disse metoder klasserne Patternog Matcher. Så hvis du vil erstatte tekst eller sammenligne strenge i et program uden at skrive nogen ekstra kode, skal du bruge metoderne iStringklasse. Hvis du har brug for mere avancerede funktioner, så husk klasserne Patternog Matcher.
Konklusion
I et Java-program er et regulært udtryk defineret af en streng, der adlyder specifikke mønstertilpasningsregler. Når kode udføres, kompilerer Java-maskinen denne streng til etPatternobjekt og bruger et Matcherobjekt til at finde matches i teksten. Som jeg sagde i begyndelsen, udskyder folk ofte regulære udtryk til senere, da de betragter dem som et vanskeligt emne. Men hvis du forstår den grundlæggende syntaks, metakarakterer og karakterudslip og studerer eksempler på regulære udtryk, så vil du opdage, at de er meget enklere, end de ser ud ved første øjekast.
|
Mere læsning: |
|---|
GO TO FULL VERSION