
正規表現(regex)とは何ですか?
実際、正規表現はテキスト内の文字列を検索するためのパターンです。Java では、このパターンの元の表現は常に文字列、つまりクラスのオブジェクトですString。ただし、正規表現にコンパイルできる文字列はありません。正規表現を作成するための規則に準拠した文字列のみです。構文は言語仕様で定義されています。正規表現は、文字と数字に加えて、正規表現構文で特別な意味を持つ文字であるメタキャラクターを使用して記述されます。例えば:
String regex = "java"; // The pattern is "java";
String regex = "\\d{3}"; // The pattern is three digits;
Java での正規表現の作成
Java で正規表現を作成するには、次の 2 つの簡単な手順を実行します。- 正規表現構文に準拠した文字列として書き込みます。
- 文字列を正規表現にコンパイルします。
Pattern。これを行うには、クラスの 2 つの静的メソッドのいずれかを呼び出す必要がありますcompile。最初のメソッドは 1 つの引数 (正規表現を含む文字列リテラル) を受け取りますが、2 番目のメソッドはパターン マッチング設定を決定する追加の引数を受け取ります。
public static Pattern compile (String literal)
public static Pattern compile (String literal, int flags)
flagsで定義されPattern、静的クラス変数として使用できます。例えば:
Pattern pattern = Pattern.compile("java", Pattern.CASE_INSENSITIVE); // Pattern-matching will be case insensitive.
Patternクラスは正規表現のコンストラクターです。内部では、compileメソッドはクラスのプライベート コンストラクターを呼び出してPattern、コンパイルされた表現を作成します。このオブジェクト作成メカニズムは、不変オブジェクトを作成するためにこのように実装されています。正規表現が作成されると、その構文がチェックされます。文字列にエラーが含まれている場合は、 がPatternSyntaxException生成されます。
正規表現の構文
正規表現の構文は<([{\^-=$!|]})?*+.>文字に依存しており、文字と組み合わせることができます。役割に応じて、いくつかのグループに分類できます。
| メタキャラクター | 説明 |
|---|---|
| ^ | 行の先頭 |
| $ | 行の終わり |
| \b | 単語の境界 |
| \B | 非単語境界 |
| \A | 入力の始まり |
| \G | 前の試合の終わり |
| \Z | 入力の終わり |
| \z | 入力の終わり |
| メタキャラクター | 説明 |
|---|---|
| \d | 桁 |
| \D | 数字以外の |
| \s | 空白文字 |
| \S | 空白以外の文字 |
| \w | 英数字またはアンダースコア |
| \W | 文字、数字、アンダースコアを除く任意の文字 |
| 。 | 任意の文字 |
| メタキャラクター | 説明 |
|---|---|
| \t | タブ文字 |
| \n | 改行文字 |
| \r | キャリッジリターン |
| \f | 改行文字 |
| \u0085 | 次の行の文字 |
| \u2028 | 行区切り文字 |
| \u2029 | 段落区切り文字 |
| メタキャラクター | 説明 |
|---|---|
| [ABC] | リストされている文字のいずれか (a、b、または c) |
| [^abc] | リストされているもの以外の文字 (a、b、c ではない) |
| [a-zA-Z] | マージされた範囲 (a から z までのラテン文字、大文字と小文字は区別されません) |
| [広告[mp]] | 文字の結合 (a から d および m から p) |
| [az&&[def]] | 文字の交差 (d、e、f) |
| [az&&[^bc]] | 文字の減算 (a、dz) |

| メタキャラクター | 説明 |
|---|---|
| ? | 1 つまたは何もない |
| * | 0回以上 |
| + | 1回以上 |
| {n} | n回 |
| {n,} | n回以上 |
| {n,m} | 少なくとも n 回、最大 m 回 |
貪欲な数量指定子
数量詞について知っておくべきことの 1 つは、数量詞には貪欲、所有欲、消極の 3 つの異なる種類があるということです。量指定子を所有格にするには、量指定子の後に「 」文字を追加します+。「 」を付けると消極的になります?。例えば:
"A.+a" // greedy
"A.++a" // possessive
"A.+?a" // reluctant
public static void main(String[] args) {
String text = "Fred Anna Alexander";
Pattern pattern = Pattern.compile("A.+a");
Matcher matcher = pattern.matcher(text);
while (matcher.find()) {
System.out.println(text.substring(matcher.start(), matcher.end()));
}
}
Anna Alexa
A.+a」の場合、パターン マッチングは次のように実行されます。
-
指定されたパターンの最初の文字はラテン文字です
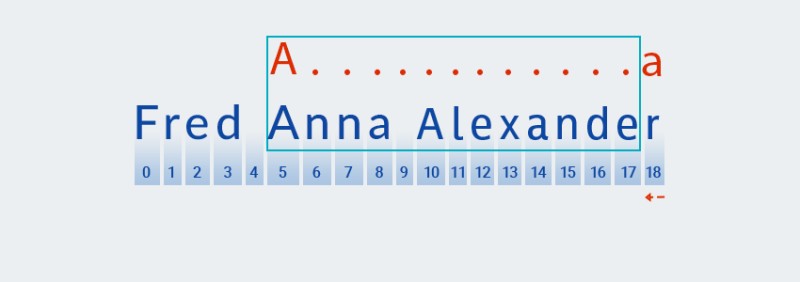
A。Matcherそれをインデックス 0 から開始してテキストの各文字と比較します。この文字はFテキストのインデックス 0 にあるため、Matcherパターンと一致するまで文字を反復処理します。この例では、この文字はインデックス 5 にあります。![Java の正規表現 - 2]()
-
パターンの最初の文字との一致が見つかると、
Matcher2 番目の文字との一致を探します。この場合、それは「.」文字であり、任意の文字を表します。![Java の正規表現 - 3]()
キャラクターは
n6番目の位置にあります。確かに「任意の文字」に一致します。 -
Matcherパターンの次の文字のチェックに進みます。このパターンでは、前の文字「.+」に適用される数量詞に含まれています。パターン内の「任意の文字」の繰り返し回数は 1 回以上であるため、Matcher「任意の文字」と一致する限り、文字列から次の文字を繰り返し取得してパターンと照合します。この例では、文字列の終わりまで (インデックス 7 からインデックス 18)。![Java の正規表現 - 4]()
基本的に、
Matcher文字列を最後まで飲み込みます。これがまさに「貪欲」という意味です。 -
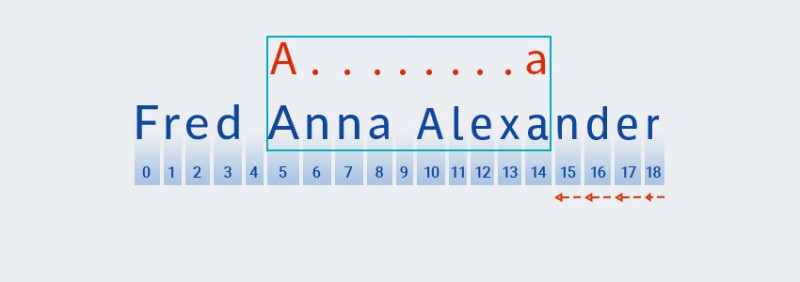
Matcher がテキストの末尾に到達し、パターンの " " 部分のチェックを終了すると
A.+、パターンの残りの部分のチェックを開始しますa。これ以上先に進むテキストはないため、チェックは最後の文字から開始して「後退」して続行されます。![Java の正規表現 - 5]()
-
Matcher.+パターンの「 」部分の繰り返し回数を「記憶」します。この時点で、繰り返しの数を 1 つ減らし、一致するものが見つかるまで、より大きなパターンをテキストに対してチェックします。![Java の正規表現 - 6]()



所有量指定子
所有量指定子は貪欲量指定子とよく似ています。違いは、テキストが文字列の最後までキャプチャされている場合、「後退」中にパターン マッチングが行われないことです。つまり、最初の 3 つの段階は欲張り数量指定子の場合と同じです。文字列全体をキャプチャした後、マッチャーはパターンの残りの部分を検討対象に追加し、キャプチャした文字列と比較します。この例では、正規表現 "A.++a" を使用すると、main メソッドは一致を見つけません。 
消極的な数量指定子
-
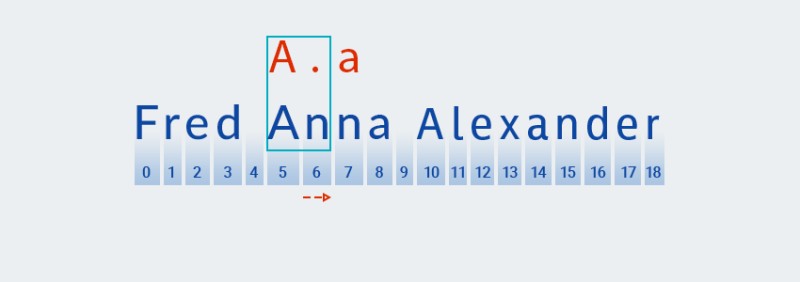
これらの量指定子の場合、貪欲多様体の場合と同様に、コードはパターンの最初の文字に基づいて一致を探します。
![Java の正規表現 - 8]()
-
次に、パターンの次の文字 (任意の文字) との一致を検索します。
![Java の正規表現 - 9]()
-
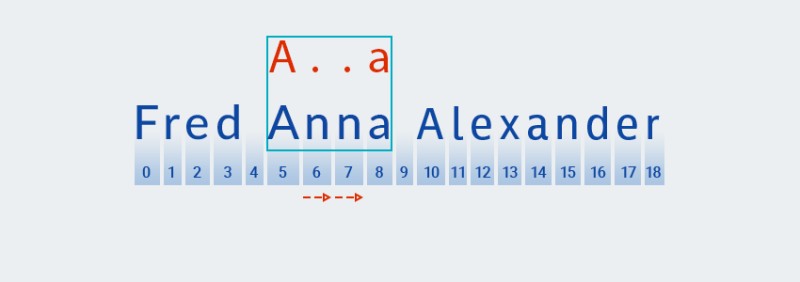
貪欲なパターン マッチングとは異なり、消極的パターン マッチングでは最短の一致が検索されます。これは、パターンの 2 番目の文字 (テキストの位置 6 の文字に対応するピリオド) との一致が見つかった後、
Matcherテキストがパターンの残りの文字 (文字 "a")と一致するかどうかをチェックすることを意味します。![Java の正規表現 - 10]()
-
テキストはパターンと一致しない (つまり、インデックス 7 に文字 "
n" が含まれている) ため、Matcher量指定子が 1 つ以上を示すため、「任意の文字」をさらに 1 つ追加します。次に、パターンと位置 5 ~ 8 のテキストが再度比較されます。![Java の正規表現 - 11]()


この場合、一致は見つかりましたが、まだテキストの終わりに到達していません。したがって、パターン マッチングは位置 9 から再開されます。つまり、同様のアルゴリズムを使用してパターンの最初の文字が検索され、これがテキストの終わりまで繰り返されます。

mainパターン " A.+?a" を使用すると、メソッドは次の結果を取得します。 Anna Alexa この例からわかるように、量指定子の種類が異なると、同じパターンでも異なる結果が生成されます。したがって、これを念頭に置いて、探しているものに基づいて適切な品種を選択してください。
正規表現内の文字のエスケープ
Java の正規表現、つまりその元の表現は文字列リテラルであるため、文字列リテラルに関する Java の規則を考慮する必要があります。特に、\Java ソース コードの文字列リテラル内のバックスラッシュ文字 " " は、次の文字が特別であり、特別な方法で解釈する必要があることをコンパイラに伝える制御文字として解釈されます。例えば:
String s = "The root directory is \nWindows"; // Move "Windows" to a new line
String s = "The root directory is \u00A7Windows"; // Insert a paragraph symbol before "Windows"
\" 文字を使用する文字列リテラル (つまり、メタキャラクターを示す) では、Java バイトコード コンパイラが文字列を誤って解釈しないように、バックスラッシュを繰り返す必要があることを意味します。例えば:
String regex = "\\s"; // Pattern for matching a whitespace character
String regex = "\"Windows\""; // Pattern for matching "Windows"
String regex = "How\\?"; // Pattern for matching "How?"
Pattern クラスのメソッド
このPatternクラスには、正規表現を操作するための他のメソッドがあります。
-
String pattern()- オブジェクトの作成に使用された正規表現の元の文字列表現を返しますPattern。Pattern pattern = Pattern.compile("abc"); System.out.println(pattern.pattern()); // "abc" -
static boolean matches(String regex, CharSequence input)– regex として渡された正規表現を、 として渡されたテキストと照合してチェックできますinput。戻り値:true – テキストがパターンに一致する場合。
false - そうでない場合。例えば:
System.out.println(Pattern.matches("A.+a","Anna")); // true System.out.println(Pattern.matches("A.+a","Fred Anna Alexander")); // false -
int flags()- パターンの作成時に設定されたパターンのパラメータの値を返しますflags。パラメータが設定されていない場合は 0 を返します。例えば:Pattern pattern = Pattern.compile("abc"); System.out.println(pattern.flags()); // 0 Pattern pattern = Pattern.compile("abc",Pattern.CASE_INSENSITIVE); System.out.println(pattern.flags()); // 2 -
String[] split(CharSequence text, int limit)– 渡されたテキストをString配列に分割します。このlimitパラメータは、テキスト内で検索される一致の最大数を示します。- if
limit > 0‒limit-1が一致する場合。 - if
limit < 0– テキスト内のすべてが一致する場合 - テキスト内のすべてが一致する場合
limit = 0、配列の末尾の空の文字列は破棄されます。
例えば:
public static void main(String[] args) { String text = "Fred Anna Alexa"; Pattern pattern = Pattern.compile("\\s"); String[] strings = pattern.split(text,2); for (String s : strings) { System.out.println(s); } System.out.println("---------"); String[] strings1 = pattern.split(text); for (String s : strings1) { System.out.println(s); } }コンソール出力:
Fred Anna Alexa --------- Fred Anna Alexa以下では、オブジェクトの作成に使用されるクラスの別のメソッドを検討します
Matcher。 - if
Matcher クラスのメソッド
クラスのインスタンスは、Matcherパターン マッチングを実行するために作成されます。Matcher正規表現の「検索エンジン」です。検索を実行するには、パターンと開始インデックスの 2 つを指定する必要があります。オブジェクトを作成するためにMatcher、Patternクラスは次のメソッドを提供します。 рublic Matcher matcher(CharSequence input) このメソッドは、検索される文字シーケンスを受け取ります。これは、インターフェイスを実装するクラスのインスタンスですCharSequence。だけでなく、、、、、または も渡すことStringができます。パターンは、メソッドが呼び出されるオブジェクトです。マッチャーの作成例: StringBufferStringBuilderSegmentCharBufferPatternmatcher
Pattern p = Pattern.compile("a*b"); // Create a compiled representation of the regular expression
Matcher m = p.matcher("aaaaab"); // Create a "search engine" to search the text "aaaaab" for the pattern "a*b"
boolean find()メソッドはテキスト内で次の一致を検索します。このメソッドとループ ステートメントを使用して、テキスト全体をイベント モデルの一部として分析できます。言い換えれば、イベントが発生したとき、つまりテキスト内で一致が見つかったときに、必要な操作を実行できます。たとえば、このクラスint start()とint end()メソッドを使用して、テキスト内の一致箇所の位置を決定できます。また、String replaceFirst(String replacement)およびString replaceAll(String replacement)メソッドを使用して、一致を置換パラメータの値に置き換えることができます。例えば:

public static void main(String[] args) {
String text = "Fred Anna Alexa";
Pattern pattern = Pattern.compile("A.+?a");
Matcher matcher = pattern.matcher(text);
while (matcher.find()) {
int start=matcher.start();
int end=matcher.end();
System.out.println("Match found: " + text.substring(start, end) + " from index "+ start + " through " + (end-1));
}
System.out.println(matcher.replaceFirst("Ira"));
System.out.println(matcher.replaceAll("Mary"));
System.out.println(text);
}
Match found: Anna from index 5 through 8
Match found: Alexa from index 10 through 14
Fred Ira Alexa
Fred Mary Mary
Fred Anna Alexa
replaceFirstこの例では、およびreplaceAllメソッドが新しいオブジェクトを作成する ことを明確にしていますString。つまり、元のテキスト内のパターンが一致する文字列が、引数としてメソッドに渡されたテキストに置き換えられます。さらに、このreplaceFirstメソッドは最初の一致のみを置換しますが、replaceAllテキスト内のすべての一致を置き換えます。元のテキストは変更されません。およびクラスの最も頻繁に使用PatternさMatcherれる正規表現操作は、クラスに直接組み込まれていますString。split、matches、replaceFirst、 などのメソッドですreplaceAll。ただし、内部では、これらのメソッドはPatternおよびMatcherクラスを使用します。したがって、追加のコードを記述せずにプログラム内のテキストを置換したり文字列を比較したりする場合は、次のメソッドを使用します。Stringクラス。より高度な機能が必要な場合は、PatternとMatcherクラスを覚えておいてください。
結論
Java プログラムでは、正規表現は、特定のパターン マッチング ルールに従う文字列によって定義されます。コードを実行するとき、Java マシンはこの文字列をオブジェクトにコンパイルしPattern、そのMatcherオブジェクトを使用してテキスト内の一致を検索します。冒頭で述べたように、正規表現は難しいテーマであると考えて、後回しにしてしまうことがよくあります。ただし、基本的な構文、メタキャラクター、文字エスケープを理解し、正規表現の例を学習すれば、それらが一見したよりもはるかに単純であることがわかるでしょう。
|
さらに読む: |
|---|
GO TO FULL VERSION